What is the Carbon Footprint of Federated Learning?

For the better part of a decade, deep learning (DL) algorithms keep growing in complexity, and numerous SOTA models have been developed, each requiring a substantial amount of computational resources and energy, resulting in significant environmental costs. In fact, Nature 2018 revealed that each year data centers are responsible for 0.3% of global carbon emissions. Fortunately, alternatives to data center-based DL (and other forms of machine learning) are emerging. Amongst these, the most prominent to date is Federated Learning (FL). Despite there have been a number of literature addressing the issue of carbon emission regarding centralized learning (Strubell et al. 2019, Henderson et al. 2020, Anthony et al. 2020), there is currently a lack of research on how FL can potentially cut the carbon footprint and save the planet.
On the one hand, devices on the edge consume far less power than centrally deployed GPUs in data centers. However, on the other hand, since data distribution is realistically non-IID, wall clock time for training can be much higher than centralized learning. Therefore, a systematic quantitative CO2 e (CO2 equivalent) emissions estimation method for FL is needed.
In our recent work, we have shown that FL can have a positive impact on reducing carbon emissions. We also provided an easy-to-use carbon footprint calculator for FL here.
In the next section, we are going to break down estimating carbon footprint into three main factors: training energy, wide-area-networking (WAN) energy, and conversion to carbon emission. Then, we will provide and discuss some of the key results we found during our studies.
Training Energy Consumption
To estimate the carbon footprint, we first need to measure the energy consumption caused by training on GPUs and CPUs, which can be measured by sampling GPUs and CPUs power consumption at training time. For instance, we can repeatedly query the NVIDIA System Management Interface to sample the GPU power consumption and report the average overall processed samples while training. Alternatively, we can assume a full GPU utilization and estimate using the official hardware TDP. However, we must note that GPU is rarely used at 100% of its capacity.
Second, we need to measure the wall clock time per communication round. During each communication round, certain devices (or clients) are chosen for training. As mentioned before, the number of communication rounds required for FL can be much higher than for centralized learning. Also, FL might suffer from system heterogeneity as different edge devices might not all offer the same computation power. However, such a distribution of clients is extremely difficult to estimate for various reasons. As an example, sales figures for these devices are not publicly released by the industry.
One noticeable difference with the energy consumption of FL in relation to centralized training is that FL doesn't need additional energy for cooling. Cooling in data centers often accounts for up to 40% of the total energy consumption, but this factor doesn't exist for FL.
To summarize, we can define the total training energy for FL as:
TFL(e, n, R) = ∑R j=1 ∑N i=1 1{Clt(i,j)}(tie client,i)
where 1{Clt(i,j)} is the indicator function indicating if client i is chosen at round j, ti is the wall clock time per round and eclient,i is the power of client i.
Wide-area-networking (WAN) Emission
As clients continue to perform individual training on local datasets, their models begin to diverge. To mitigate this effect, model aggregation must be performed by the server in a process that requires frequent exchange of data. For this reason, we must also consider the amount of emission derived from model parameter exchange between server and clients during the beginning and the end of each round.
According to Malmodin & Lunden (2018), the embodied carbon footprint for Information and Communication Technology (ICT) network operators is mainly related to the construction and deployment of the network infrastructure including digging down cable ducts and raising antenna towers.
Regarding FL, we estimate the energy required to transferring model parameters between a server and the clients following two parts. The first part is the download and upload energy consumed by routers, while the second part is the energy consumed by the hardware when downloading and uploading the model parameters. We propose to use country-specific download and upload speed as reported on Speedtest and router power reported on The Power Consumption Database.
Let us define D and U as the download and upload speeds expressed in Mbps respectively. Then let S be the size of the model in Mb, er be the power of the router, and eidle be the power of the hardware of the clients when it is idle. Then the communication energy per communication round can be calculated by the following equation:
∑R j=1 ∑N i=1 1Clt(i,j) (S(D+U))/(DU) (er + e idle,i)
Converting to Carbon emission
Realistically, it is difficult to compute the exact amount of CO2e emitted in a given location since the information regarding the energy grid, i.e., the conversion rate from energy to CO2e is rarely publicly available. Therefore, we assume that all data centres and edge devices are connected to their local grid directly linked to their physical location. Then we use electricity-specific CO2 emission factors obtained from Brander et al. As expected, countries relying on carbon-efficient productions are able to lower their corresponding emission factor.
As we know, carbon emissions may be compensated by carbon offsetting or with the purchases of Renewable Energy Credits (RECs). Carbon offsetting allows polluting actions to be compensated via various investments in different types of projects, such as renewable energies or massive tree planting. Even though a lot of companies are devoting themselves to the carbon offsetting scheme, this approach still contributes to a net increase in the absolute rate of global emission growth in the atmosphere. Therefore, following preliminary works on data centres CO2e emission estimations, we ignore this practice to only consider the real amount of CO2e emitted during the training of the deep learning models.
What does our carbon model find?
We conducted extensive estimates across different types of tasks and datasets, including image classification with CIFAR10 and ImageNet, and keyword spotting with Speech Commands dataset. The entire FL pipeline was implemented using Flower and PyTorch.
The full experimental protocol can be found in our paper, and one of the main estimation results is shown below.
