Announcing the Decentralized AI Hackathon Winners


On September 26th 2025, the Decentralized AI and open-source communities gathered at the Jen-Hsun Huang Engineering Center at Stanford University for a full day of hacking, lightning talks and demos. The hackathon brought together students and researchers from top institutions including Stanford, San Jose State University, UC Berkeley, Carnegie Mellon University, and NYU. Professionals from leading tech companies such as Meta, Apple, Google, Amazon, IBM, and many more also joined.
None of this would have been possible without the support of Kimberly L. Vonner and Prof. Hae Young Noh from Stanford, and the generous sponsorship by AMD. Thank you!
In the following sections, the winners of the hackathon describe what they built, the motivations behind doing so and how they used Flower to accomplish it.
AICONTROLLER, a CLI agent to orchestrate Flower runs
By Thilak Shriyan and Janavi Srinivasan
Our goal was to make federated learning (FL) experimentation more natural, iterative, and intelligent — all from a single terminal.
At its core, AICONTROLLER combines Flower, MongoDB, and Ollama to create an LLM-powered FL controller that can run, track, and refine experiments through natural language. With Flower powering the entire server–client runtime, users can orchestrate FL strategies seamlessly. MongoDB tracks runs, rounds, and metrics for full experiment reproducibility, while a lightweight LLM agent (via Ollama) interprets commands like: “run 3 rounds with FedAdam (lr 0.005, local-epochs 2, fraction-train 0.6)”. The agent executes these runs through Flower and even suggests the next sensible configuration based on past results — closing the loop between experimentation and optimization.
The demo task uses the SOCOFing fingerprint dataset and a custom TrackingStrategy to log all metrics directly from Flower’s runtime. The CLI agent provides tools for listing runs, summarizing results, and comparing strategies like FedAvg and FedAdam — all without writing extra code.
This project highlights how Flower’s modular architecture empowers rapid innovation in federated learning research. By integrating a local LLM, AICONTROLLER showcases what’s possible when human intuition meets Flower’s powerful distributed learning engine. Explore it on GitHub
FedLLM Studio: Democratizing Collaborative LLM Training
By Jonathan Olvera
FedLLM Studio emerged from a simple but powerful question: what if organizations could collaborate to improve their AI models without ever sharing their sensitive data? During the hackathon, I focused on Track 2 (Open-ended Decentralized Revolution) and built a SaaS platform that enables federated fine-tuning of large language models across multiple institutions simultaneously.
The platform allows organizations (hospitals, financial institutions, research labs) to join federated training sessions where each participant's data remains completely private while collectively improving a shared model. Using Flower's simulation engine orchestrated through HiveFlow, I demonstrated how eight different institutions could collaborate: a medical center improving diagnostic accuracy, a bank enhancing fraud detection, and tech companies refining customer service models, all learning from each other's specialized domains without exposing proprietary data.
