Photon: Federated Pre-training of Large Language Models




Next week, Photon – our extension to Flower that enables federated pre-training of LLMs will be presented at MLSys 2025 in Santa Clara. This is the first full conference paper that describes and rigorously evaluates a system of this kind. After more than 12 months of public demonstrations where we used Photon to train LLMs of various model sizes and under challenging network and compute topologies – this latest version of Photon now establishes a new SOTA in efficient and robust decentralized forms of foundation model pre-training.
Why Federated LLM Pre-training?
Training cutting-edge large language models (LLMs) typically requires enormous datasets and computing power concentrated in specialized data centers. This centralized approach makes it expensive and inaccessible for many organizations. Imagine if universities, companies, and labs worldwide could collaboratively train a single LLM without ever sharing their private information – unlocking vast pools of GPUs and data that currently sit siloed. Federated learning offers this vision: low-bandwidth, decentralized training that connects many modest compute clusters (even just a few GPUs each) over the Internet. Such a paradigm could dramatically reduce costly infrastructure needs, make training resilient to hardware failures, leverage regional compute (even based on energy costs), and respect data privacy by keeping data local. These challenges have not been unnoticed by the community, with several research efforts being published to address such issues (see work by Ce Zhang, Arthur Douillard, Max Ryabinin, Peter Richtarik, Zachary Charles, Johannes Hagemann and others). In addition to the pre-training efforts, notable progress has also been made on RL fine-tuning of existing centrally pre-trained models in a decentralized environment up to 72B parameters.
At Flower Labs and the CaMLSys lab in the Computer Laboratory of the University of Cambridge, we have this vision to reality by developing a system to make federated LLM pre-training easy and scalable. This work is an extension of Flower we call Photon. Started more than a year ago, we have used Photon to demonstrate its capability multiple times in the past two years. It was used for the federated training from scratch of a 1.3B in March ‘23 and a 7B in October ‘24. Photon reached a significant milestone in November ‘24, when it was submitted to MLSys. The Photon paper has been peer reviewed and accepted to appear at MLSys 2025 in Santa Clara, CA. Photon is the first full-fledged system for federated end-to-end LLM pre-training, enabling organizations worldwide to co-train large models (up to tens of billions of parameters and beyond) with minimal communication overhead. In this post, we explore why Photon is a significant breakthrough and how it advances large-scale ML in decentralized environments.
Conventional Approaches and their Limitations
Conventional LLM training relies on ultra-high-bandwidth clusters in a single location. Techniques like data-parallel and model-parallel training are efficient only when GPUs are connected by fast interconnects (e.g., NVLink, InfiniBand) in the same data center. Scaling up a model means scaling the infrastructure – more GPUs and networking gear – which centralizes AI power in a handful of well-equipped companies. Moreover, transferring the massive datasets required for training into one place can be very challenging. In a worldwide context, network links between data silos (different companies or institutes) are relatively slow. If we naively tried to run distributed SGD over the public internet, the communication cost would dominate, making training unbearably slow. Past research on low-bandwidth distributed training (like federated optimization or decentralized SGD) struggled to match the raw speed and final accuracy of centralized training. In short, the status quo forces us to bring all the data to the compute (one big data center), because bringing the compute to the data (training across sites) has historically hit a communication wall.
The Photon Approach (and Why It Matters)
Photon turns the traditional approach on its head by embracing federated learning for LLMs. In Photon’s design, multiple independent clients (e.g., data centers or labs in different regions) train the model on their local data, and periodically aggregate their updates via a central server or peer-to-peer protocol. Crucially, Photon uses a carefully optimized variant of federated averaging that requires orders-of-magnitude less communication than standard distributed training. This means even GPUs connected only by commodity internet links (even lower than 1 Gbps!) can meaningfully collaborate. Photon isn’t just a theoretical idea – it’s a complete open-source system built on the Flower federated learning framework. It addresses system-level details like coordinating clients, handling stragglers or dropped connections, and optimizing GPU usage on each client. By proposing a way to train large models “outside the data center”, Photon effectively widens access to LLM development: institutions can keep data in-house and still contribute to a shared model, and unused compute around the world can be tapped to train powerful AI models. This has broad implications for democratizing AI – instead of only Big Tech training the largest models, many players can pool resources without relinquishing data privacy.
