Using XGBoost with Flower 🌳

Note that the full code of this example re-locates to hfedxgboost baseline.
XGBoost is a tree-based ensemble machine learning algorithm that uses gradient boosting to improve model accuracy, in this blog post (and the associated baseline), we introduce a novel method to conduct federated XGBoost in the horizontal setting! 🎉
This method, FedXGBllr, was proposed in a very recent paper that has been accepted to EuroMLSys 2023. A pre-print version of the paper is available on arxiv.
Horizontal vs. vertical federated XGBoost
Federated XGBoost approaches typically fall into two categories: horizontal and vertical settings. In the horizontal setting, clients' datasets share the same feature space but have different sample IDs. In contrast, the vertical setting introduces the concepts of passive and active parties, with passive parties and the active party sharing the same samples but having different features. Both settings have practical applications, but the horizontal setting is more prevalent.
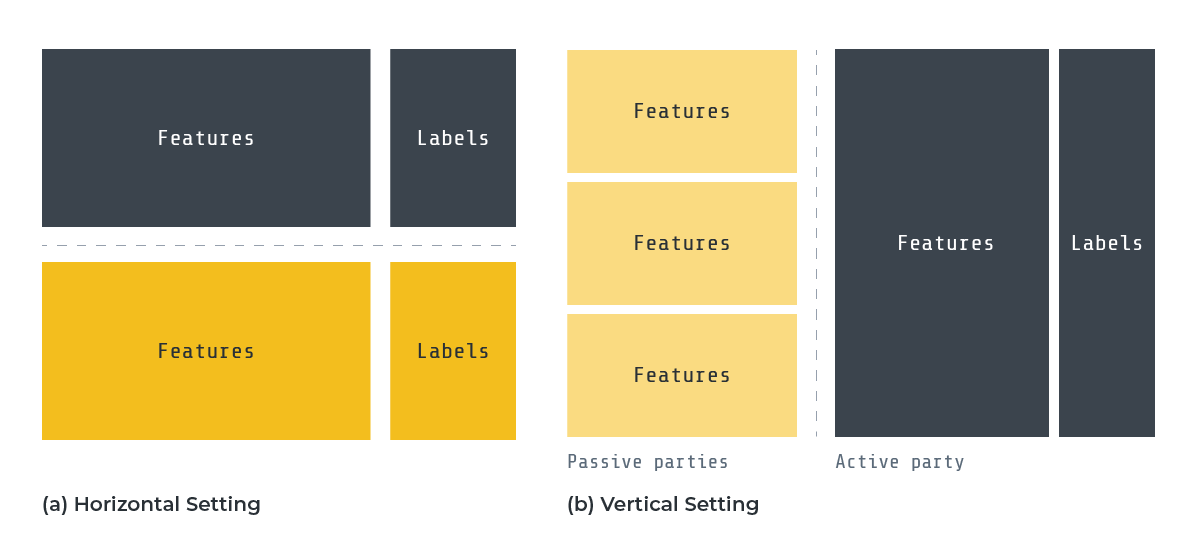
Diagram to compare Vertical vs Horizontal setting.
How the method differs from the previous works
Previous methods for horizontal federated XGBoost relied on gradient sharing, which lead to concerns over per-node level communications and more broadly serious potential privacy risks. FedXGBllr, on the other hand, does not depend on gradient sharing, which boosts privacy and communication efficiency by making the learning rates of aggregated tree ensembles learnable.