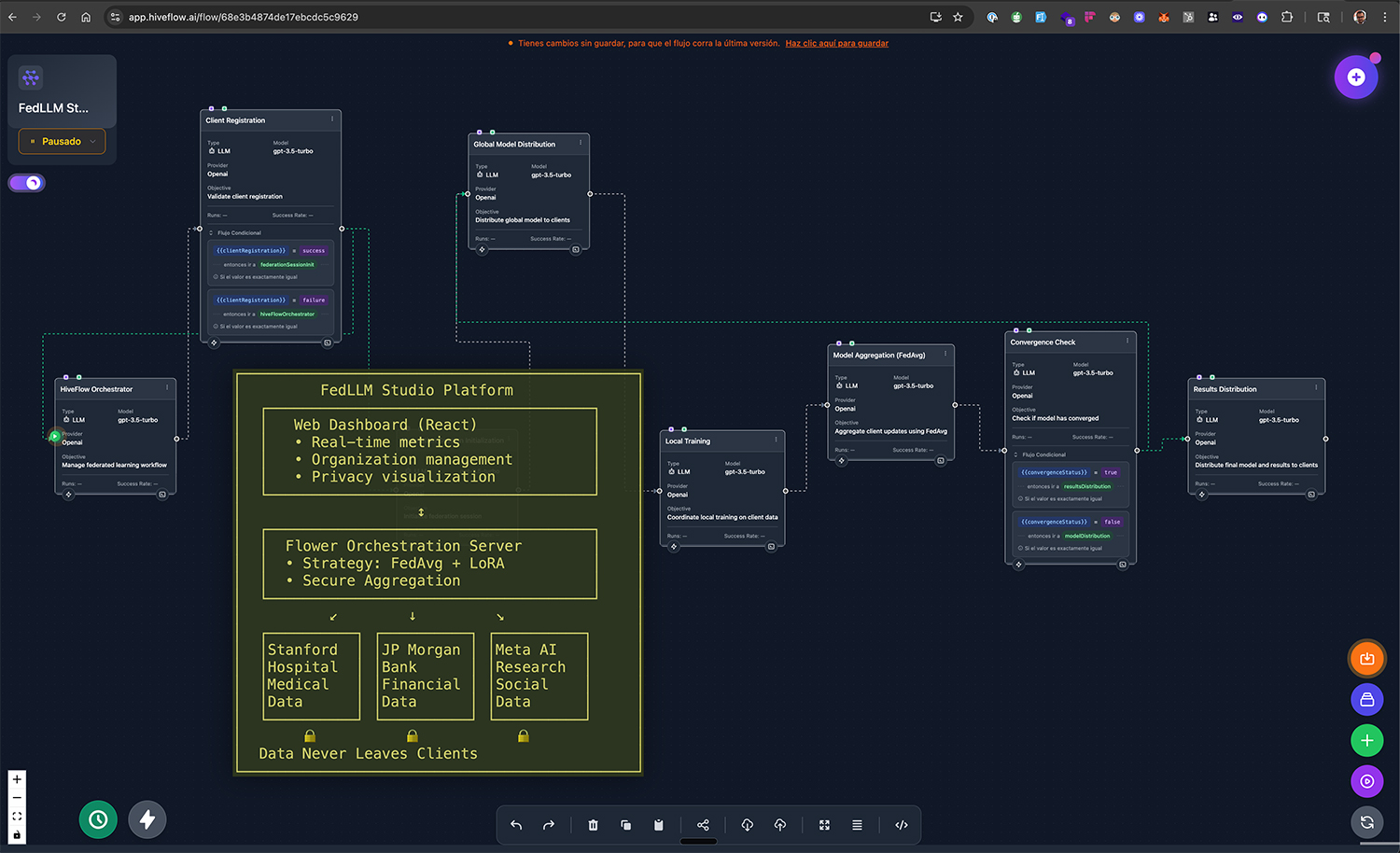
Hiveflow serves as the intelligent orchestration layer, coordinating federation workflows, managing client lifecycle, and ensuring seamless collaboration between heterogeneous participants. Each simulated client represents a real-world organization with heterogeneous data distributions and computing capabilities. The web-based dashboard provides real-time visualization of federated convergence, privacy metrics, and model performance improvements.
What made this project compelling was demonstrating tangible business value: participants saw 20-35% accuracy improvements in their specialized tasks while maintaining complete data sovereignty. The platform is designed as enterprise-ready SaaS, with multi-tenant architecture and compliance-by-design for GDPR and HIPAA requirements.
FedLLM Studio represents a vision where AI advancement doesn't require data centralization, where privacy and collaboration aren't opposing forces, but complementary principles enabling the next generation of trustworthy AI systems.
FedReRank - Federated Reranking for RAG systems
By Rohan Bansal
Federated RAG is a privacy-aware, federated Retrieval-Augmented Generation system for medical question answering. Multiple clients each host their own subset of medical corpora (e.g., textbooks) and build local FAISS indices. When a user asks a question, the Flower-based server broadcasts it to all clients. Each client retrieves top-k relevant passages locally and returns only results (not raw datasets). The server merges responses (RRF or score sort), optionally re-ranks with a lightweight learned reranker, and then generates an answer using an LLM.
