Announcing Flower Datasets


Flower Datasets is a new Python library that lets you easily download and partition datasets for Federated Learning, Federated Analytics, and Federated Evaluation. This makes you more productive and your solution clear and easy to use with all popular ML frameworks.
Whenever you work on Federated Learning, you need to take special care about the dataset preparation. You need to find the library that lets you download it or do it manually and only then partition it. Also, recall the times you read a paper and were not sure about the settings used for the experiments. You probably also read code that was complex and had some poor abstraction that made you reread it a few times. Lastly, you might have read some code that was good, but it used a different framework than yours and forced you to re-implement it. The whole data preparation process is time-consuming. Additionally, it requires even more effort if you want to make your solution reusable by other people.
Flower Datasets handles all of this complexity for you. It lets you easily download a dataset and partition it while specifying all the parameters. All of that in just as little as 3 lines of code.
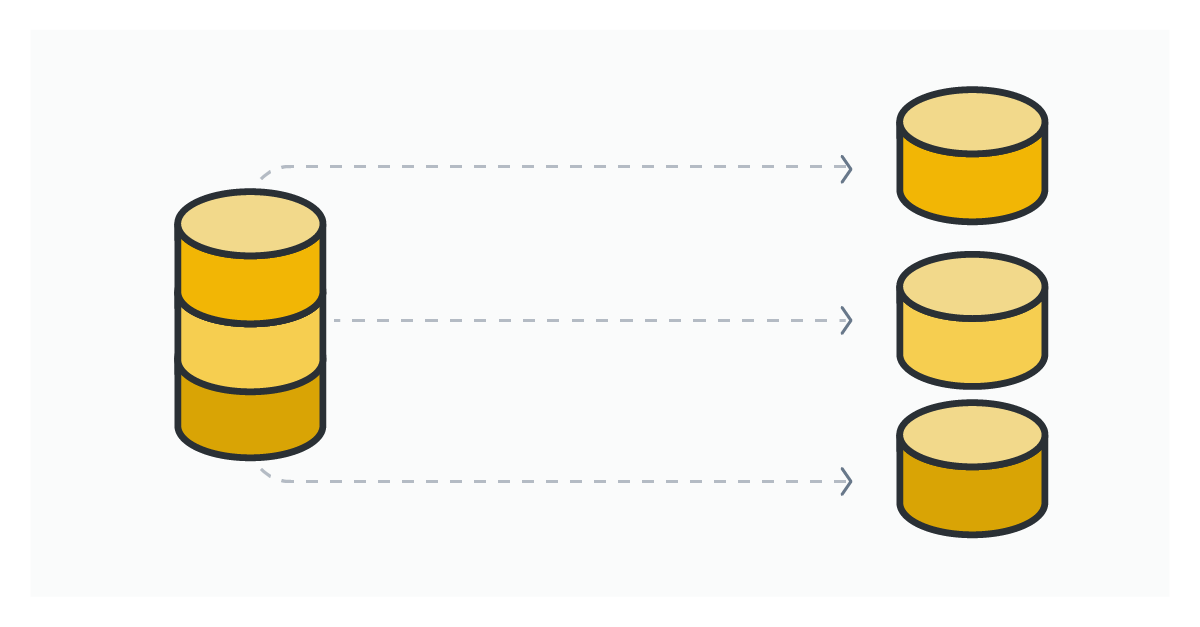
It produces a solution that is clear, easily reproducible, and integrates seamlessly with different frameworks. Regardless of whether you write a research paper or want to test your development pipeline, you can save yourself time and not worry about the implementation details because you use reliable partitioning schemes carefully tested and reviewed by some of the best researchers and engineers in the field.
The lack of genuine distributed datasets, and difficulty in their usage, is holding back progress in federated learning research and adoption. Flower Datasets represents a important step forward in solving these problems, and we hope will lead to more comprehensive and reproducible evaluation in the field.
~ Nic Lane, Prof. at the University of Cambridge and Co-Founder/CSO at Flower Labs
To start using Flower Datasets, simply install the library by
pip install flwr-datasets
If you are working with an image dataset, add the [vision] at the end of the name when downloading the library, and [audio] in case of working with audio.
You can use any dataset available on Hugging Face Hub. Let's create 3 i.i.d. partitions from the "train" split of the CIFAR10 dataset.
from flwr_datasets import FederatedDataset fds = FederatedDataset(dataset="cifar10", partitioners={"train": 3}) partition = fds.load_partition(0)
The library enables total flexibility. Adjust the parameters, use different out-of-the-box partitioning schemes, or create your custom Partitioner, and decide what splits of the dataset you need and to what extent. Do you want to separate some parts of the data for evaluation only but keep the others for training, or keep some parts as the centralized dataset? We have you covered. flwr-datasets gives you a solution fully tailored to your needs in just three lines of code.
For a full Federated Learning example already integrated with Flower Framework, go through our PyTorch quickstart example. Feel free also to check more end-to-end examples that support different frameworks and tasks.
When working on Federated Learning, you’ll often find yourself spending a considerable amount of time preprocessing and constructing your data partitions. flwr-datasets makes this an effortless process.
~ Javier Fernandez-Marques, Research Scientist at Flower Labs
Please note that we are standing on the shoulders of giants. Flower Datasets would not have been possible without the amazing #OpenSourceAI community. A special shout-out goes to 🤗 Hugging Face. Their incredible library, infrastructure, and the Dataset abstraction are a great engineering feat, and we're bringing them to the Federated Learning community through Flower Datasets.
Quickly create datasets for federated learning/analytics/evaluation with tested reliable implementations that support your ML framework by using Flower Datasets.
We'd love to hear your feedback, suggestions, and the questions you have. Make sure to join the Flower community on Slack, and give us a start on GitHub so you will not miss any updates.
Stay tuned. In the future, we will also support synthetic datasets, an even wider range of datasets, new partitioning schemes, and partitioning for Vertical FL. Follow Flower Labs to get the news: Twitter, LinkedIn, and YouTube.