Federated Datasets in Research


In this blog post, we present an overview of the datasets used for FL research in ICLR 2024, NeurIPS 2023, and ICML 2024, and in the final section, we include a brief example showing how to use these datasets in Python with Flower Datasets.
Data collection
The search query included just the "federated" keyword. It resulted in:
- ICLR 2024: 51 papers.
- NeurIPS 2023: 59 papers.
- ICML 2024: 60 papers.
It gave 170 papers in total from which we extracted the names of the datasets. Five of the papers were concerned with vertical FL; the rest were about horizontal FL, and in this analysis, we do not distinguish between them.
Data overview
In total, 217 unique datasets were used. However, 167 (which is about 75%) of them were used only once! Such high usage of unique datasets makes the comparison between different FL papers hard. Below, we present a summary of this data with distinction between the specific conferences:
| Venue | # FL Papers | Unique Datasets | # Datasets Used 1 | # Datasets Used >1 |
|---|---|---|---|---|
| Combined | 170 | 217 | 161 | 56 |
| ICRL2024 | 51 | 118 | 92 | 26 |
| ICML2024 | 60 | 91 | 77 | 14 |
| NeurIPS2023 | 59 | 72 | 54 | 18 |
Out of the 56 datasets that were used more than once, we will present the top 20 datasets now. The datasets presented there were used at least 4 times. See the plot below:
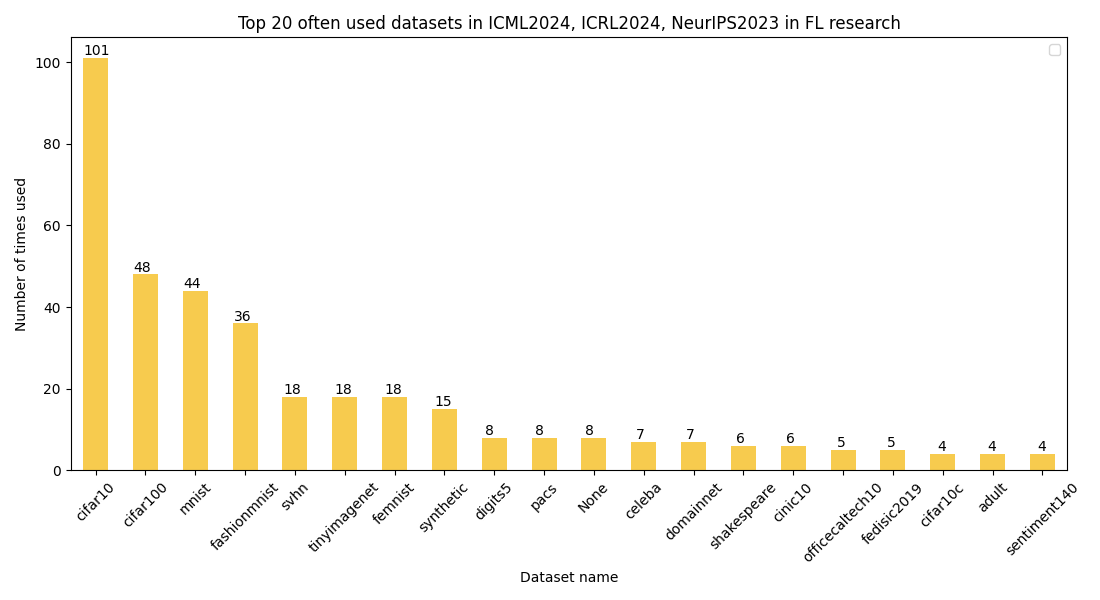
The vast majority of the datasets are in the image domain, and the most popular are the CIFARs dataset. 15 papers used custom synthetic datasets (not necessarily the same), and 8 papers were concerned only with theory and did not use datasets. The most popular tabular dataset was adult (aka census income dataset), and the most popular text dataset was sentiment140 (aka twitter sentiment dataset). The most popular audio dataset - speech commands - was below the top 20, with 3 usages.
In the table below, we show the dataset count information once again next to the links to them on 🤗 Hugging Face. Each of these datasets can be used in the Flower Datasets library with various partitioning schemes.