Training a re-ranker with Flower enables you to build a federated learning pipeline for ranking tasks without centralizing data. In a federated setup, multiple clients each fine-tune the shared model locally on their labeled ranking data—using pairwise or listwise ranking losses—and then send model updates to a central Flower server, which aggregates them (e.g., via FedAvg) to form an improved global model. This process repeats over several federated rounds, allowing the global reranker to learn from distributed, privacy-preserved data. Once trained, the global model can be deployed to rerank retrieved candidates for new queries, improving search or retrieval quality across all clients.
For my project, I used the bioasq dataset, which I sharded across multiple Flower clients. For my LLM, I used GPT- 4 using the OpenAI APIs. More details on Github.
Federated Learning for Poultry Disease Detection
By Tien-Yu Chi
We set out to solve a very down-to-earth problem: how to detect poultry diseases early, using chicken droppings images. With more than 33 billion chickens worldwide, outbreaks spread fast, threaten food security, and force farmers into costly culling. Fecal image analysis can reveal illness, but centralizing this data is difficult. It’s labor-intensive, raises privacy concerns, and every farm has its own unique conditions.
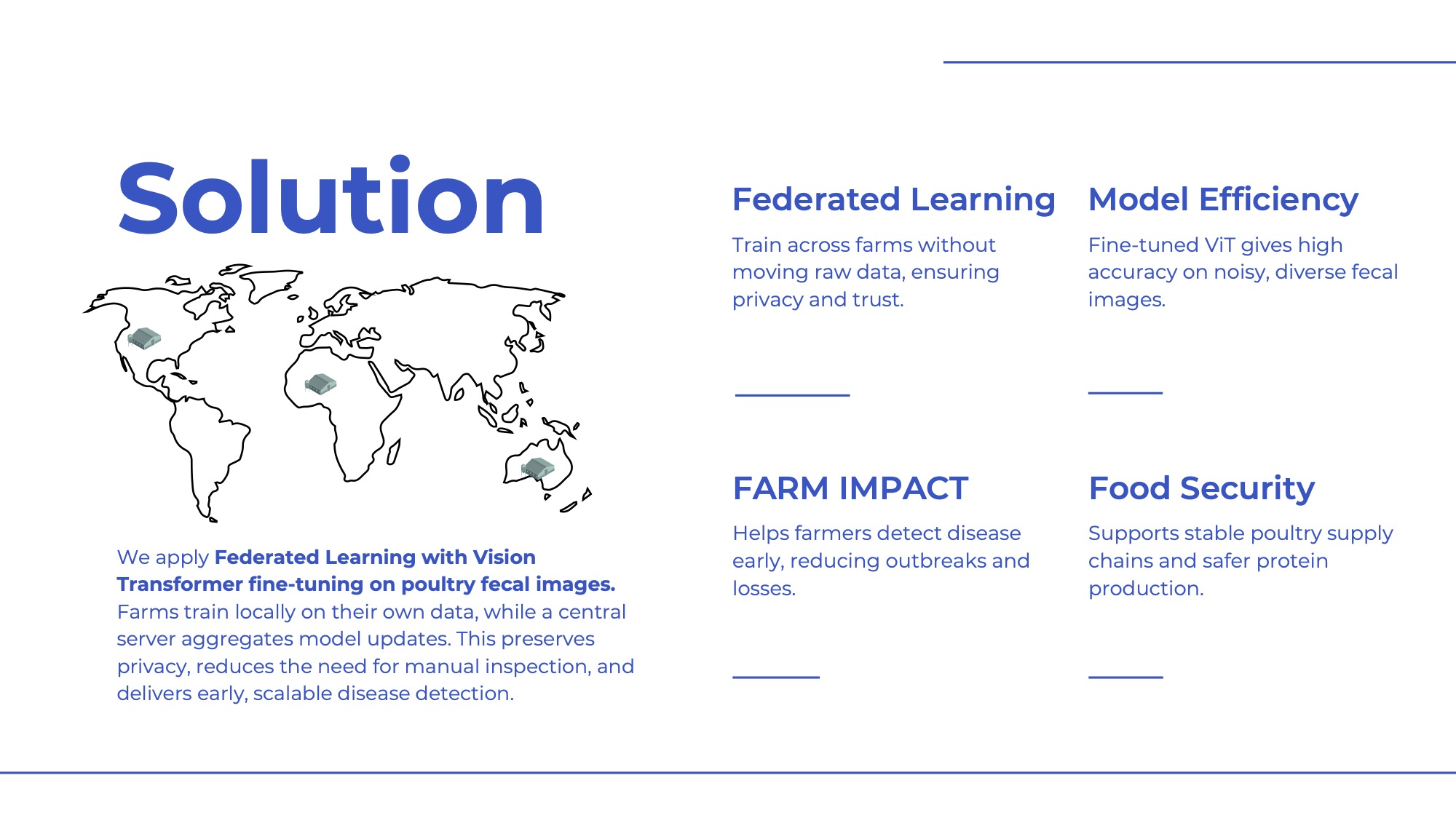
Our solution was to apply federated learning with a fine-tuned Vision Transformer (ViT). Instead of pooling raw fecal images, each farm trains locally on its own data, and only model updates are shared with a central server. This preserves privacy, respects farm diversity, and still produces a shared, stronger model. In a Flower simulated setup with five farms, we tested two tasks:
