---
title: Leveraging Flower and Docker for Device Heterogeneity Management in FL
tags: [deployment, vision, tutorial]
dataset: [CIFAR-10]
framework: [Docker, tensorflow]
---
# Leveraging Flower and Docker for Device Heterogeneity Management in Federated Learning
[ ](https://github.com/adap/flower/blob/main/examples/flower-via-docker-compose)
](https://github.com/adap/flower/blob/main/examples/flower-via-docker-compose)


## Introduction
In this example, we tackle device heterogeneity in federated learning, arising from differences in memory and CPU capabilities across devices. This diversity affects training efficiency and inclusivity. Our strategy includes simulating this heterogeneity by setting CPU and memory limits in a Docker setup, using a custom Docker compose generator script. This approach creates a varied training environment and enables us to develop strategies to manage these disparities effectively.
## Handling Device Heterogeneity
1. **System Metrics Access**:
- Effective management of device heterogeneity begins with monitoring system metrics of each container. We integrate the following services to achieve this:
- **Cadvisor**: Collects comprehensive metrics from each Docker container.
- **Prometheus**: Using `prometheus.yaml` for configuration, it scrapes data from Cadvisor at scheduled intervals, serving as a robust time-series database. Users can access the Prometheus UI at `http://localhost:9090` to create and run queries using PromQL, allowing for detailed insight into container performance.
2. **Mitigating Heterogeneity**:
- In this basic use case, we address device heterogeneity by establishing rules tailored to each container's system capabilities. This involves modifying training parameters, such as batch sizes and learning rates, based on each device's memory capacity and CPU availability. These settings are specified in the `client_configs` array in the `create_docker_compose` script. For example:
```python
client_configs = [
{"mem_limit": "3g", "batch_size": 32, "cpus": 4, "learning_rate": 0.001},
{"mem_limit": "6g", "batch_size": 256, "cpus": 1, "learning_rate": 0.05},
{"mem_limit": "4g", "batch_size": 64, "cpus": 3, "learning_rate": 0.02},
{"mem_limit": "5g", "batch_size": 128, "cpus": 2.5, "learning_rate": 0.09},
]
```
## Prerequisites
Docker must be installed and the Docker daemon running on your server. If you don't already have Docker installed, you can get [installation instructions for your specific Linux distribution or macOS from Docker](https://docs.docker.com/engine/install/). Besides Docker, the only extra requirement is having Python installed. You don't need to create a new environment for this example since all dependencies will be installed inside Docker containers automatically.
## Running the Example
Running this example is easy. For a more detailed step-by-step guide, including more useful material, refer to the detailed guide in the following section.
```bash
# Generate docker compose file
python helpers/generate_docker_compose.py # by default will configure to use 2 clients for 100 rounds
# Build docker images
docker-compose build
# Launch everything
docker-compose up
```
On your favourite browser, go to `http://localhost:3000` to see the Graphana dashboard showing system-level and application-level metrics.
To stop all containers, open a new terminal and `cd` into this directory, then run `docker-compose down`. Alternatively, you can do `ctrl+c` on the same terminal and then run `docker-compose down` to ensure everything is terminated.
## Running the Example (detailed)
### Step 1: Configure Docker Compose
Execute the following command to run the `helpers/generate_docker_compose.py` script. This script creates the docker-compose configuration needed to set up the environment.
```bash
python helpers/generate_docker_compose.py
```
Within the script, specify the number of clients (`total_clients`) and resource limitations for each client in the `client_configs` array. You can adjust the number of rounds by passing `--num_rounds` to the above command.
### Step 2: Build and Launch Containers
1. **Execute Initialization Script**:
- To build the Docker images and start the containers, use the following command:
```bash
# this is the only command you need to execute to run the entire example
docker-compose up
```
- If you make any changes to the Dockerfile or other configuration files, you should rebuild the images to reflect these changes. This can be done by adding the `--build` flag to the command:
```bash
docker-compose up --build
```
- The `--build` flag instructs Docker Compose to rebuild the images before starting the containers, ensuring that any code or configuration changes are included.
- To stop all services, you have two options:
- Run `docker-compose down` in another terminal if you are in the same directory. This command will stop and remove the containers, networks, and volumes created by `docker-compose up`.
