Announcing Flower Datasets 0.2.0

The Flower Team is excited to announce the release of Flower Datasets 0.2.0!
Flower Datasets (flwr-datasets) is a library to quickly and easily create datasets for federated learning, federated evaluation, and federated analytics. It was created by the Flower Labs team that also created Flower: A Friendly Federated Learning Framework.
What's new?
-
Add label distribution visualization (#3451)
Introduce visualize.plot_label_distributions and visualize.plot_comparison_label_distribution. To learn how to use the new functions visit link.
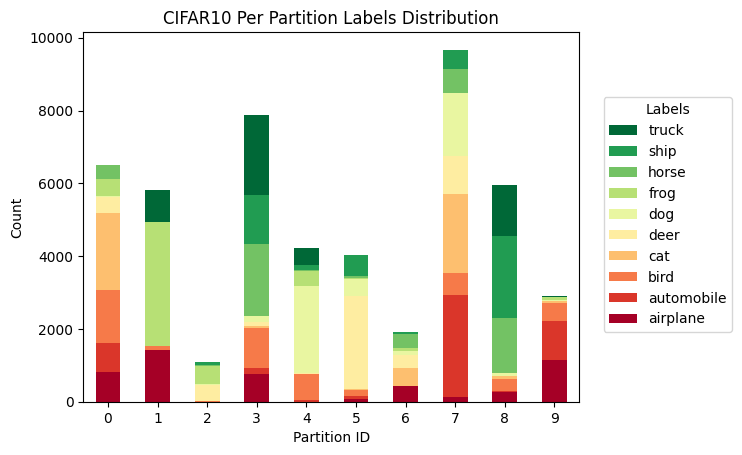
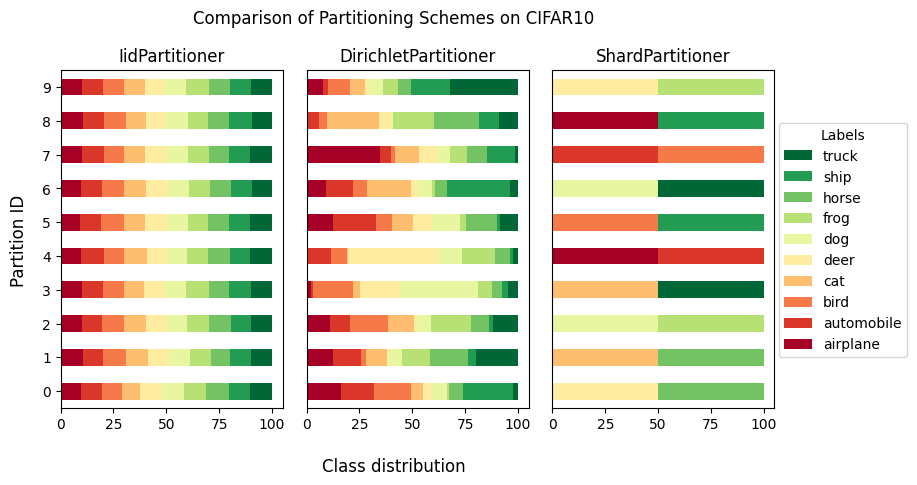
-
Add label count utils (#3551)
Introduce the public methods for compute_counts and compute_frequencies.
-
Improve speed of NaturalIdPartitioner (#3276)
The datasets with a bigger number of unique IDs and a bigger number of samples especially benefit from this improvement.
-
Documentation improvements
-
Flower Datasets README and index page update Include the visualization plots and update the information about the available partitioners.
-
Flower Datasets README update Add a tip section at the beginning that points to complete examples, simplify, and move the installation section to the top.
-
Add how to visualization guide Provide a resource to learn how to visualize the label distribution given a Partitioner instance and how to compare the distributions.
-
-
Fix utils.divide_dataset for division for more than 2 divisions (#3192) Support the division into more than 2 divisions (exclusive parts of a dataset) in utils.divide_dataset. They incorrectly return a dataset of size 0 for the divisions with an index starting from 2.
-
Add fixed seed in train_test_split in examples (#3211)
Add the random_state parameter to the train_test_split function in the examples to ensure reproducibility. The examples now have constant train-test splits along multiple rounds and runs.
-
Add telemetry (#3479)
Start collecting data about the used datasets, partitioners, the type of load_ function in FederatedDataset, and the visualization utils. To learn more visit link.
-
Limit the datasets versions (#3607)
Avoid passing the obligatory trust_remote_code=True to the datasets.load_dataset function by limiting the datasets library version to datasets = ">=2.14.6 <2.20.0". This is a temporary change that can be relaxed once we support passing the kwargs via FederatedDataset to datasets.load_dataset
Incompatible changes
-
Rename resplitter parameter and type to preprocessor (#3476)
Also, simplify the naming of the DivideResplitter to Divider and MergeResplitter to Merger. The *Resplitter are now of type Preprocessor not Resplitter.
-
Rename resplitter in examples (#3485)
Update the examples to use the new preprocessor parameter in FederatedDataset instead of the resplitter.