Key Insights and Innovations in Photon
Photon introduces several technical innovations that allow federated pre-training to rival conventional training in effectiveness:
- Hyperparameter Tweaks for Fast Convergence: One surprising insight is that we could use small local batch sizes with very high learning rates, leading to faster convergence, which the standard approach cannot robustly adopt. Such a combo might be unstable in standard training, but Photon finds federated averaging naturally smooths out updates. This “injects noise” that helps generalization in practice, allowing Photon to converge twice as fast as prior federated methods like DiLoCo. Essentially, Photon turns what would be a hyperparameter tuning nightmare into an advantage – it’s more forgiving of aggressive learning rates, speeding up learning.
- Minimal Communication via Local Update Fusion: Photon clients perform many local training steps for each communication round, drastically reducing how often they need to synchronize. It’s built on LocalSGD-style federated optimization, meaning models only sync after processing large batches of data locally. The result is a 64×–512× reduction in communication volume compared to standard data-parallel training. For example, in experiments, a Photon client might train on, say, 500× more tokens per upload than a typical centralized GPU would between parameter server updates. Fewer message exchanges create a lower bottleneck for network bandwidth.
- Robustness to Participants Dropping Out: Unlike tightly-coupled multi-GPU training (where one slow node can stall the whole process), Photon’s federated approach is inherently more fault-tolerant. If a participant in the federation goes offline or lags, training can continue with the remaining clients. This robustness is essential in real-world cross-silo settings – it makes training gracefully degrade instead of abruptly failing when facing unsteady connectivity. Photon demonstrated that even with heterogeneous data distributions (clients each seeing different text domains), the global model remains stable and learns effectively without special tuning.
- Scalability with More Clients = Faster Training: Perhaps most impressively, Photon shows that adding more client nodes does reduce the overall training time (up to a point), achieving a similar compute-vs-time scaling trend as in centralized training. In other words, using 16 small data silos in parallel can roughly match the speed of 16 GPUs in one data center, as long as communication is tuned appropriately. This was not obvious going in – previous attempts often saw diminishing returns or even slowdowns with more federated clients due to network overhead. Photon’s optimizations ensure that beyond a certain “global batch size” sweet spot, more compute yields near-linear speedups in wall-clock time. It effectively bridges the gap so that federated setups can scale up almost like a conventional cluster.
These innovations collectively enable Photon to break previous barriers. Not only can it train a model as large as 13 billion parameters from scratch in a federated manner, but it actually achieved lower validation perplexity than the same model trained centrally. This is a huge deal – it means federated training didn’t just “work”, but it matched or exceeded the quality of the traditional approach. Moreover, as the model size grows, the federated approach seemed to yield greater perplexity gains (up to ~17% lower perplexity on a 7B model) compared to centralized training. It’s a promising signal that federated pre-training can unlock generalization improvements, perhaps by virtue of more diverse or larger effective data exposure.