- Press `Ctrl+C` once in the terminal where `docker-compose up` is running. This will stop the containers but won't remove them or the networks and volumes they use.
2. **Services Startup**:
- Several services will automatically launch as defined in your `docker-compose.yml` file:
- **Monitoring Services**: Prometheus for metrics collection, Cadvisor for container monitoring, and Grafana for data visualization.
- **Flower Federated Learning Environment**: The Flower server and client containers are initialized and start running.
- After launching the services, verify that all Docker containers are running correctly by executing the `docker ps` command. Here's an example output:
```bash
➜ ~ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
9f05820eba45 flower-via-docker-compose-client2 "python client.py --…" 50 seconds ago Up 48 seconds 0.0.0.0:6002->6002/tcp client2
a0333715d504 flower-via-docker-compose-client1 "python client.py --…" 50 seconds ago Up 48 seconds 0.0.0.0:6001->6001/tcp client1
0da2bf735965 flower-via-docker-compose-server "python server.py --…" 50 seconds ago Up 48 seconds 0.0.0.0:6000->6000/tcp, 0.0.0.0:8000->8000/tcp, 0.0.0.0:8265->8265/tcp server
c57ef50657ae grafana/grafana:latest "/run.sh --config=/e…" 50 seconds ago Up 49 seconds 0.0.0.0:3000->3000/tcp grafana
4f274c2083dc prom/prometheus:latest "/bin/prometheus --c…" 50 seconds ago Up 49 seconds 0.0.0.0:9090->9090/tcp prometheus
e9f4c9644a1c gcr.io/cadvisor/cadvisor:v0.47.0 "/usr/bin/cadvisor -…" 50 seconds ago Up 49 seconds 0.0.0.0:8080->8080/tcp cadvisor
```
- To monitor the resource utilization of your containers in real-time and see the limits imposed in the Docker Compose file, you can use the `docker stats` command. This command provides a live stream of container CPU, memory, and network usage statistics.
```bash
➜ ~ docker stats
CONTAINER ID NAME CPU % MEM USAGE / LIMIT MEM % NET I/O BLOCK I/O PIDS
9f05820eba45 client2 104.44% 1.968GiB / 6GiB 32.80% 148MB / 3.22MB 0B / 284MB 82
a0333715d504 client1 184.69% 1.498GiB / 3GiB 49.92% 149MB / 2.81MB 1.37MB / 284MB 82
0da2bf735965 server 0.12% 218.5MiB / 15.61GiB 1.37% 1.47MB / 2.89MB 2.56MB / 2.81MB 45
c57ef50657ae grafana 0.24% 96.19MiB / 400MiB 24.05% 18.9kB / 3.79kB 77.8kB / 152kB 20
4f274c2083dc prometheus 1.14% 52.73MiB / 500MiB 10.55% 6.79MB / 211kB 1.02MB / 1.31MB 15
e9f4c9644a1c cadvisor 7.31% 32.14MiB / 500MiB 6.43% 139kB / 6.66MB 500kB / 0B 18
```
3. **Automated Grafana Configuration**:
- Grafana is configured to load pre-defined data sources and dashboards for immediate monitoring, facilitated by provisioning files. The provisioning files include `prometheus-datasource.yml` for data sources, located in the `./config/provisioning/datasources` directory, and `dashboard_index.json` for dashboards, in the `./config/provisioning/dashboards` directory. The `grafana.ini` file is also tailored to enhance user experience:
- **Admin Credentials**: We provide default admin credentials in the `grafana.ini` configuration, which simplifies access by eliminating the need for users to go through the initial login process.
- **Default Dashboard Path**: A default dashboard path is set in `grafana.ini` to ensure that the dashboard with all the necessary panels is rendered when Grafana is accessed.
These files and settings are directly mounted into the Grafana container via Docker Compose volume mappings. This setup guarantees that upon startup, Grafana is pre-configured for monitoring, requiring no additional manual setup.
4. **Begin Training Process**:
- The federated learning training automatically begins once all client containers are successfully connected to the Flower server. This synchronizes the learning process across all participating clients.
By following these steps, you will have a fully functional federated learning environment with device heterogeneity and monitoring capabilities.