- Binary classification (healthy vs. unhealthy droppings): federated learning achieved 96.3% accuracy, matching centralized training and outperforming single-farm models (as low as 89.8%).
- Four-class classification (Cocci, Healthy, NCD, Salmonella): the federated model reached 83.3% accuracy, demonstrating strong performance even with noisy, diverse fecal samples.
This approach shows how decentralized AI can help farmers detect disease earlier, reduce waste, and secure more stable poultry supply chains. All by turning an unglamorous but vital dataset (chicken droppings) into a tool for global food security.
Dermacheck, FL-powered skin lesions analysis on your phone
By Jack Hu
My journey started with equal parts excitement and uncertainty. I’d actually gotten off the waitlist the morning of the event, with little preparation and just a cursory glance at federated learning. I spent the first couple of hours bouncing around half-formed ideas with spectators and builders alike until something clicked: what if we could use AI to help detect skin cancer early, while keeping sensitive medical images private?
Skin cancer is the most common form of cancer in the US, affecting 1 in 5 Americans. More than two people die every hour from it, yet when detected early, the 5-year survival rate is 99%+. That contrast between how common and how preventable it is became the spark for my project at the Flower Hackathon.
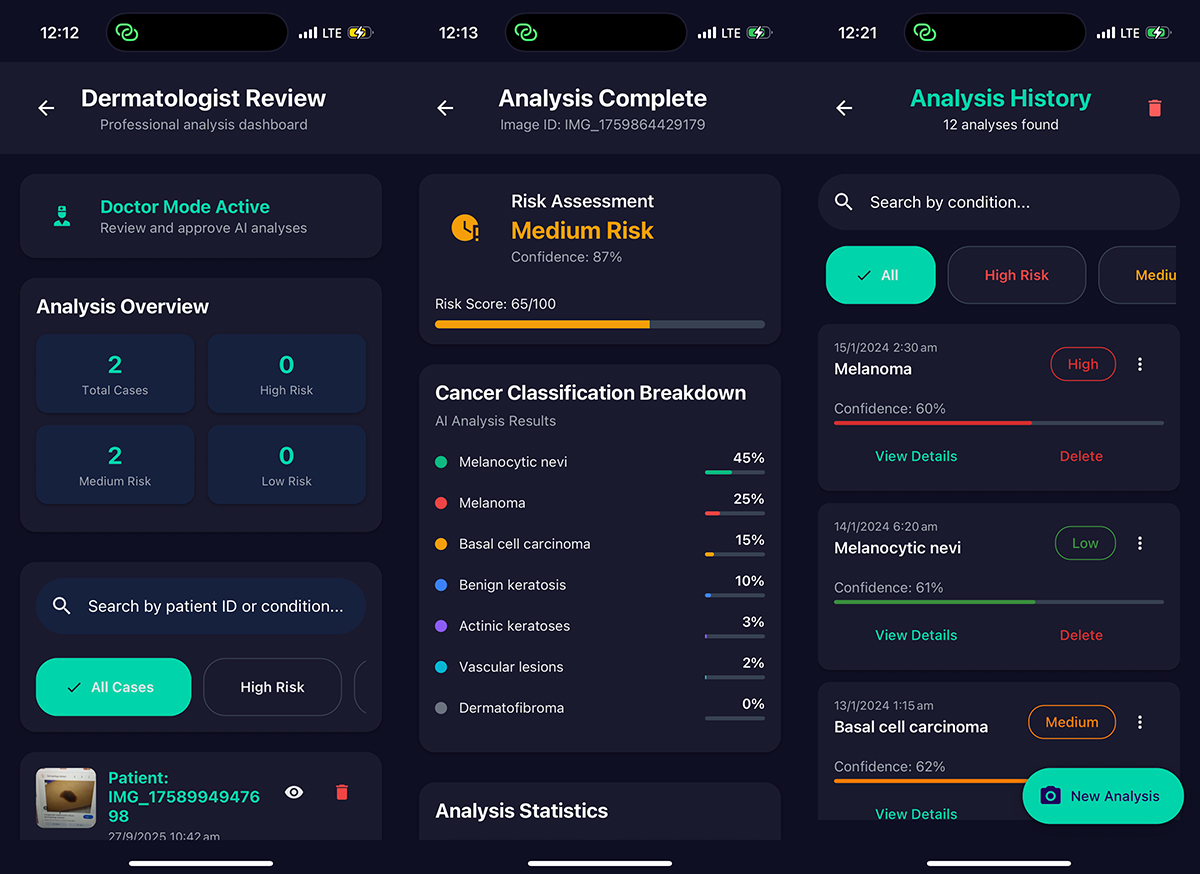
