🎒 FL Starter Pack: FedProx on MNIST using a CNN

We're happy to announce that we have released a new baseline on the Flower repo🎉
You can find it under
,
it is an implementation of the 2018 Li et al. paper
.
The FL Starter Pack
This post is the second of a series called the 🎒 FL Starter Pack, you can check out the first one here.
The 🎒 FLSP is a collection of Flower Baselines that reproduce experiments from some well-known FL papers.
They’re a good place to start your exploration of FL.
The idea behind baselines is to provide the community with state-of-the-art examples of how federated learning can be applied.
A baseline is just a Flower implementation of an experiment from a FL research paper. It not only allows the community to have a concrete implementation of a paper but also helps get more people involved by providing out-of-the-box solutions for certain problems.
If you'd like to contribute, by implementing a paper you think might be of interest, be sure to check out our guide!
The paper implemented
The paper we chose to implement this week introduced a new optimization method called "FedProx" for training deep learning models in a federated setting.
The key idea behind FedProx is to introduce a proximal term to the standard federated optimization objective, which helps to mitigate the impact of non-iid data distribution across clients and improves the overall model performance.
The proximal term
The proximal term in the FedProx strategy refers to a regularization term in the local model that is used on each client.
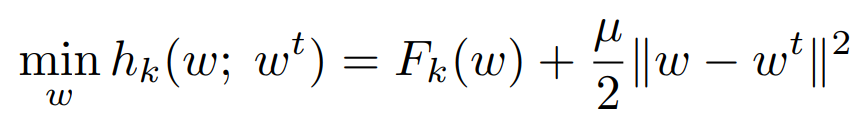
Minimization of the local objective function.
On the formula you can see above,
- Fk(w) represents the local loss function the k-th client is trying to minimize.
- w are the local parameters we are trying to optimize the function with.
- wt are the global weights of the server at epoch t.
- hk(w; wt) is the objective function that client k is trying to minimize (the sum of the local loss function and the regularization term—i.e. the proximal term we have been talking about).
Note that in this scenario we are currently in round t+1.
The proximal term itself is: (μ/2)||wt - w||2.
This term encourages the local model to stay close to the global model (the one that the server aggregates after each round) as it is the L2-norm of the difference between the local model's parameters and the global model's parameters.
The L2-norm is a commonly used measure of the distance between two vectors and is defined as the square root of the sum of the squares of the differences between the corresponding elements of the vectors.
By minimizing this proximal term, the local model's parameters are forced to stay close to the global model's parameters, which improves the communication efficiency and the overall performance of the federated learning system.
Partitioning
Even if the paper only mentions non-IID partitioning, we also implemented IID partitioning for the sake of comparison and also because we already implemented it for the FedAvg baseline.
IID partitioning (for independent and identically distributed): the data is randomly distributed amongst clients, so that each one of them holds roughly the same number of samples for each class. This scenario is quite unrealistic and its purpose is more to give a point of reference rather than emulating a real life situation.
Non-IID partitioning: we first sort the data by label and create 2 chunks for each client sequentially (so each chunk contains at most 2 labels), then we randomly distribute 2 chunks to each client. All and all, no client should have more than 4 different labels in its data. This is closer to a real world situation where each user might hold a different distribution of the data.
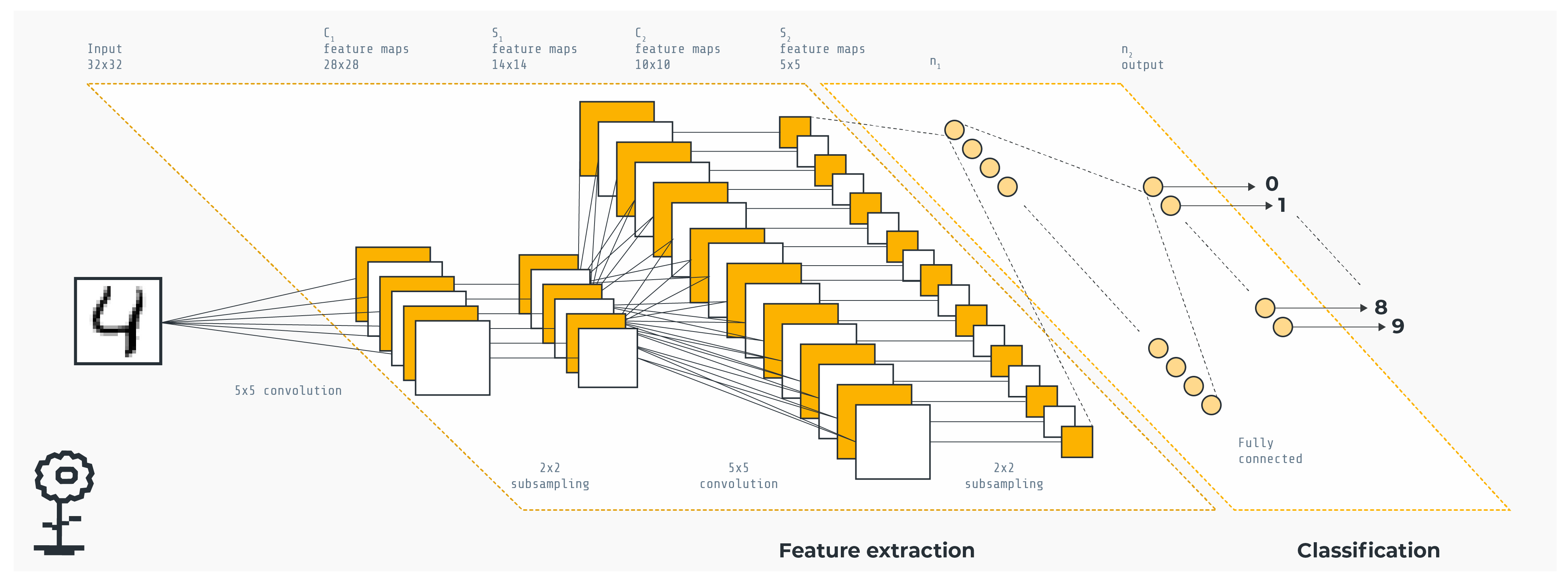
The model
The authors of the paper used the exact same model as the one used in the FedAvg one, that is, a Convolutional Neural Network with the following architecture: "A CNN with two 5x5 convolution layers (the first with 32 channels, the second with 64, each followed with 2x2 max pooling), a fully connected layer with 512 units and ReLu activation, and a final softmax output layer (1,663,370 total parameters).".
We plan to release a lot more baselines in the coming months, so be sure to check them out!
Please don't hesitate to reach out on the if you have any questions.