Results: Faster Training with Minimal Communication
Photon’s performance was validated on a massive corpus (including C4 and The Pile datasets) split across multiple clients. The headline results are very encouraging. Photon reached the same or better accuracy faster than centralized training – and with drastically reduced communication. The table below (adapted from the paper’s Table 3) highlights this for model sizes from 1.3B to 7B parameters:
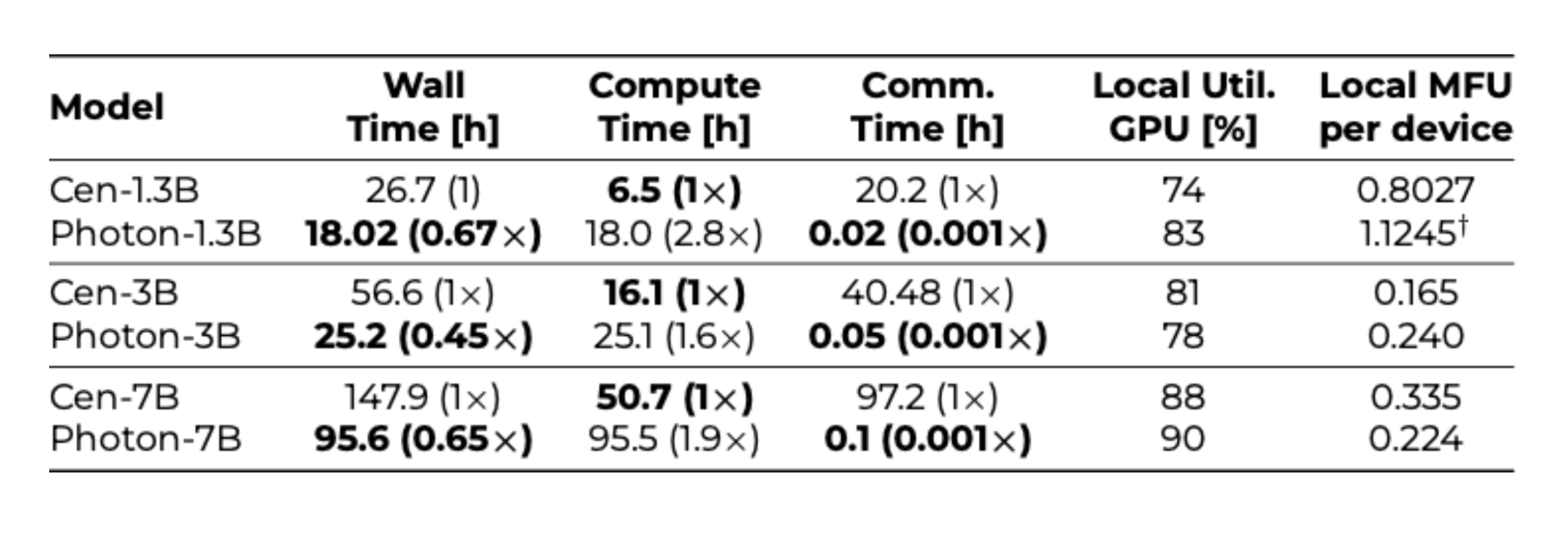
Table 1. Photon vs. Conventional Training for Billion-Parameter LLMs. Each row compares a model with centralized data-center training vs. Photon’s federated method. Wall Time is the total training time to convergence, split into Compute Time (time spent crunching numbers on GPUs) and Communication Time (time spent exchanging updates). Photon’s federated approach incurs slightly more compute time (since each client does more local work), but communication time nearly vanishes, yielding a shorter overall wall-clock. We also see Photon keeping GPUs busy (high utilization) despite the network delays. For instance, the 7B model took ~95.6 hours with Photon versus ~147.9 hours centrally – ~35% faster to reach the same perplexity level. And it did so while cutting data transfer by roughly 1000× (97.2h vs 0.1h of comm.)! These trends hold across model sizes: federated training consistently finishes in less time, thanks to massive communication savings, even though each client spends more time computing locally.
In terms of raw throughput, Photon achieved up to 20% higher training throughput (samples per second) than an equivalently sized centralized setup. This is a remarkable flip of the script – typically, you pay a performance penalty for federated training, but here Photon outperforms a well-optimized data-parallel baseline in speed. It’s important to note the conditions: these experiments assumed a reasonably generous 10 Gbps network link between clients. In real-world internet settings, some links might be slower, but Photon’s protocol can be adjusted (e.g., compressing updates, or using alternate topologies as we’ll discuss) to cope with that. The key takeaway is that Photon makes training large LMs across collaborators economically feasible. That’s why we have already used Photon to execute over 1800 experiments and even power submissions to ML conferences – evidence that it’s not just a one-off demo, but a reusable system.