Over the following hours I built a Dermacheck, a mobile app that allows users to check skin lesions in just 3 clicks, receive instant AI-driven analysis, and have results cross referenced with dermatologists to create a two-sided system for generating more high quality annotated data - doctors can generate new revenue opportunities, and users can gain peace of mind. Using an ensemble model fine-tuned on DermaMNIST, and integrating Flower's federated learning framework, the app enables collaborative training across devices without centralizing data. Beyond the code, what made the experience special was the community - meeting other founders and engineers pushing the boundaries of decentralized AI.
The Netflix of Federated Learning: Streaming Your Data with Flower & HTJ2K
By Adway Kanhere
Federated learning promised to democratize AI by distributing computation across devices. There's just one problem: We still have the data bottleneck.
Consider a remote medical clinic where connectivity is uncertain; the satellite passing overhead with only seconds to transmit, or the edge device constrained by storage limitations. Traditional approaches like PNG, JPEG formats, demanding heavy file I/O, create crushing overheads for setting up federations in these resource-constrained participants. This work reimagines this constraint through codec-FL co-design, integrating HTJ2K (High Throughput JPEG2000) compression with Flower's federation framework. By doing so, we attack the data bottleneck head-on by treating data like Netflix treats video: stream it, don't download it. This allows clients to train on compressed bytestreams in real-time. No heavy file I/O. No waiting for gigabytes to download. Just immediate, bandwidth-efficient training.