## Model Training and Dataset Integration
### Data Pipeline with FLWR-Datasets
We have integrated [`flwr-datasets`](https://flower.ai/docs/datasets/) into our data pipeline, which is managed within the `load_data.py` file in the `helpers/` directory. This script facilitates standardized access to datasets across the federated network and incorporates a `data_sampling_percentage` argument. This argument allows users to specify the percentage of the dataset to be used for training and evaluation, accommodating devices with lower memory capabilities to prevent Out-of-Memory (OOM) errors.
### Model Selection and Dataset
For the federated learning system, we have selected the MobileNet model due to its efficiency in image classification tasks. The model is trained and evaluated on the CIFAR-10 dataset. The combination of MobileNet and CIFAR-10 is ideal for demonstrating the capabilities of our federated learning solution in a heterogeneous device environment.
- **MobileNet**: A streamlined architecture for mobile and embedded devices that balances performance and computational cost.
- **CIFAR-10 Dataset**: A standard benchmark dataset for image classification, containing various object classes that pose a comprehensive challenge for the learning model.
By integrating these components, our framework is well-prepared to handle the intricacies of training over a distributed network with varying device capabilities and data availability.
## Visualizing with Grafana
### Access Grafana Dashboard
Visit `http://localhost:3000` to enter Grafana. The automated setup ensures that you're greeted with a series of pre-configured dashboards, including the default screen with a comprehensive set of graphs. These dashboards are ready for immediate monitoring and can be customized to suit your specific requirements.
### Dashboard Configuration
The `dashboard_index.json` file, located in the `./config/provisioning/dashboards` directory, serves as the backbone of our Grafana dashboard's configuration. It defines the structure and settings of the dashboard panels, which are rendered when you access Grafana. This JSON file contains the specifications for various panels such as model accuracy, CPU usage, memory utilization, and network traffic. Each panel's configuration includes the data source, queries, visualization type, and other display settings like thresholds and colors.
For instance, in our project setup, the `dashboard_index.json` configures a panel to display the model's accuracy over time using a time-series graph, and another panel to show the CPU usage across clients using a graph that plots data points as they are received. This file is fundamental for creating a customized and informative dashboard that provides a snapshot of the federated learning system's health and performance metrics.