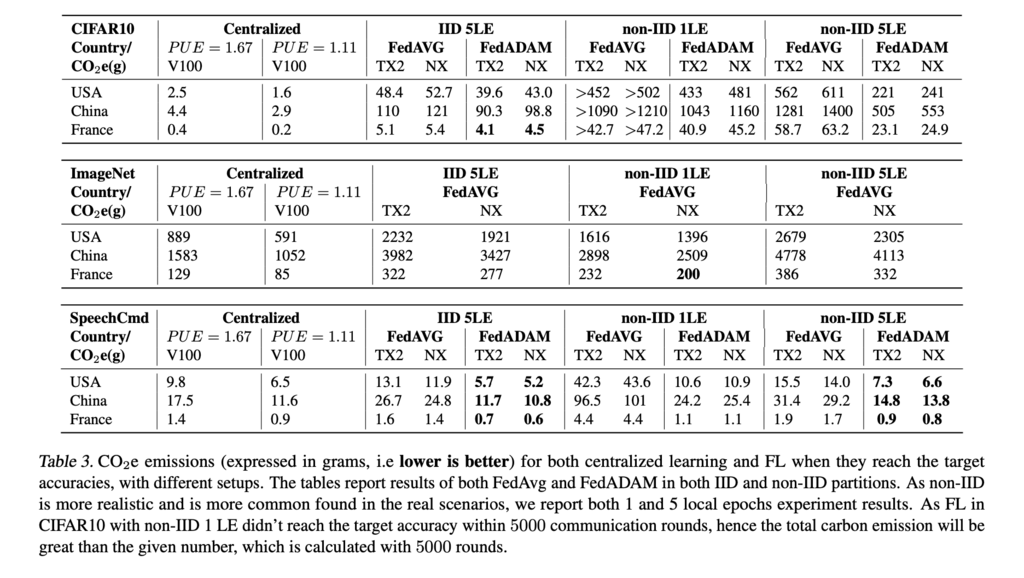
Our experiments found that carbon emission is dependent on (i) devices' physical location; (ii) DL task, model architecture, and FL aggregation strategy; (iii) hardware efficiency; (iv) hyper-parameter tuning; (v) communication costs.
Physical location
It is very intuitive and straightforward. If the training is conducted in a place where it can access more clean energy, the carbon emission will obviously be lower. From our experiments, the first thing to notice is that, due to the large difference between electricity-specific CO2 e emission factors among countries, FL can be comparable or even greener than centralized training. FL provides more advantages when compared to centralized learning, as training can happen without moving data to centralized data centers. Data owners are holding more and more sensitive information, and because of that, there is more data privacy legislation such as GDPR preventing moving data freely. In this case, it can be difficult for people to freely choose the location where their training happens. Unlike centralized learning, FL provides a solution and allows training on devices in all different locations.
DL task, model architecture and FL aggregation strategy
Indeed, we showed that a basic FL setup relying on FedAVG clearly emits more carbon for all three datasets if we compared FL using FedAVG with centralized learning in the same location. However, the difference is much smaller with Speech Commands datasets. As a matter of fact, the lower CO2 estimates obtained with FL on Speech Commands are of great interest. Indeed, in practice, it is most likely that deployed FL tasks (e.g. on device) will be lightweight and certainly aiming at lowering the number of communications. Hence, this type of realistic FL use-cases could benefit our planet. Also, on the Speech Commands dataset, FL is more efficient than centralized training if using FedADAM with 5 local epochs in any given country.
Hardware efficiency
As new AI applications for consumers are created every day, it is realistic to assume that chips like Tegra X2 will soon be embedded in numerous devices including smartphones, tablets, and others. However, such specialized hardware is certainly not an exact estimate of what is currently being used for FL. Therefore, to facilitate environmental impact estimations of large-scale FL deployment, the industry must increase its transparency with respect to their devices distribution over the market.
Also, as explained in our estimation methodology, FL will always have an advantage due to the cooling needs of data centers. In fact, and even though GPUs or even TPUs are getting more efficient in terms of computational power delivered by the amount of energy consumed, the need for a strong and energy-consuming cooling remains -- thus the FL advantage only grows.
Hyper-parameter tuning
As is the case in centralized training, hyper-parameter tuning is of great importance in reducing training times. However, for FL, tuning becomes a more arduous task since it involves the tuning of potentially hundreds of different models (e.g. local models in the clients), each making use of small datasets which likely follow a very skewed distribution. In addition to client-side tuning, the aggregation strategy (e.g. FedADAM) might also offer further parameterization, therefore increasing the complexity of the tuning process. Therefore, novel algorithms should carefully be designed to minimize the carbon emission by jointly maximizing the accuracy and minimizing the released CO2e.
Communication costs
Finally, it is also worth noticing that the percentage of CO2e emission resulting from WAN changes between datasets and FL setups. It highly depends on the size of the model, the size of the dataset and the energy consumed by clients during training. More precisely, communications accounted for 0.4% (ImageNet with 5 local epochs) and 93% (CIFAR10 with 1 local epoch) in the total emissions. With CIFAR10 tasks, communication actually emits way more CO2e than training, while on the other hand, WAN plays a very small role for ImageNet. It is also worth mentioning that communication costs increase proportionally to the number of selected clients in each round, hence it will become even more significant when we are working with a large-scale client pool.
Next Step
With these experiments, we showed that each element of FL can have an impact on the total CO2 emission, and we hope to highlight the carbon footprint of FL with different perspectives. There are certainly a lot of areas in FL that need to be improved such as but not limited to below:
- Efficient strategies trying to reduce the overall communication - rounds especially for the situation when datasets are non-IID distributed across clients
- Efficient client selection strategies to improve the convergence rate hence reduce the overall communication rounds needed
- Communication efficient methodologies
- Efficient hyper-parameter tuning and validation methods
This is only just the beginning. Now we have this framework to analyze the carbon footprint for FL, we can then start to take what is actually a more important step, which is to think about how we can design FL methods to become more carbon friendly. We encourage researchers to address these issues by developing more efficient optimization methodologies that integrate the release of CO2e as a novel metric in the future.