| Dataset | Count | HF Name |
|---|---|---|
| cifar10 | 101 | uoft-cs/cifar10 |
| cifar100 | 48 | uoft-cs/cifar100 |
| mnist | 44 | ylecun/mnist |
| fashionmnist | 36 | zalando-datasets/fashion_mnist |
| svhn | 18 | ufldl-stanford/svhn |
| tinyimagenet | 18 | zh-plus/tiny-imagenet |
| femnist | 18 | flwrlabs/femnist |
| pacs | 8 | flwrlabs/pacs |
| domainnet | 7 | wltjr1007/DomainNet |
| shakespeare | 6 | flwrlabs/shakespeare |
| celeba | 7 | flwrlabs/celeba |
| cinic10 | 6 | flwrlabs/cinic10 |
| officecaltech10 | 5 | - |
| fedisic2019 | 5 | flwrlabs/fed-isic2019 |
| cifar10c | 4 | - |
| adult | 4 | meghana/adult_income_dataset |
| sentiment140 | 4 | stanfordnlp/sentiment140 |
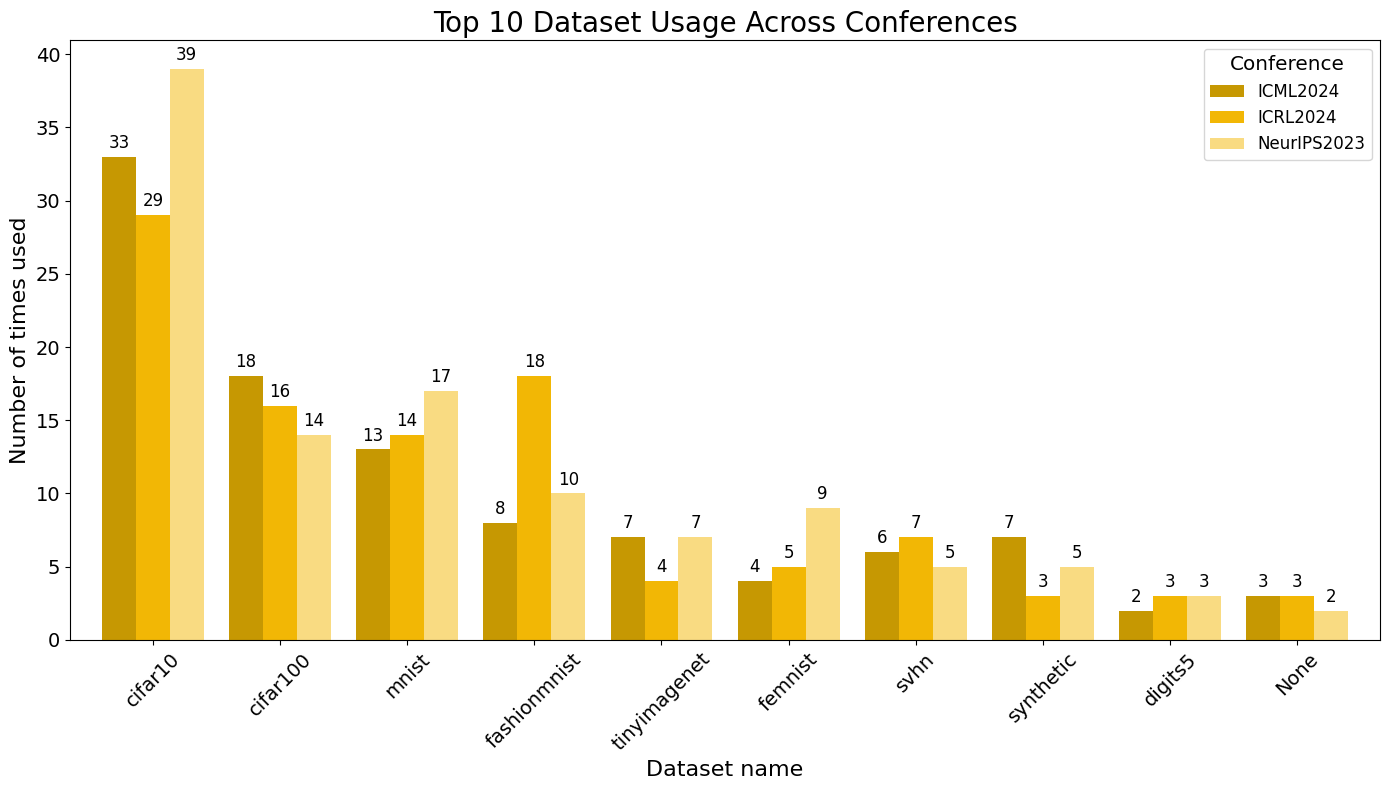
Below, we also present the top 10 datasets used in each conference.
Partitioning Schemes
The information about the partitioning schemes in the analyzed paper was not always complete. This leaves it up to interpretation of how the datasets were exactly partitioned, which can lead to various differences between the methods. Therefore, we don't provide the numerical results but rather present the most common choices more informally.
However, the most popular simulated partitioning schemes include:
- Dirichlet-based partitioning scheme,
- Pathological partitioning scheme (constraining the number of classes per client) or the approximation of pathological - shard partitioning.
We noticed a few other ways of dataset division, e.g., a mixture of pathological partitioning scheme (such that p of the samples belong to a selected number of classes) and iid (for the remaining 1-p samples), or in terms of time series data a division such that each client has data for only a specific day. Also, other types of heterogeneity were simulated beyond the label skew, such as image rotations or flips.
Getting started with Flower Datasets
If you'd like to know more about how to use these datasets in your Federated Learning experiments, visit Flower Datasets documentation.
Here's the basic code that can enable you to match what was done in the research:
flwr_datasets.partitioner import DirichletPartitioner partitioner = DirichletPartitioner( num_partitions=10, partition_by="label", alpha=0.3, ) fds = FederatedDataset( dataset="cifar10", partitioners={"train": partitioner}, ) partition = fds.load_partition(partition_id=0)
And you don't even need to know how to code to create it, visit this website to interactively create the dataset division you need.