By modifying the `dashboard_index.json` file, users can tailor the Grafana dashboard to include additional metrics or change the appearance and behavior of existing panels to better fit their monitoring requirements.
### Grafana Default Dashboard
Below is the default Grafana dashboard that users will see upon accessing Grafana:
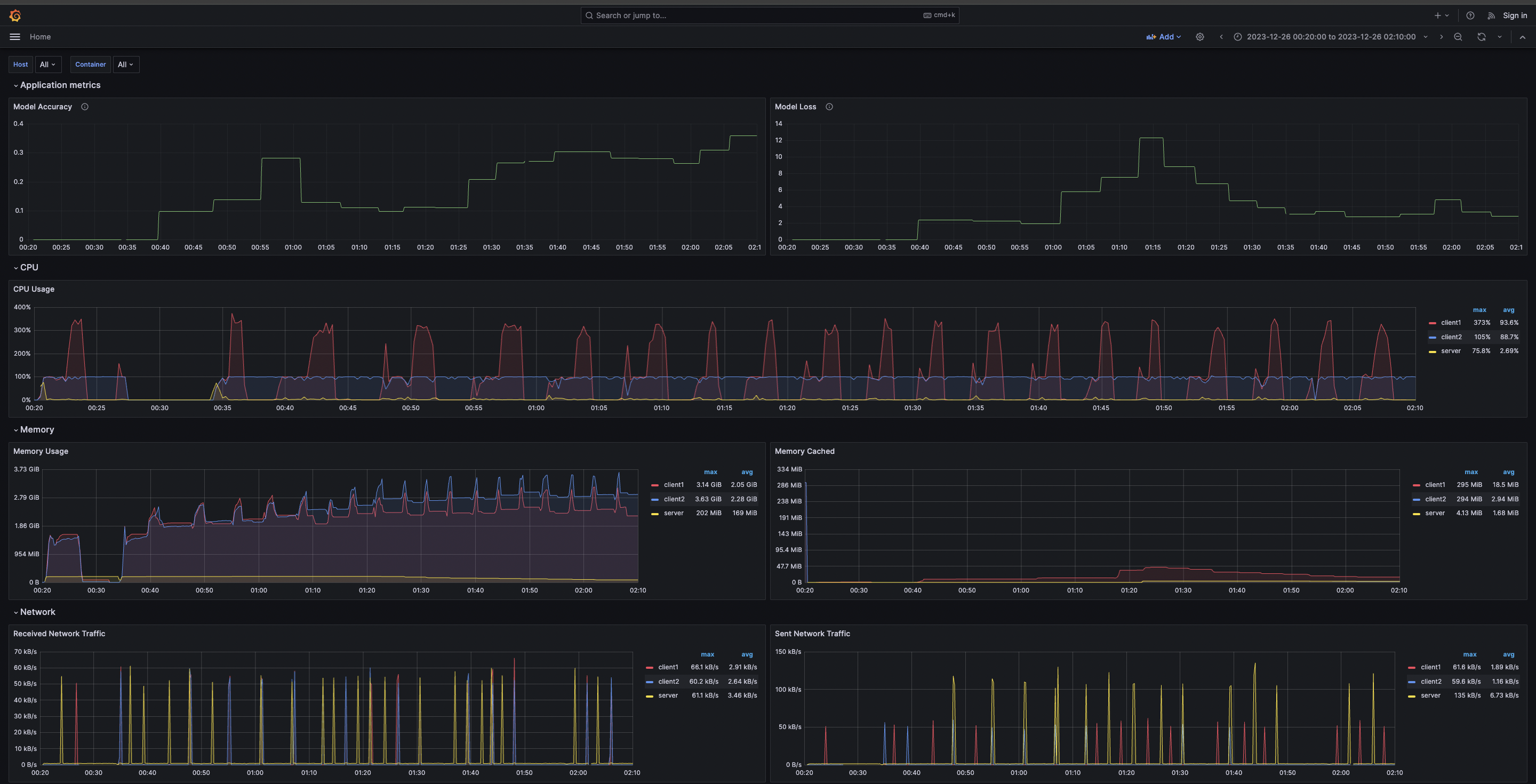 This comprehensive dashboard provides insights into various system metrics across client-server containers. It includes visualizations such as:
- **Application Metrics**: The "Model Accuracy" graph shows an upward trend as rounds of training progress, which is a positive indicator of the model learning and improving over time. Conversely, the "Model Loss" graph trends downward, suggesting that the model is becoming more precise and making fewer mistakes as it trains.
- **CPU Usage**: The sharp spikes in the red graph, representing "client1", indicate peak CPU usage, which is considerably higher than that of "client2" (blue graph). This difference is due to "client1" being allocated more computing resources (up to 4 CPU cores) compared to "client2", which is limited to just 1 CPU core, hence the more subdued CPU usage pattern.
- **Memory Utilization**: Both clients are allocated a similar amount of memory, reflected in the nearly same lines for memory usage. This uniform allocation allows for a straightforward comparison of how each client manages memory under similar conditions.
- **Network Traffic**: Monitor incoming and outgoing network traffic to each client, which is crucial for understanding data exchange volumes during federated learning cycles.
Together, these metrics paint a detailed picture of the federated learning operation, showcasing resource usage and model performance. Such insights are invaluable for system optimization, ensuring balanced load distribution and efficient model training.
## Comprehensive Monitoring System Integration
### Capturing Container Metrics with cAdvisor
cAdvisor is seamlessly integrated into our monitoring setup to capture a variety of system and container metrics, such as CPU, memory, and network usage. These metrics are vital for analyzing the performance and resource consumption of the containers in the federated learning environment.
### Custom Metrics: Setup and Monitoring via Prometheus
In addition to the standard metrics captured by cAdvisor, we have implemented a process to track custom metrics like model's accuracy and loss within Grafana, using Prometheus as the backbone for metric collection.
1. **Prometheus Client Installation**:
- We began by installing the `prometheus_client` library in our Python environment, enabling us to define and expose custom metrics that Prometheus can scrape.