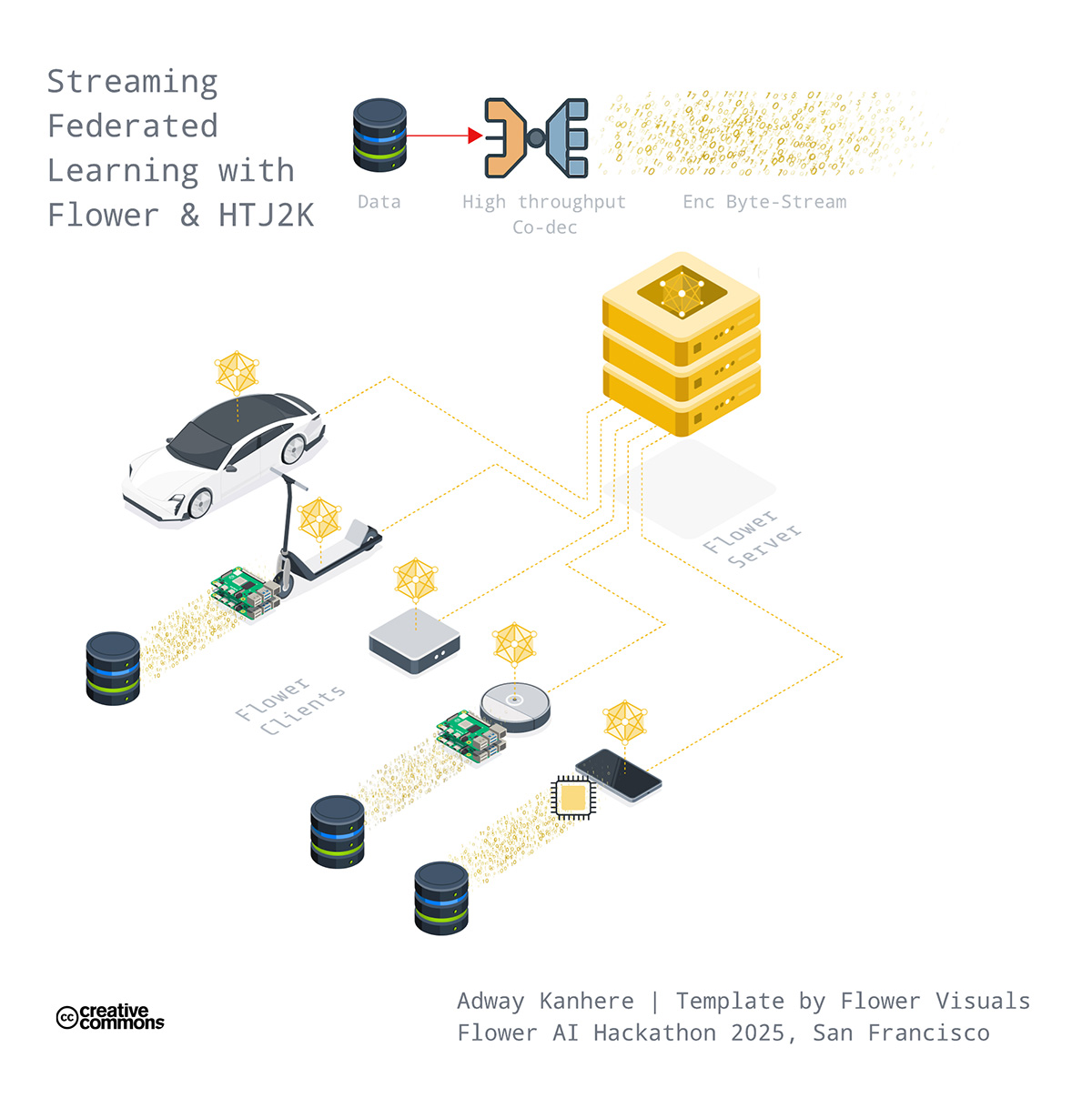
During the live demonstration, we validated two scenarios of cross-domain applicability: medical imaging with nnUNet2D, and satellite imagery classification from EuroSAT, with future extensibility to autonomous driving videos.
Beyond accessibility, HTJ2K's progressive streaming enables priority-based data transmission: the most critical image regions or samples can be transmitted first, essential for high-stakes scenarios where communication windows are brief or uncertain. A remote medical facility can begin training on diagnostically relevant image data even if connectivity drops, and satellite nodes can be made to maximize learning during limited transmission passes in orbit.
Streaming high-throughput compressed data directly into FL orchestration can make FL more inclusive, accelerating global collaborations across healthcare, earth observation, and autonomous systems.