Differential Privacy (confidentialité différentielle)¶
L’information contenue dans les ensembles de données comme les soins de santé, les transactions financières, les préférences des utilisateurs, etc., est précieuse et a le potentiel pour des percées scientifiques et fournit des informations importantes métier. Cependant, ces données sont également sensibles et il existe un risque de compromettre la vie privée individuelle.
Les méthodes traditionnelles comme l’anonymisation seule ne fonctionneraient pas car d’attaques comme Re-identification et Liaison des Données. C’est là que la privacité différentielle entre en jeu. Elle fournit la possibilité d’analyser les données tout en garantissant la vie privée individuelle.
Differential Privacy (confidentialité différentielle)¶
Imaginez deux ensembles de données qui sont identiques sauf pour un seul enregistrement (par exemple, les données d’Alice). La Privacité Différentielle (DP) garantit que toute analyse (M), comme le calcul du revenu moyen, produira des résultats presque identiques pour les deux ensembles de données (O et O” seraient similaires). Cela préserve les modèles de groupe tout en obscurcissant les détails individuels, ce qui garantit que l’information individuelle reste cachée dans la foule.
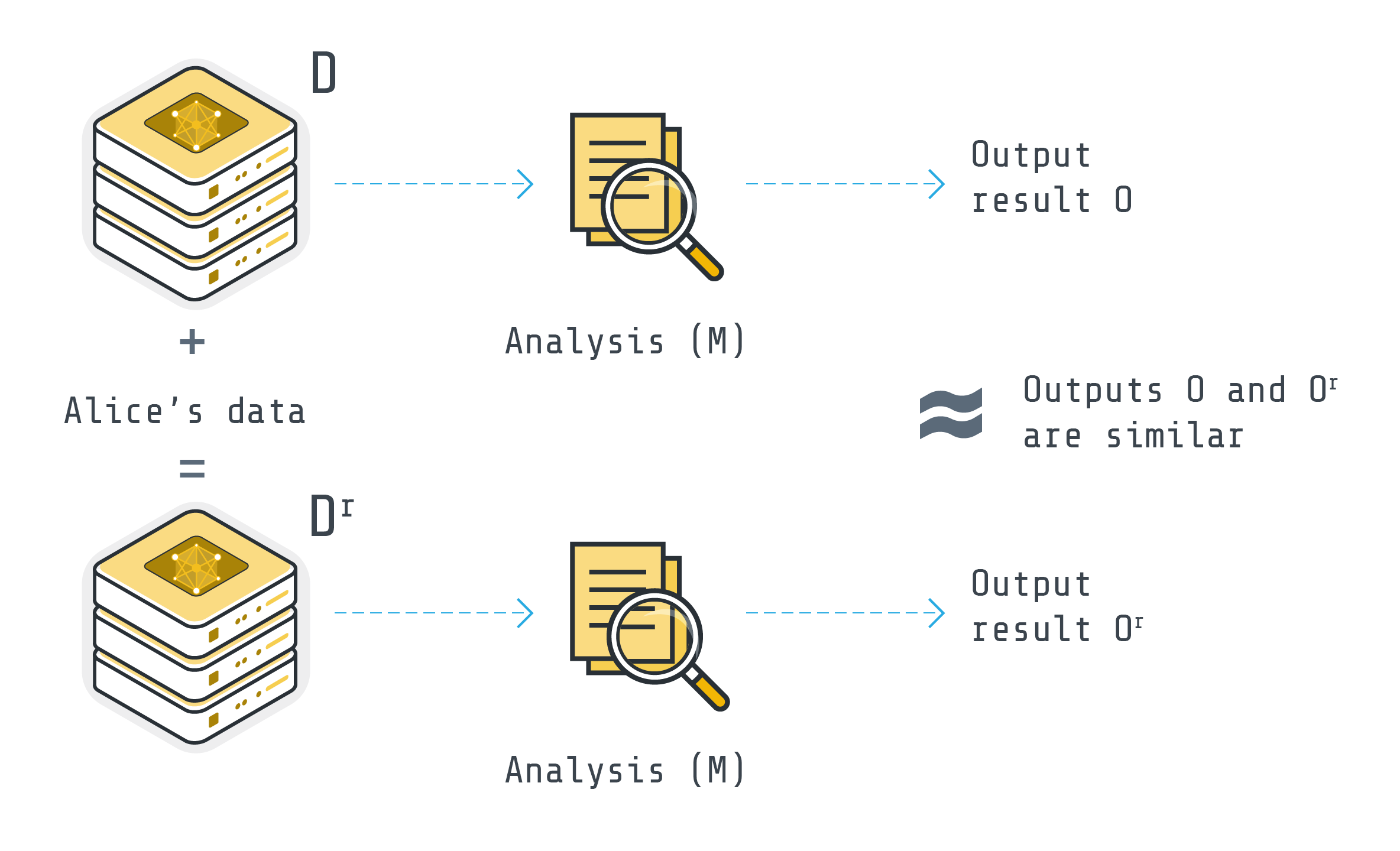
L’un des mécanismes les plus couramment utilisés pour atteindre le DP est d’ajouter suffisamment de bruit dans la sortie de l’analyse pour masquer la contribution de chaque individu dans les données tout en conservant l’exactitude globale de l’analyse.