Design Trade-offs and Network Topologies
A central challenge in federated training is how to aggregate model updates efficiently worldwide. Photon explored different network topologies to minimize the impact of slow connections. Should clients sync in a peer-to-peer ring (each client passes updates to the next), or should they all send to a central server? Figure 3 from the paper illustrates Photon’s deployment across five regions (England, Utah, Texas, Quebec, Maharashtra) and compares two approaches: a Parameter Server (PS) topology (solid lines connecting each site to England) versus an All-Reduce Ring (RAR) topology (dashed loop connecting all sites in a ring).
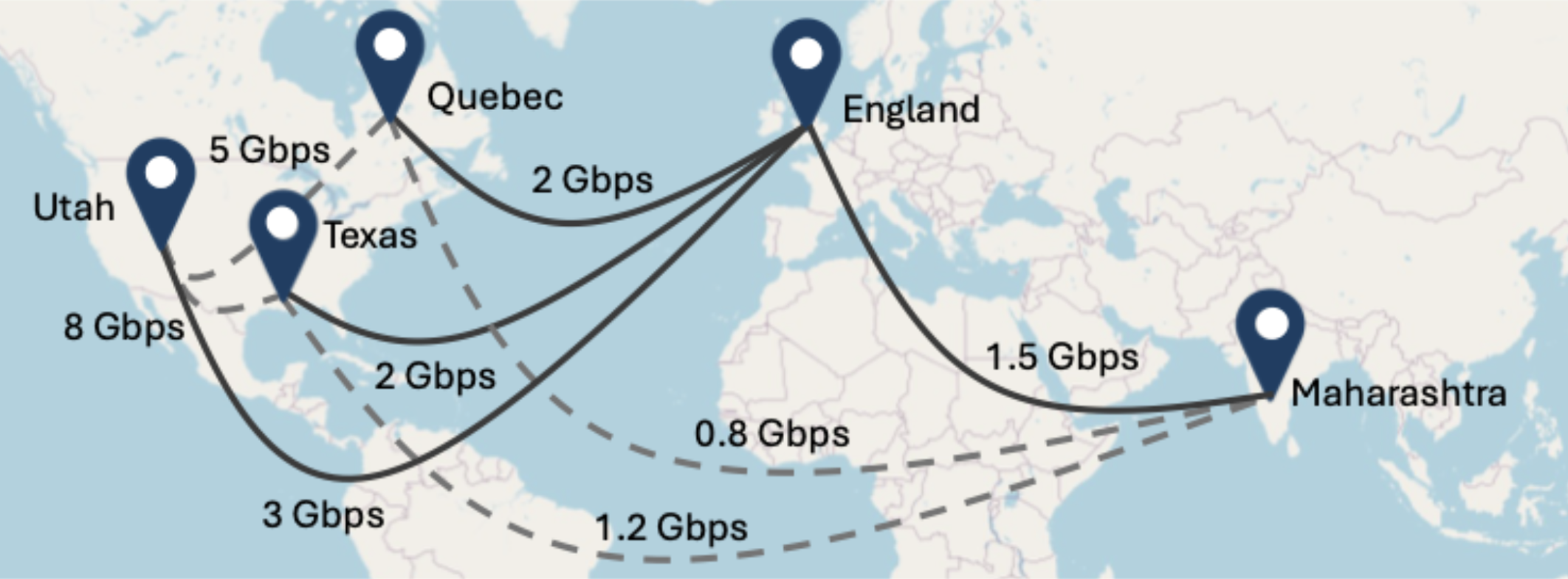
Table 2. Photon’s global federation and communication topology. Each blue pin marks a client location (with multiple GPUs per site), and labels on the connections show bandwidths. In the Ring-AllReduce (RAR) topology (gray dashed lines), clients form a loop and pass updates around; the slowest link (here the 0.8 Gbps link between Maharashtra and Quebec) becomes the bottleneck for each round. In the Parameter Server (PS) mode (black solid lines), a central server (England) collects updates from all; here the limiting factor is the 1.5 Gbps link to England. Photon can operate with either method.
