Federated Learning with Self-Supervision


In this guest blog, we are delighted to have Yasar Abbas Ur Rehman, Research Scientist at TCL, describe his views on the intersection of federated learning and self-supervised learning. Yasar has published a number of research studies that combine these two techniques in the domain of computer vision. He has implemented all of these ideas using Flower.
Self-Supervised Learning
For most of the last decade, we have witnessed the advancement of artificial intelligence (AI) at an unprecedented speed. Self-Supervised Learning (SSL) – sometimes referred to as the dark matter of intelligence – has played a pivotal role in this advancement by enabling the AI models to learn the representations by using supervisory signals that are generated autonomously from the input data. Perhaps surprisingly, such supervisory signals can be generated as easily as by directly perturbing the input data (shuffling the patches of the input image, rotating the image by some degree, etc) or using some properties of it (next-word prediction, image denoising, colorization, etc.).
SSL allows us to harvest the data contents for representation learning by learning intermediate visual representations from unlabelled data, which can then be used as a starting point to solve specific downstream tasks (e.g., human action recognition, and temporal action detection within the video understanding domain). Sometimes these intermediate visual representations are even the desired output. For example, image colorization is essentially a generative SSL method that requires no post-learning. Regardless of the specific SSL method being deployed, SSL models become more robust on a wide range of vision-based tasks when pretrained on real-world and uncurated data. Given such tremendous potential, SSL can extend the horizons of many vision-based applications.
However, the utility of these SSL models is significantly limited by the scale of the datasets available in the data center due to issues such as data privacy, communication cost, and large data storage requirements.
FL + SSL
A natural way to mitigate such issues is to combine SSL with a form of decentralized machine learning known as Federated Learning (FL). In FL, the distributed population of edge devices collaboratively trains a shared model while keeping their personal data private. Essentially, FL dilutes the burden of training across devices and avoids privacy and storage issues by not collecting users' data samples. The potential integration of SSL and FL into one coherent system – that I call in my work F-SSL. Such a solution offers many benefits in addition to data privacy. It enables large-scale decentralized feature learning from real-world data without requiring any costly and laborious data annotations. This can materially improve the performance of important models in daily use today, a natural example being the vast number of vision models for image and video applications.
Challenges to F-SSL
While providing the attractive feature of privacy-preserving AI model learning on user data, F-SSL also suffers from data heterogeneity, this challenge known as non-independently identically distributed (non-IID) data. While non-IID data can come in various forms (e.g., labels, non-uniform distribution of samples, quality of the data), F-SSL can mitigate the label-based heterogeneity by asking each device to run the same SSL (intuitively, learning similar properties, e.g, finding similarity and dissimilarity between the pair of images). Notably, the data heterogeneity (e.g., varying number of samples on each device) and model heterogeneity will still, however, limit the performance of F-SSL.
Interestingly, data heterogeneity and model heterogeneity can be mitigated on the server side by designing customized aggregation methods. For example, in the (my opinion) seminal paper Federated Self-Supervised Learning for Video Understanding that I wrote with a number of co-authors, we designed a customized aggregation strategy named FVSSL that combines conventional supervised FL aggregation methods like FedAvg, optimization loss, and the recent centralized SWA optimization scheme. To take care of the model heterogeneity, we only transceive backbone weights. We found that the classifier is the one responsible for increasing model heterogeneity and hence divergence (see Figure 1).