Définition formelle¶
La confidentialité différentielle (DP) fournit des garanties statistiques contre l’information que peut inférer un adversaire à travers la sortie d’un algorithme aléatoire. Elle fournit une limite supérieure inconditionnelle sur l’influence d’un seul individu sur la sortie de l’algorithme en ajoutant du bruit [1]. Un mécanisme aléatoire M fournit une confidentialité différentielle (DP) si pour tout deux bases de données voisines, D \(\epsilon\) et D \(\delta\), qui diffèrent seulement par un seul enregistrement, et pour tous les résultats possibles S ⊆ plage(A):
Le paramètre \(\epsilon\), également appelé budget de confidentialité, est une mesure de perte de confidentialité. Il contrôle également le compromis entre confidentialité et utilité ; les valeurs \(\epsilon\) plus basses indiquent des niveaux d’information plus élevés mais sont susceptibles de réduire l’utilité ainsi que. Le paramètre \(\delta\) prend en compte une petite probabilité pour laquelle la limite supérieure \(\epsilon\) ne tient pas. La quantité de bruit nécessaire pour atteindre la confidentialité différentielle est proportionnelle à la sensibilité de la sortie, qui mesure le changement maximum dans la sortie due à l’inclusion ou à la suppression d’un seul enregistrement.
Confidentialité différentielle dans l’apprentissage automatique¶
Le DP peut être utilisé dans l’apprentissage automatique pour préserver la confidentialité des données d’entraînement. Les algorithmes d’apprentissage automatique à confidentialité différentielle sont conçus de manière à empêcher l’algorithme d’apprendre toute information spécifique sur les points de données individuels et à empêcher le modèle de révéler des informations sensibles. En fonction de la phase à laquelle du bruit est introduit, diverses méthodes existent pour appliquer le DP aux algorithmes d’apprentissage automatique. Une approche consiste à ajouter du bruit aux données d’entraînement (soit aux caractéristiques ou étiquettes), tandis qu’une autre méthode implique l’injection de bruit dans les gradients de la fonction de perte pendant l’entraînement du modèle. De plus, ce bruit peut être incorporé dans la sortie du modèle.
Confidentialité différentielle dans l’apprentissage fédéré¶
L’apprentissage fédéré est une approche de minimisation des données qui permet à plusieurs parties d’entraîner un modèle sans partager leurs données brutes. Cependant, l’apprentissage fédéré introduit également de nouveaux défis en matière de confidentialité. Les mises à jour du modèle entre les parties et le serveur central peuvent divulguer des informations sur les données locales. Ces fuites peuvent être exploitées par des attaques telles que l’inférence d’appartenance, l’inférence de propriété ou l’inversion du modèle.
Le DP peut jouer un rôle crucial dans l’apprentissage fédéré pour fournir une confidentialité aux données des clients.
En fonction de la granularité de la prestation de confidentialité ou de l’emplacement d’ajout de bruit, différentes formes de DP existent dans l’apprentissage fédéré. Dans cet expliquer, nous nous concentrons sur deux approches de mise en œuvre du DP dans l’apprentissage fédéré basées sur l’emplacement où le bruit est ajouté : au serveur (aussi appelé centre) ou au client (aussi appelé local).
Confidentialité différentielle centrale : Le DP est appliqué par le serveur et l’objectif est de prévenir que le modèle agrégé divulgue des informations sur les données de chaque client.
Confidentialité différentielle locale : Le DP est appliqué du côté du client avant d’envoyer toute information au serveur et l’objectif est de prévenir que les mises à jour envoyées au serveur ne divulguent aucune information sur les données du client.
Confidentialité différentielle centrale¶
Dans cette approche, également connue sous le nom de DP au niveau utilisateur, le serveur central est responsable d’ajouter du bruit aux paramètres globalement agrégés. Il convient de noter que la confiance dans le serveur est requise.
