🎒 FL Starter Pack: FedAvg on MNIST using a CNN

Over the coming weeks, we will be releasing a number of new reference implementations useful especially to FL newcomers. They will typically revisit well known papers from the literature, and be suitable for integration in your own application or for experimentation, in order to deepen your knowledge of FL in general. Today's release is the first in this series.
We are happy to announce that we have released a new baseline on the Flower repository! 🎉
You can find it under , it is an implementation of the MNIST experiment from the 2017 McMahan et al. paper .
What's the FL Starter Pack?
The FL Starter Pack is a collection of Flower Baselines that reproduce experiments from some well-known FL papers. They’re a good place to start your exploration of FL.
The idea behind baselines is to provide the community with state-of-the-art examples of how federated learning can be applied. A baseline is just a Flower implementation of an experiment from a FL research paper. It not only allows the community to have a concrete implementation of a paper but also helps get more people involved by providing out-of-the-box solutions for certain problems.
If you'd like to contribute, by implementing a paper you think might be of interest, by sure to check out our guide!
The paper implemented
This week, we chose to implement one of the pioneering papers in the field of Federated Learning (the term actually comes from it 🤯). It was one of the first papers to implement machine learning algorithms in a fully federated setting by proposing the FederatedAveraging strategy.
To demonstrate this, McMahan et al. tested their method on some classical machine learning problems, including multiclass classification of handwritten digits using the MNIST dataset, which is what we implemented in this baseline.
Fun fact: After this first appearance of the term Federated Learning, the number of papers about the subject grew very quickly, so that, in 2020, 3 years after the original publication, about 1 paper every day was published about Federated Learning.
Why MNIST?