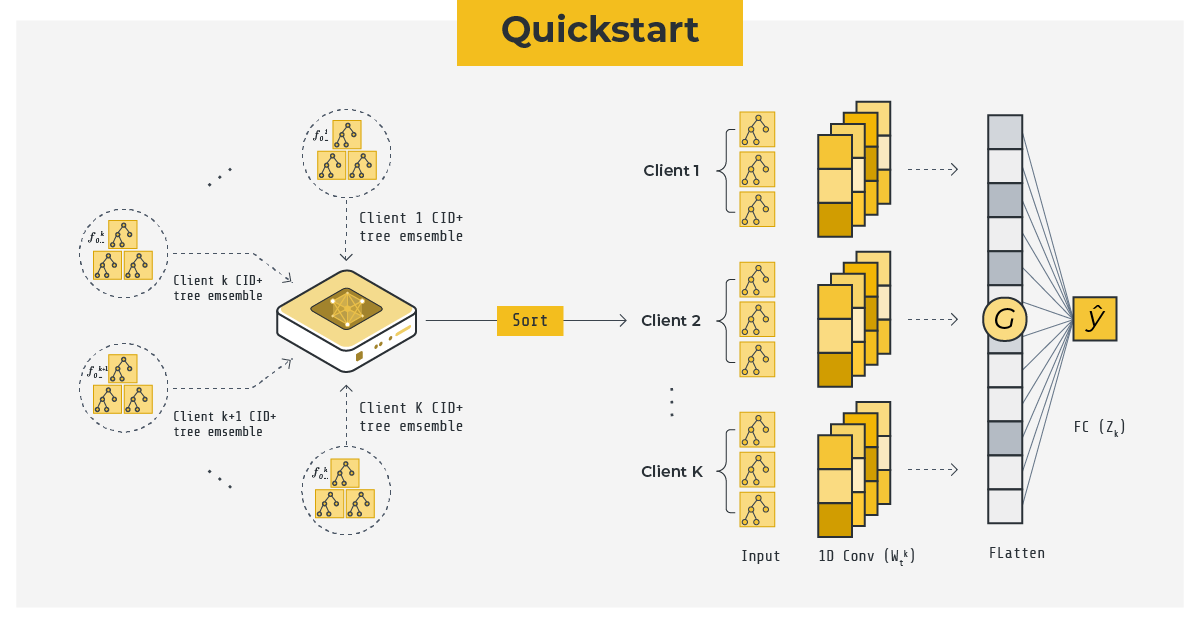
Learnable Learning Rates by One-layer 1D CNN
The design of FedXGBllr contains a crucial insight: given the potential heterogeneity of clients' local datasets in the horizontal setting, using a fixed learning rate for each tree in the XGBoost tree ensemble may be insufficient, as each tree can make varying degrees of errors on unseen data with distribution shifts. To address this, FedXGBllr makes the learning rates of aggregated tree ensembles learnable by training a compact one-layer 1D CNN with kernel size and stride equal to the number of trees in each client tree ensemble, using prediction outcomes as direct inputs. This innovative framework maintains privacy, requiring clients to send only the constructed tree ensemble to the server, without sharing gradients and hessians that can reveal sensitive information. Additionally, the number of communication rounds is not dependent on any client-side XGBoost hyperparameter. The global federated XGBoost model comprises all clients' locally trained XGBoost tree ensembles and the globally trained one-layer 1D CNN.
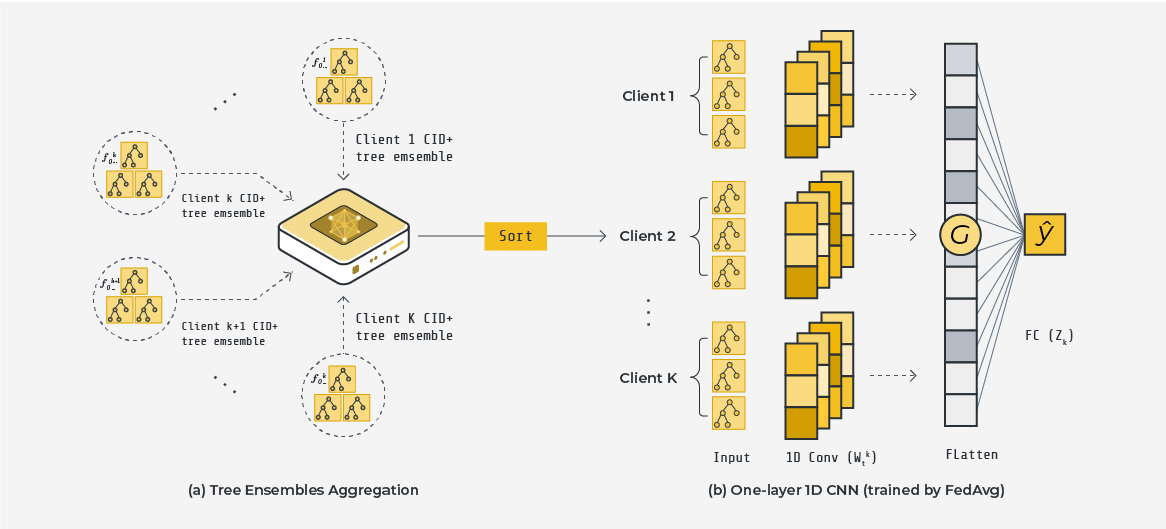
Overview of XGBoost Federated Training.
Interpretability of One-layer 1D CNN
The one-layer 1D CNN is interpretable, with each channel representing learnable learning rates in a specific client's tree ensemble. The number of convolution channels indicates the possible learning rate strategies that can be applied. The classification head, a fully connected layer, contains weighting factors to balance each client's tree ensemble prediction outcomes and computes the final prediction result.
Be sure to go checkout the full code here! Or read the full technical paper for further details. 👀
Please don't hesitate to reach out on the if you have any questions.