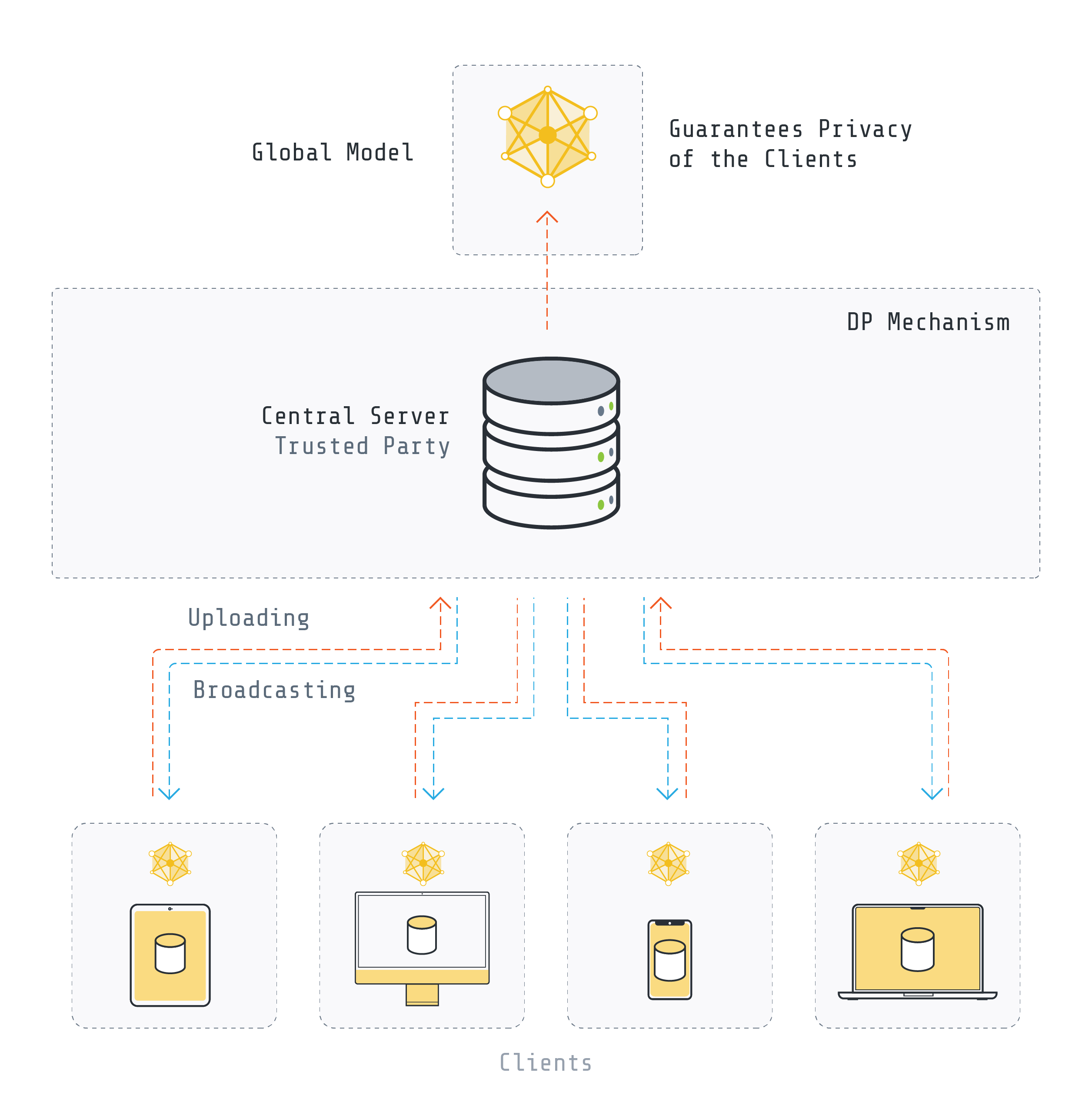
Bien qu’il existe diverses façons d’implémenter le DP central dans l’apprentissage fédéré, nous concentrons sur les algorithmes proposés par [2] et [3]. L’approche globale consiste à couper les mises à jour du modèle transmises par les clients et à ajouter une certaine quantité de bruit au modèle agrégé. Dans chaque itération, un ensemble aléatoire de clients est choisi avec une probabilité spécifique pour l’entraînement. Chaque client effectue un entraînement local sur ses propres données. La mise à jour de chaque client est ensuite coupée par une certaine valeur S (sensibilité S). Cela limiterait l’impact de tout client individuel, ce qui est crucial pour la confidentialité et souvent bénéfique pour la robustesse. Une approche courante pour atteindre cela consiste à restreindre la norme L2 des mises à jour du modèle des clients, en s’assurant que les mises à jour plus importantes sont échelonnées pour s’adapter à la norme S.
