
Federated LLM Fine-tuning
Large language models (LLMs), which have been trained on vast amounts of publicly accessible data, have shown remarkable effectiveness in a wide range of ML tasks across many domains. However, despite the fact that more data typically leads to improved performance, there is a concerning prospect that the supply of high-quality public data will deplete within a few years (paper). Furthermore, there is often a need to build more specialized LLMs that can incorporate domain specific knowledge not available in public web-based data, for example in the areas of health, law and finance.
Federated LLM fine-tuning offers a solution by allowing individuals or organizations to collaboratively improve a shared model without sharing their raw data. This technique provides the opportunity for privacy protection (if carefully designed), while also enabling the access to a rich pool of protected data, addressing issues such as the scarcity of public datasets. Using such methods, it also simplifies the creation of more personalised, domain-specific, LLMs models that require sensitive data.
LLM FlowerTune
Adoption and experimentation of LLM-focused federated fine-tuning is lagging behind other advances in LLMs. In response, we are introducing a new example series for Flower that will provide a range of real-world examples for everyone to follow. We aim to highlight how many common LLM fine-tuning use cases are easy under Flower, and hope that the examples can be then adapted to the specific datasets, LLM backbones and other situational requirements by Flower users. Today we are releasing our first example of this series, but will regularly release more that especially consider different data domains and target different LLM architectures (e.g., Llama2, Phi-2, Mistral etc.)
We call our approach LLM FlowerTune because, in time, we will introduce a wider array of techniques within these examples to address more advanced requirements such as, forms of privacy and requirements of communication and compute efficiency. But for now we will focus on simplicity and using existing components (for example, the fine-tuning algorithm).
Our first LLM FlowerTune example is already available! 🎉 In this introductory example we conduct federated instruction tuning with pretrained LLama2 models on the Alpaca-GPT4 dataset. We use Flower Datasets to download, partition and preprocess the dataset. The fine-tuning is done using the 🤗PEFT library. You also do not need the access to a lot of GPU resources in this example as we utilise the highly efficient Flower Simulation Engine. Using the engine, LLM fine-tuning process in a federated way can be done with just a single GPU!
Your First FlowerTune LLM Model
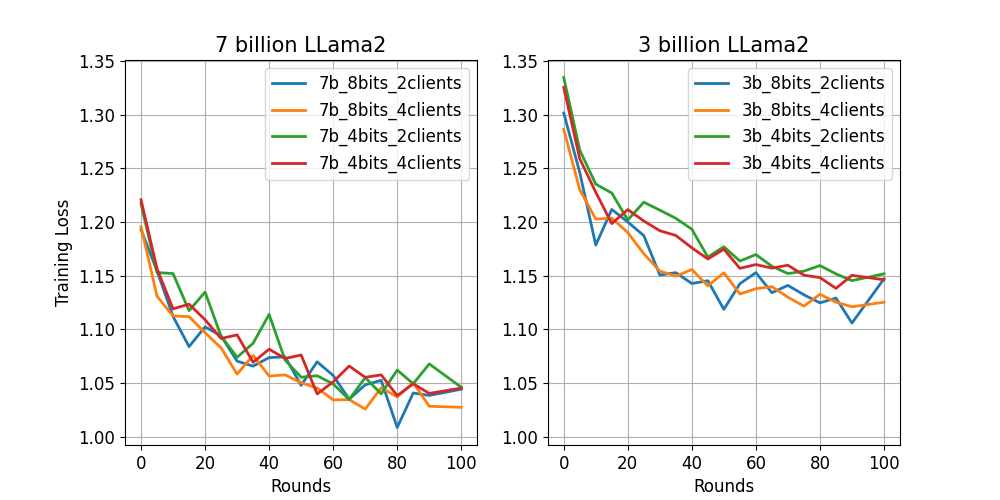
Here we show the result from fine-tuning LLMs under this example. The above figure shows the training loss change over FL rounds for 8 settings. As expected, LLama2-7B model works better than its 3B version with lower training loss. With the hyperparameters tested, the 8-bit model seems to deliver lower training loss for the smaller 3B model compared to its 4-bit version.
Understanding Resource Usage: VRAM Consumption
| Models | 7-billion (8-bit) | 7-billion (4-bit) | 3-billion (8-bit) | 3-billion (4-bit) |
|---|---|---|---|---|
| VRAM | ~22.00 GB | ~16.50 GB | ~13.50 GB | ~10.60 GB |
To efficiently use GPU memory, we make use of the bitsandbytes library in conjunction with PEFT. The above table shows the VRAM consumption per client for the different models considered in this example. You can adjust the CPU/GPU resources you assign to each of the clients based on your device. For example, it is easy to train 2 concurrent clients on each GPU (24 GB VRAM) if you choose a 3-billion (4-bit) model.
Future Examples
This is just the first of our example series for LLM FlowerTune. Watch for subsequent releases where we will consider different domains of data next (e.g., medical and finance). We look forward to seeing what the Flower community produces by building on this example series! 🚀