The choice involves a trade-off: RAR is more bandwidth-efficient (no single server handling all traffic) and was found to scale better to many clients, but it is vulnerable to the slowest link in the loop. PS is simpler and can be more robust if one link is extremely slow (others can still send in parallel), but it puts more strain on the server’s uplink. In practice, Photon achieved its best results using Ring-AllReduce with moderate batch sizes, as it balanced the load well. Figure 7 of the Photon paper quantifies this: communication costs do rise with more clients, but RAR still maintained a better overall time than PS in their experiments. The high-level point is that Photon’s design is flexible – it can adopt different aggregation schemes depending on network characteristics, and still reap the benefits of federated training. This flexibility is crucial for real deployments, where network conditions vary (e.g., some collaborators might have a direct fiber link, others only residential broadband). Photon shows that even a worldwide LLM training run is feasible with the right topology and update strategy.
Pre-training a 13B Parameters Model
Scaling experiments have become the standard approach to demonstrate the effectiveness of a method in the machine learning systems community interested in LLMs. We wanted to push Photon further, above the 7B parameters models trained for the conference submission. Can Photon keep up with the largest scales, obtaining scaling gains in system and machine learning performance? For such model sizes, models can also be helpful in practice for inference tasks, and that’s why we plug into Photon a new training recipe we carefully tuned at smaller scales for targeting more significant downstream performance. We used a SmolLM2 mix (70 % web text, 10 % Python, 10 % math, 10 % synthetic) across four clients processed in 2 M tokens per global batch (sequence length = 2048, local batch = 256). Key tweaks include: (i) we synchronized optimizer states in addition to model parameters (per Local Adam theory) and (ii) used ADOPT locally (β₂ = 0.9999) for better small-batch convergence.
In the figure below we can see part of the convergence curve during the training of the first 16 federated rounds. The zoom-in box outlines the most interesting features of this new training recipe: the aggregation phase produces a significant improvement in performance at the round boundary unlike past proposals, such as DiLoCo or FedAvg+AdamW, that usually result in a continuous line or temporary perplexity spikes.
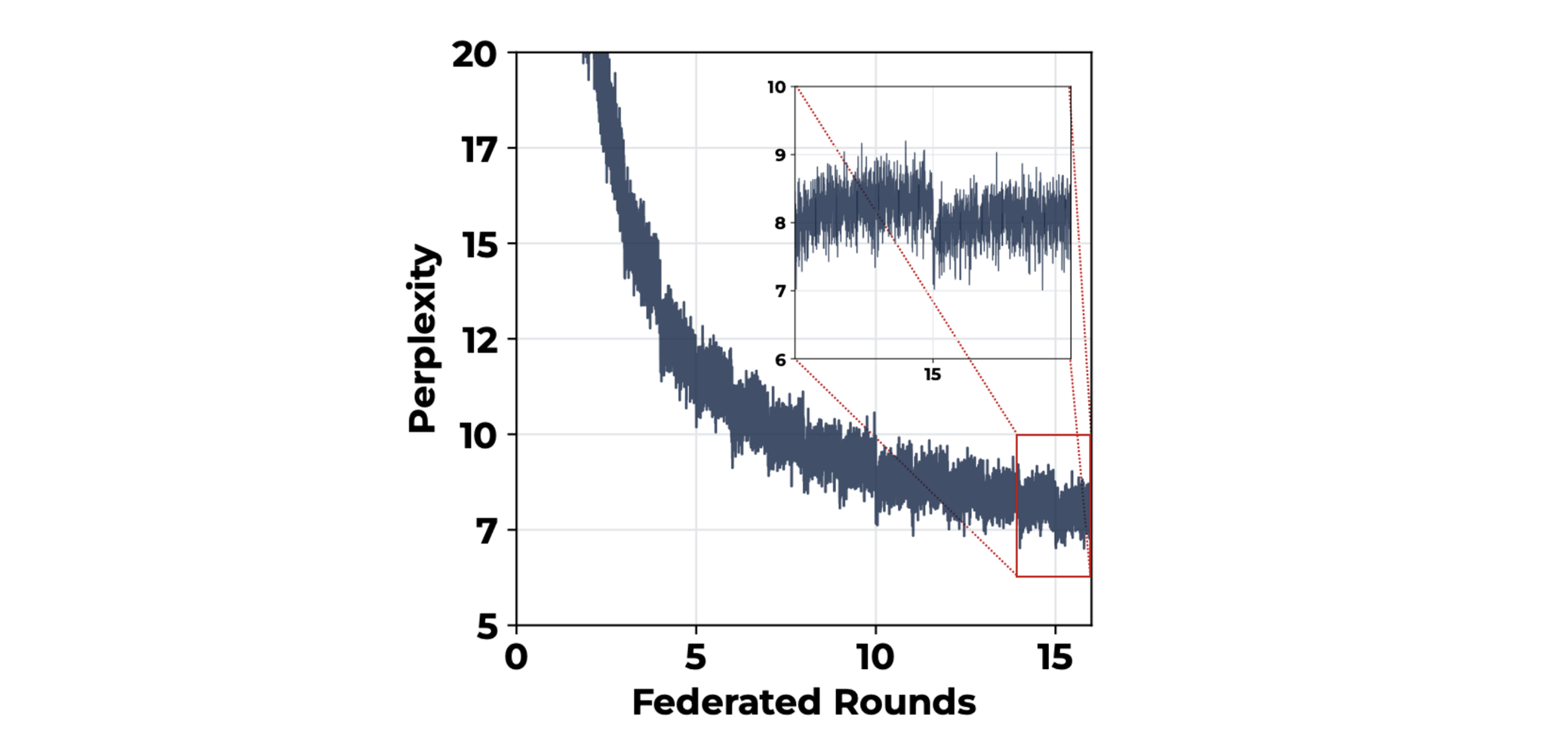
Figure 2. Convergence of the 13B model trained with Photon. This close-up of the convergence curve shows how the new training recipe we adopted impacts the aggregation step and the convergence trend. It’s impressive to notice the performance boost that the aggregation injects into the model, whereas the past proposal suffered from perplexity peaks at round boundaries.