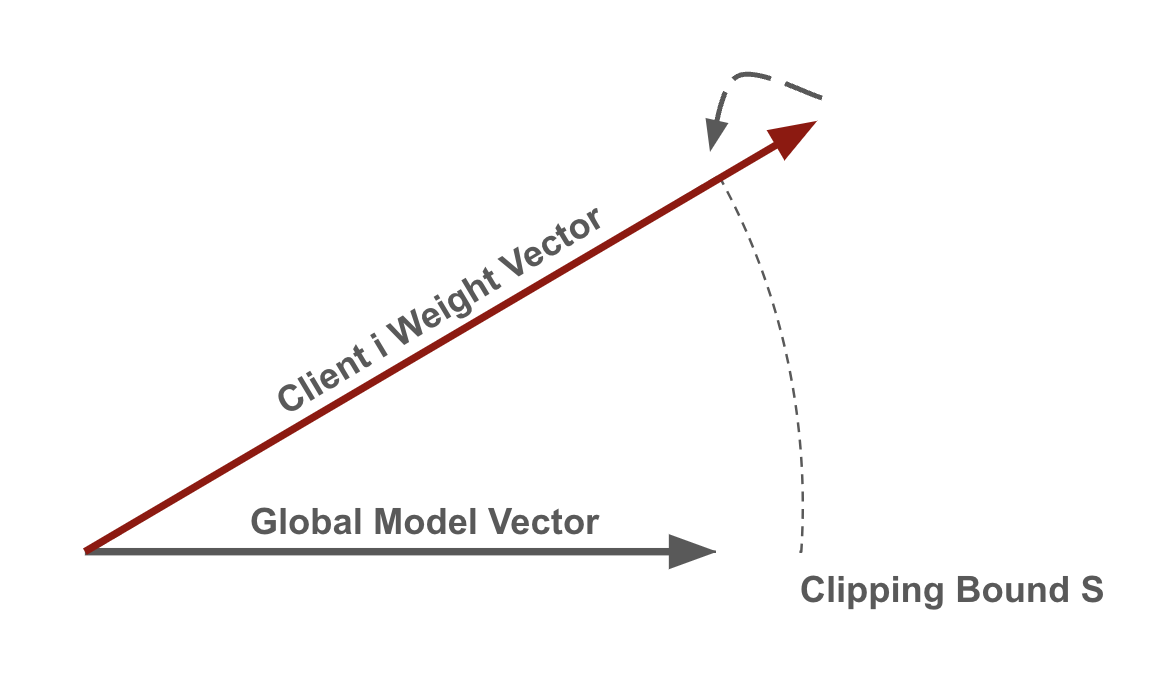
Après cela, le mécanisme gaussien est utilisé pour ajouter du bruit afin de déformer la somme de toutes les mises à jour des clients. La quantité de bruit est échelonnée en fonction de la valeur de sensibilité pour obtenir une garantie de confidentialité. Le mécanisme gaussien est utilisé avec un bruit échantillonné à partir de N (0, σ²) où σ = ( noise_scale * S ) / (nombre de clients échantillonnés).
Clipping¶
Il existe deux formes de coupage couramment utilisées dans le DP central : Coupage Fixe et Coupage Adaptatif.
Coupage Fixe : Un seuil fixe est défini pour l’amplitude des mises à jour des clients. Toute mise à jour dépassant ce seuil est coupée jusqu’à la valeur de seuil.
Coupage Adaptatif : Le seuil de coupage s’ajuste dynamiquement en fonction de la distribution observée des mises à jour [4]. Cela signifie que la valeur de coupage est ajustée pendant les tours en fonction du quantile de la distribution de norme des mises à jour.
Le choix entre le coupage fixe et adaptatif dépend de divers facteurs tels que les exigences de confidentialité, la distribution des données, la complexité du modèle et d’autres.
Confidentialité locale¶
Dans cette approche, chaque client est responsable de l’exécution de la DP. La DP locale évite la nécessité d’un agrégateur entièrement confiant, mais il convient de noter que la DP locale entraîne une diminution de précision mais une meilleure confidentialité par rapport au DP central.