We decided to first implement the MNIST digits recognition task as it is very basic and modern neural networks have near perfect accuracy on it, which makes it the ideal baseline.
Partitioning
We implemented two partitioning methods, trying to perfectly replicate what was outlined in the paper.
First there is the IID partitioning (for independent and identically distributed), where the data is randomly distributed amongst clients, so that each one of them holds roughly the same number of samples for each class. This scenario is quite unrealistic and its purpose is more to give a point of reference rather than emulating a real life situation.
Second, there is the non-IID partitioning, where we first sort the data by label and create 2 chunks for each client sequentially (so each chunk contains at most 2 labels), then we randomly distribute 2 chunks to each client. All and all, no client should have more than 4 different labels in its data. This is closer to a real world situation where each user might hold a different distribution of the data.
The model
In order to recognize the handwritten digits, the authors of the paper defined the following Convolutional Neural Network architecture : "A CNN with two 5x5 convolution layers (the first with 32 channels, the second with 64, each followed with 2x2 max pooling), a fully connected layer with 512 units and ReLu activation, and a final softmax output layer (1,663,370 total parameters).".
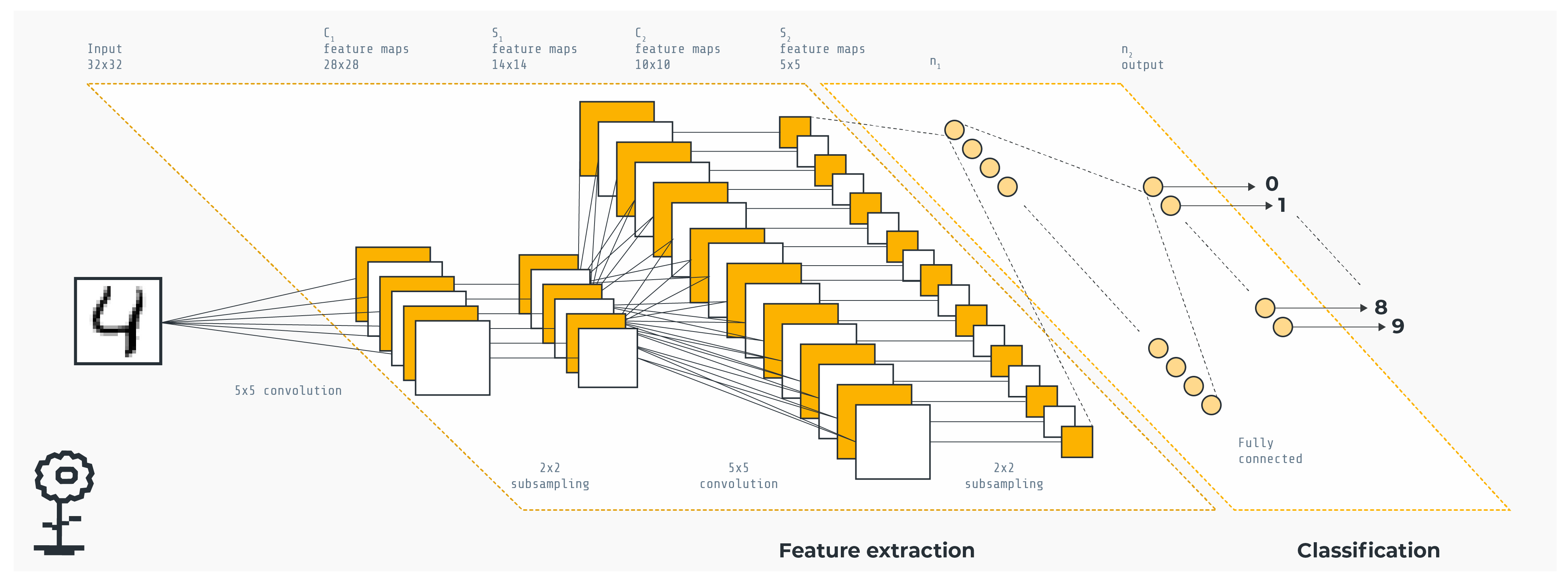
The CNN's architecture.
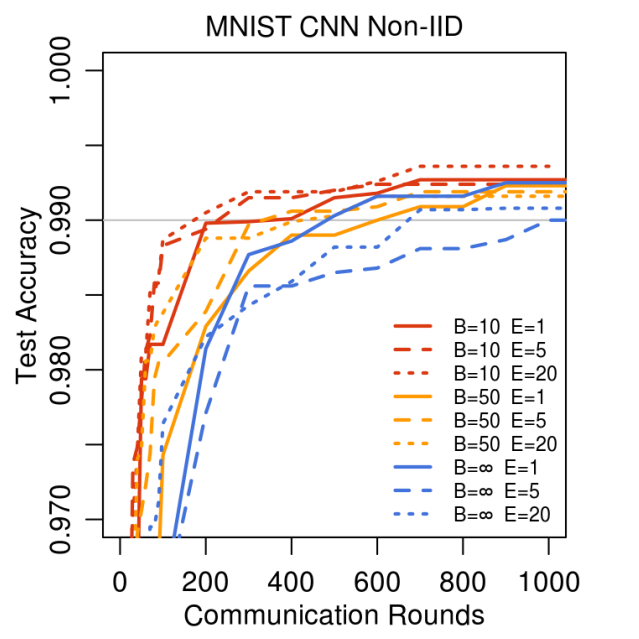
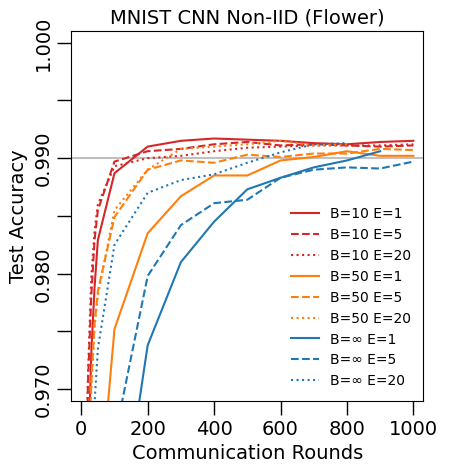
Results for non-IID data
To compare our results with those of the paper, we ran the experiment with the same parameters for a 1000 rounds with a 100 clients :
- Local batch size of 10, 50, and ∞
- 1 or 5 local epochs for each client at each round (20 was too time consuming without much benefit to performance)
- A learning rate of 0.1
As you can see below, compared to the plot shown in the paper, the convergence (above 0.99 accuracy) seems to happen at approximately the same number of rounds (around 200 rounds):
We plan to release a lot more baselines in the coming months, so be sure to check them out! Please don't hesitate to reach out on the if you have any questions.