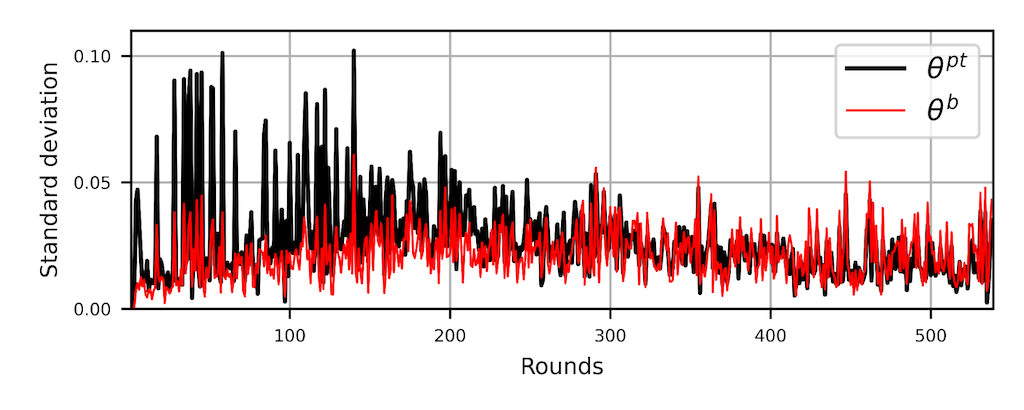
Figure 1. The standard deviation of the L2 difference between the global model weights and the locally trained model weights at each round of video F-SSL pertaining with the FedAvg. Both the backbone θ b and prediction head θpt are aggregated on the server.
Surprisingly, we found that intrinsically non-contrastive video F-SSL pretraining optimization, in cross-device settings, falls into a wider basin of loss-landscape which can then provide better performance on video retrieval tasks compared to the centralized SSL, which falls into a narrow basin of loss-landscape. All of these observations are illustrated in Figure 3. Interestingly, the wider loss landscape of the video F-SSL pretrained models make them resilient to small-scale perturbations (see Figure 2).
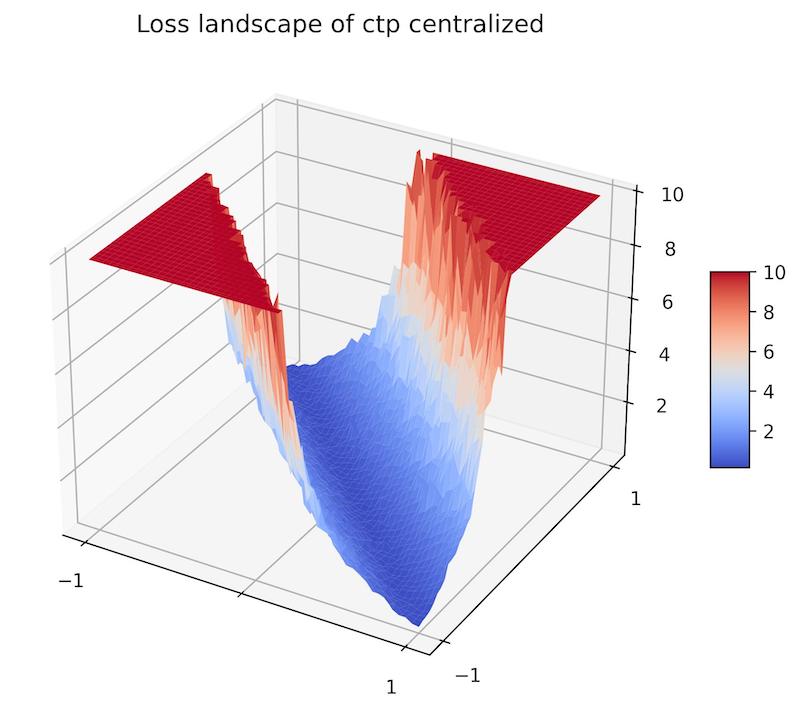
Figure 2. Loss Landscape of Centralized (left) vs. Federated (right) CtP SSL method
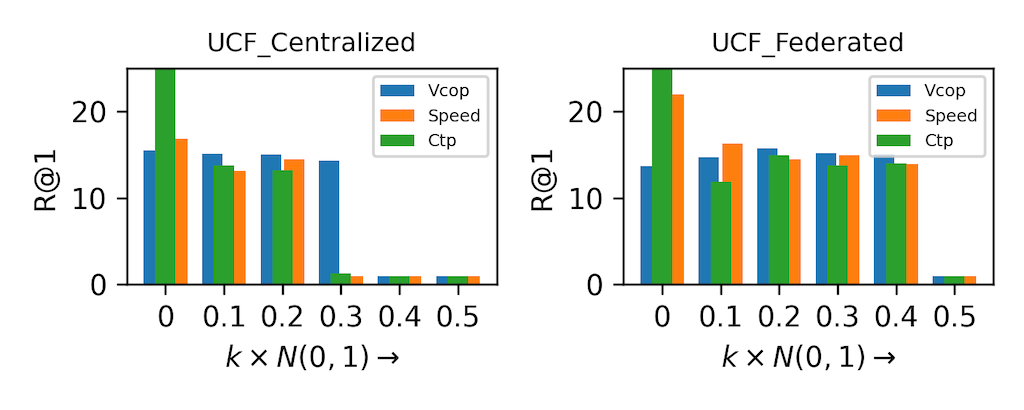
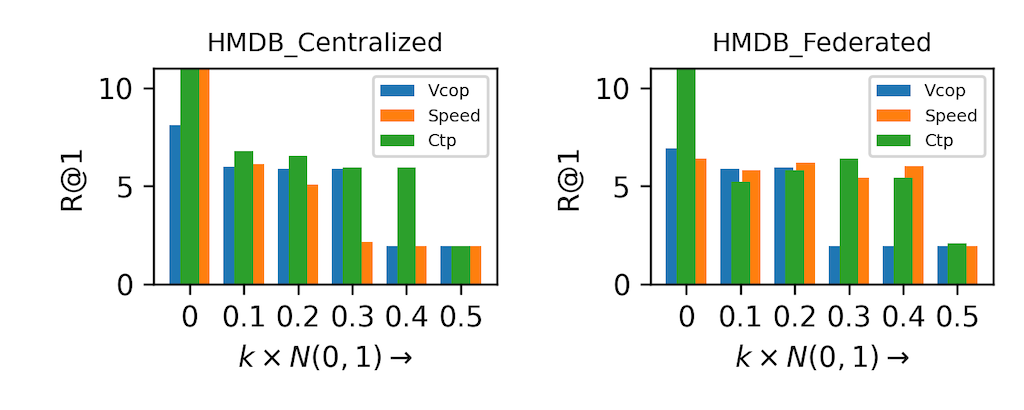
Figure 3. Top 1% action retrieval accuracy on UCF and HMDB by adding perturbation to the model. The perturbations are sampled from a normal distribution N(0,1) and multiplied by the factor k.
A Way Forward
Not transceiving the classifier weights during F-SSL pretraining only solves half of the problem. The aggregation strategies will induce bias in the model weights based on their weighting coefficient that they use to scale the contribution of each client during weight aggregation at the server. For instance, FedAvg gives higher priority to clients with more data overlooking the quality of their model's weights, causing clients' models to drift, and raising fairness issues. While these issues are also prevalent in supervised FL, they are more serious problems in F-SSL which is susceptible to complete (i.e., the model creates the exact same embeddings for each input) or dimensional collapse (i.e., the embeddings vectors produced by the model shrink into a lower dimensional subspace). Such collapses in clients' models can sometimes completely fail durinng F-SSL pretraining and, therefore, can create models that might not perform well on the downstream tasks. As a result, it is important to filter out those clients while performing weight aggregation on the server.
Summary
Combining FL and SSL is a powerful emerging paradigm with especially significant implications for FL. This blog has given some of the detailed observations related to recent thinking in this direction. SSL promises to expand the range of applications to which FL can be applied, because the data labelling problem has been addressed to a large extent. Furthermore, it is then we can expect to see FL systems starting to be able to outperform data center solutions as the scale of usable data to FL vastly increases when it can consume unlabeled data. Finally, this may bring about situations in which FL starts to offer higher accuracy and better generalization than is possible with centralized approach. The reason being the overwhelming amount of data available to FL, and the narrower domain shift between such data – and the data that is used at test time.