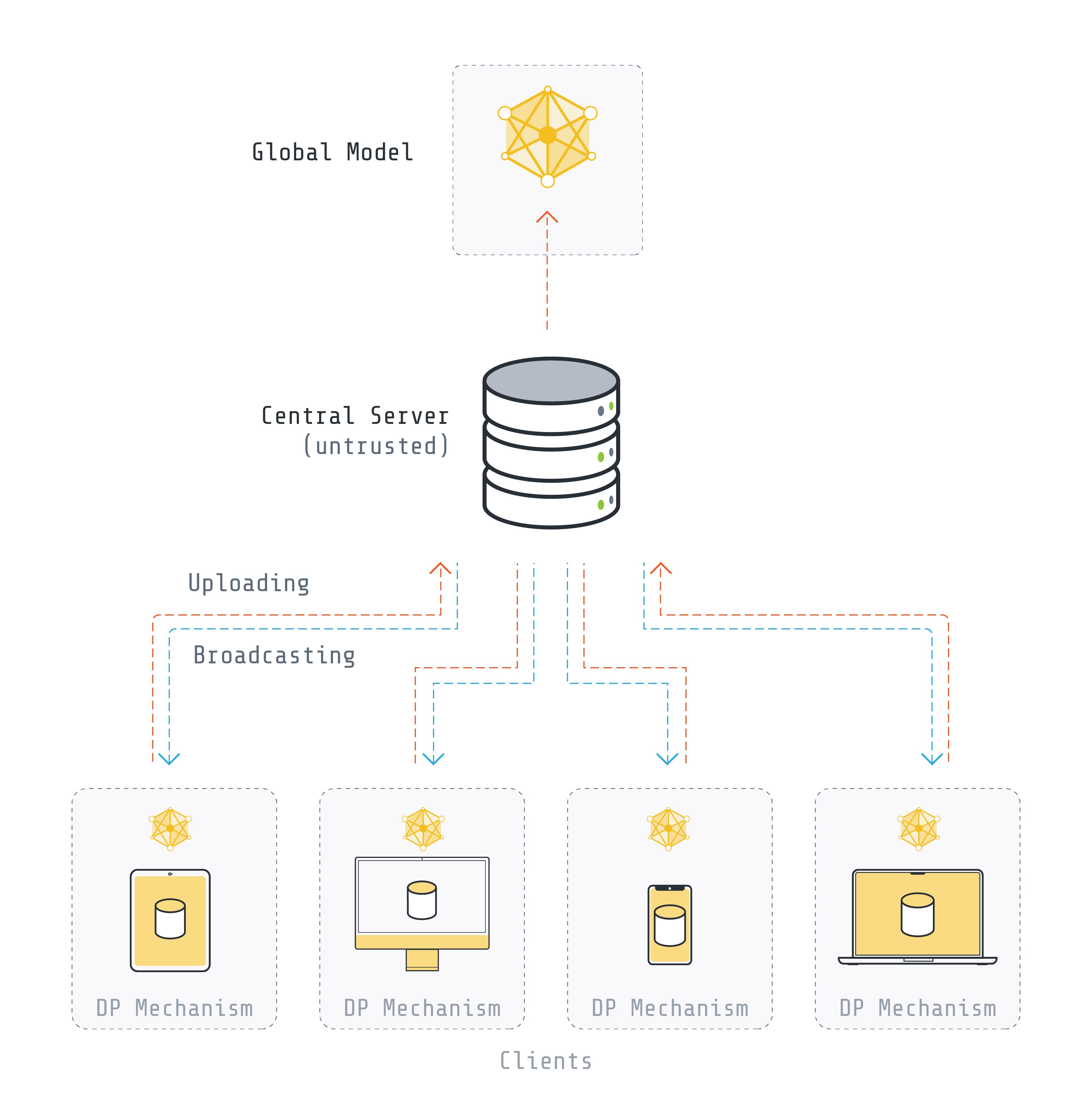
Dans cet expliquer, nous nous concentrons sur deux formes d’atteindre la DP locale :
Chaque client ajoute du bruit aux mises à jour locales avant de les envoyer au serveur. Pour atteindre le (\(\epsilon\), \(\delta\))-DP, en considérant la sensibilité du modèle local à être ∆, un bruit gaussien est appliqué avec une échelle de bruit de σ où :
Chaque client ajoute du bruit aux gradients du modèle pendant l’entraînement local (DP-SGD). Plus spécifiquement, dans cette approche, les gradients sont tronqués et une quantité de bruit calibré est injectée dans les gradients.
Veuillez noter que ces deux approches fournissent la confidentialité à différents niveaux.
References:
[1] Dwork et al. Les fondements algorithmiques de la confidentialité différentielle.
[2] McMahan et al. Apprentissage des modèles de langage récurrents différentiellement privés.
[3] Geyer et al. Apprentissage fédéré différentiellement privé : une perspective au niveau du client.
[4] Galen et al. Apprentissage différentiellement privé avec clipping adaptatif.