2. **Defining Metrics in Server Script**:
- Within our `server.py` script, we have established two key Prometheus Gauge metrics, specifically tailored for monitoring our federated learning model: `model_accuracy` and `model_loss`. These custom gauges are instrumental in capturing the most recent values of the model's accuracy and loss, which are essential metrics for evaluating the model's performance. The gauges are defined as follows:
```python
from prometheus_client import Gauge
accuracy_gauge = Gauge('model_accuracy', 'Current accuracy of the global model')
loss_gauge = Gauge('model_loss', 'Current loss of the global model')
```
3. **Exposing Metrics via HTTP Endpoint**:
- We leveraged the `start_http_server` function from the `prometheus_client` library to launch an HTTP server on port 8000. This server provides the `/metrics` endpoint, where the custom metrics are accessible for Prometheus scraping. The function is called at the end of the `main` method in `server.py`:
```python
start_http_server(8000)
```
4. **Updating Metrics Recording Strategy**:
- The core of our metrics tracking lies in the `strategy.py` file, particularly within the `aggregate_evaluate` method. This method is crucial as it's where the federated learning model's accuracy and loss values are computed after each round of training with the aggregated data from all clients.
```python
self.accuracy_gauge.set(accuracy_aggregated)
self.loss_gauge.set(loss_aggregated)
```
5. **Configuring Prometheus Scraping**:
- In the `prometheus.yml` file, under `scrape_configs`, we configured a new job to scrape the custom metrics from the HTTP server. This setup includes the job's name, the scraping interval, and the target server's URL.
### Visualizing the Monitoring Architecture
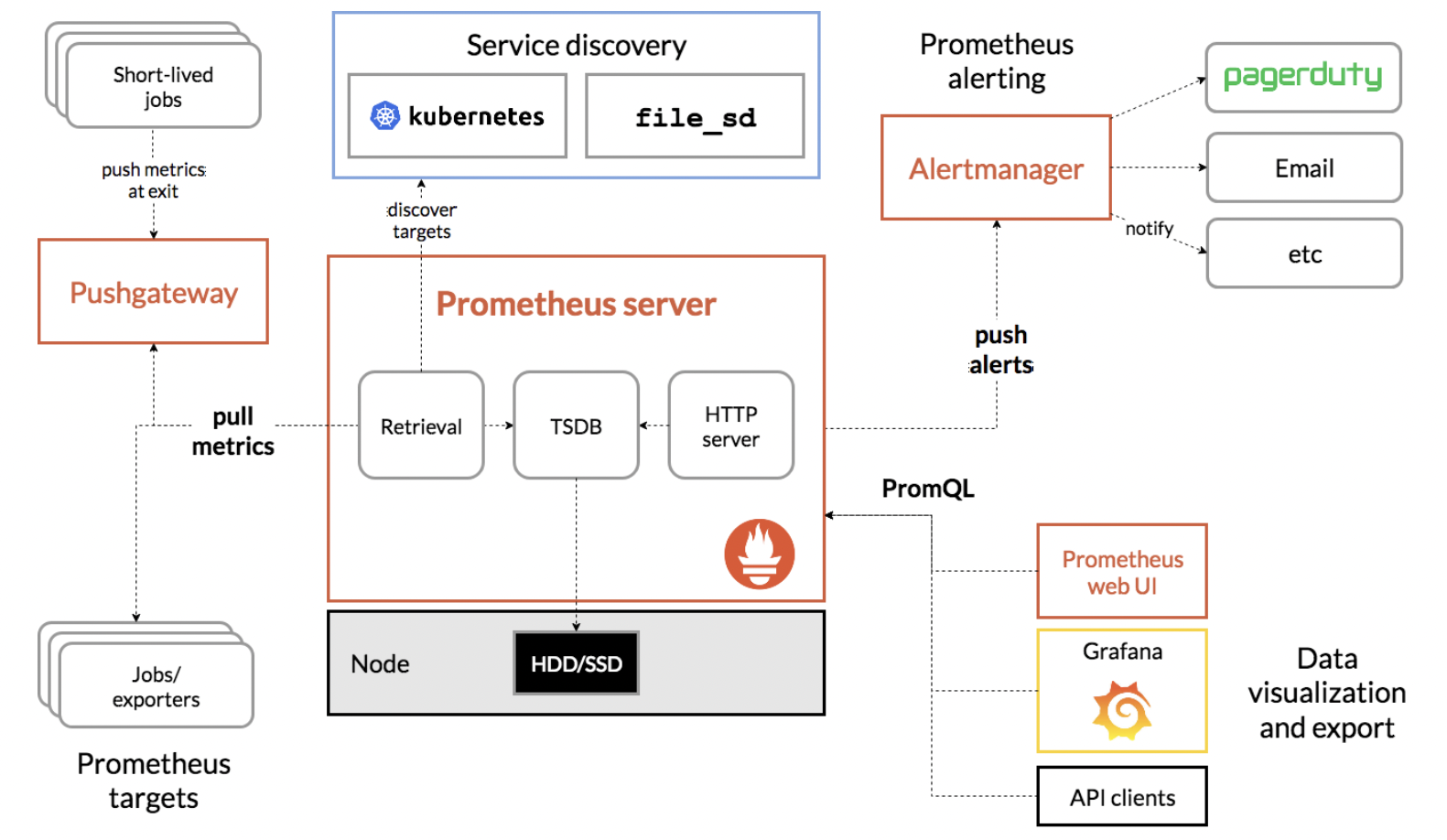
The image below depicts the Prometheus scraping process as it is configured in our monitoring setup. Within this architecture:
- The "Prometheus server" is the central component that retrieves and stores metrics.
- "cAdvisor" and the "HTTP server" we set up to expose our custom metrics are represented as "Prometheus targets" in the diagram. cAdvisor captures container metrics, while the HTTP server serves our custom `model_accuracy` and `model_loss` metrics at the `/metrics` endpoint.
- These targets are periodically scraped by the Prometheus server, aggregating data from both system-level and custom performance metrics.