Many practitioners interested in this approach were eager to know whether the real-world environments reflect the efficiency gains expected for these methods. In the table below, we can see real values comparing Photon’s training against the standard centralized approach. The most impressive figure we observed related to the total throughput (samples per second) that Photon’s federation can reach: >2x better throughput than the equivalent standard approach.

Table 2. Infrastructure characteristics and Compute Efficiency of Photon versus Centralized for training the 13B model. In a low-bandwidth (~3 Gbps) cross-cluster scenario, Photon’s approach can achieve >2x the throughput of the standard centralized DDP-based procedure. This impressive gap in performance results in a much quicker convergence.
As the training of this 13B model progresses we will open source its complete training recipe and show more results including downstream in-context learning performance against competitive models of similar sizes and trained on a similar amount of tokens.
Take-Home Message and Next Steps
Photon demonstrates that training large language models no longer needs to be centralized. Through clever optimization and system design, it achieves performance on par with, or even better than, traditional training while dramatically reducing network demands. This work is significant because it opens the door for a new paradigm: global-scale collaboration on LLMs. Organizations can train a shared model on their combined data without pooling the data itself, which could alleviate privacy, ownership, and logistical hurdles. Technically, Photon’s contributions – from hyperparameter tweaks to fault tolerance – push federated learning into a territory (billion-parameter transformers) that was previously thought to be out of reach. In the context of large-scale ML, this is a leap toward more distributed and democratized AI development. Instead of only a handful of tech giants training giant models in secret, we might envision consortia (medical researchers, academic labs, etc.) each training parts of a model and benefiting collectively.
Moving forward, it will be exciting to see Photon adopted and extended. There are open questions about scaling to even larger models (can we federate 100B+ parameters?), handling more extreme network heterogeneity, and integrating with techniques like decoupled embeddings (another recent advance in federated LLM training). The authors have made Photon’s code available, inviting the community to experiment. The bottom line: Photon is a milestone that proves federated pre-training of LLMs works – it’s faster, efficient, and effective. If you’re intrigued by how it all works under the hood or want to reproduce these results, be sure to check out the full paper. It’s an enlightening read that could inspire the next generation of scalable, decentralized AI training.