- The aggregated data is then made available to the "Prometheus web UI" and "Grafana," as shown, enabling detailed visualization and analysis through the Grafana dashboard.
This comprehensive dashboard provides insights into various system metrics across client-server containers. It includes visualizations such as:
- **Application Metrics**: The "Model Accuracy" graph shows an upward trend as rounds of training progress, which is a positive indicator of the model learning and improving over time. Conversely, the "Model Loss" graph trends downward, suggesting that the model is becoming more precise and making fewer mistakes as it trains.
- **CPU Usage**: The sharp spikes in the red graph, representing "client1", indicate peak CPU usage, which is considerably higher than that of "client2" (blue graph). This difference is due to "client1" being allocated more computing resources (up to 4 CPU cores) compared to "client2", which is limited to just 1 CPU core, hence the more subdued CPU usage pattern.
- **Memory Utilization**: Both clients are allocated a similar amount of memory, reflected in the nearly same lines for memory usage. This uniform allocation allows for a straightforward comparison of how each client manages memory under similar conditions.
- **Network Traffic**: Monitor incoming and outgoing network traffic to each client, which is crucial for understanding data exchange volumes during federated learning cycles.
Together, these metrics paint a detailed picture of the federated learning operation, showcasing resource usage and model performance. Such insights are invaluable for system optimization, ensuring balanced load distribution and efficient model training.
## Comprehensive Monitoring System Integration
### Capturing Container Metrics with cAdvisor
cAdvisor is seamlessly integrated into our monitoring setup to capture a variety of system and container metrics, such as CPU, memory, and network usage. These metrics are vital for analyzing the performance and resource consumption of the containers in the federated learning environment.
### Custom Metrics: Setup and Monitoring via Prometheus
In addition to the standard metrics captured by cAdvisor, we have implemented a process to track custom metrics like model's accuracy and loss within Grafana, using Prometheus as the backbone for metric collection.
1. **Prometheus Client Installation**:
- We began by installing the `prometheus_client` library in our Python environment, enabling us to define and expose custom metrics that Prometheus can scrape.
2. **Defining Metrics in Server Script**:
- Within our `server.py` script, we have established two key Prometheus Gauge metrics, specifically tailored for monitoring our federated learning model: `model_accuracy` and `model_loss`. These custom gauges are instrumental in capturing the most recent values of the model's accuracy and loss, which are essential metrics for evaluating the model's performance. The gauges are defined as follows:
```python
from prometheus_client import Gauge
accuracy_gauge = Gauge('model_accuracy', 'Current accuracy of the global model')
loss_gauge = Gauge('model_loss', 'Current loss of the global model')
```
3. **Exposing Metrics via HTTP Endpoint**:
- We leveraged the `start_http_server` function from the `prometheus_client` library to launch an HTTP server on port 8000. This server provides the `/metrics` endpoint, where the custom metrics are accessible for Prometheus scraping. The function is called at the end of the `main` method in `server.py`:
```python
start_http_server(8000)
```
4. **Updating Metrics Recording Strategy**:
- The core of our metrics tracking lies in the `strategy.py` file, particularly within the `aggregate_evaluate` method. This method is crucial as it's where the federated learning model's accuracy and loss values are computed after each round of training with the aggregated data from all clients.
```python
self.accuracy_gauge.set(accuracy_aggregated)
self.loss_gauge.set(loss_aggregated)
```
5. **Configuring Prometheus Scraping**:
- In the `prometheus.yml` file, under `scrape_configs`, we configured a new job to scrape the custom metrics from the HTTP server. This setup includes the job's name, the scraping interval, and the target server's URL.
### Visualizing the Monitoring Architecture
The image below depicts the Prometheus scraping process as it is configured in our monitoring setup. Within this architecture:
- The "Prometheus server" is the central component that retrieves and stores metrics.
- "cAdvisor" and the "HTTP server" we set up to expose our custom metrics are represented as "Prometheus targets" in the diagram. cAdvisor captures container metrics, while the HTTP server serves our custom `model_accuracy` and `model_loss` metrics at the `/metrics` endpoint.
- These targets are periodically scraped by the Prometheus server, aggregating data from both system-level and custom performance metrics.
- The aggregated data is then made available to the "Prometheus web UI" and "Grafana," as shown, enabling detailed visualization and analysis through the Grafana dashboard.
 By incorporating these steps, we have enriched our monitoring capabilities to not only include system-level metrics but also critical performance indicators of our federated learning model. This approach is pivotal for understanding and improving the learning process. Similarly, you can apply this methodology to track any other metric that you find interesting or relevant to your specific needs. This flexibility allows for a comprehensive and customized monitoring environment, tailored to the unique aspects and requirements of your federated learning system.
## Additional Resources
- **Grafana Tutorials**: Explore a variety of tutorials on Grafana at [Grafana Tutorials](https://grafana.com/tutorials/).
- **Prometheus Overview**: Learn more about Prometheus at their [official documentation](https://prometheus.io/docs/introduction/overview/).
- **cAdvisor Guide**: For information on monitoring Docker containers with cAdvisor, see this [Prometheus guide](https://prometheus.io/docs/guides/cadvisor/).
## Conclusion
This project serves as a foundational example of managing device heterogeneity within the federated learning context, employing the Flower framework alongside Docker, Prometheus, and Grafana. It's designed to be a starting point for users to explore and further adapt to the complexities of device heterogeneity in federated learning environments.
By incorporating these steps, we have enriched our monitoring capabilities to not only include system-level metrics but also critical performance indicators of our federated learning model. This approach is pivotal for understanding and improving the learning process. Similarly, you can apply this methodology to track any other metric that you find interesting or relevant to your specific needs. This flexibility allows for a comprehensive and customized monitoring environment, tailored to the unique aspects and requirements of your federated learning system.
## Additional Resources
- **Grafana Tutorials**: Explore a variety of tutorials on Grafana at [Grafana Tutorials](https://grafana.com/tutorials/).
- **Prometheus Overview**: Learn more about Prometheus at their [official documentation](https://prometheus.io/docs/introduction/overview/).
- **cAdvisor Guide**: For information on monitoring Docker containers with cAdvisor, see this [Prometheus guide](https://prometheus.io/docs/guides/cadvisor/).
## Conclusion
This project serves as a foundational example of managing device heterogeneity within the federated learning context, employing the Flower framework alongside Docker, Prometheus, and Grafana. It's designed to be a starting point for users to explore and further adapt to the complexities of device heterogeneity in federated learning environments.