Flower
Summit 2021
All good things come to an end. The Flower Summit 2021 is over. We thank everyone who participated especially our speakers but also big thanks to everyone who listened and asked questions. For those of you who missed some of the session do not despair! You just have to scroll a little bit further down. Don't forget to join the Flower Community Slack before you do so!


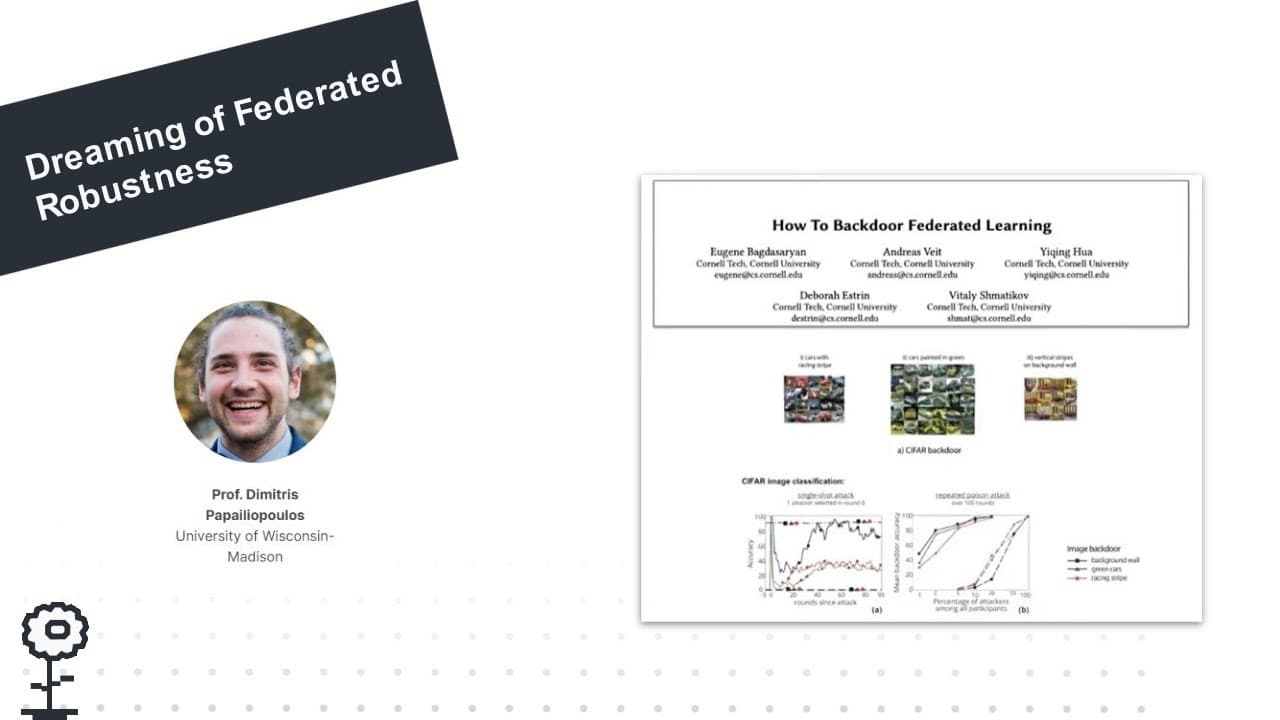
Keynote: Dreaming of Federated Robustness: Inherent Barriers and Unavoidable Tradeoffs
A defining trait of federated learning is the presence of heterogeneity, i.e., that data and systems characteristics may differ significantly across the network. In this talk I show that the challenge of heterogeneity pervades the machine learning process in federated settings, affecting issues such as optimization, modeling, and fairness. In terms of optimization, I discuss distributed optimization methods that offer robustness to systems and statistical heterogeneity. I then explore the role that heterogeneity plays in delivering models that are accurate and fair to all users/devices in the network. Finally, I consider scenarios where heterogeneity may in fact afford benefits to distributed learning, through recent work in one-shot federated clustering.

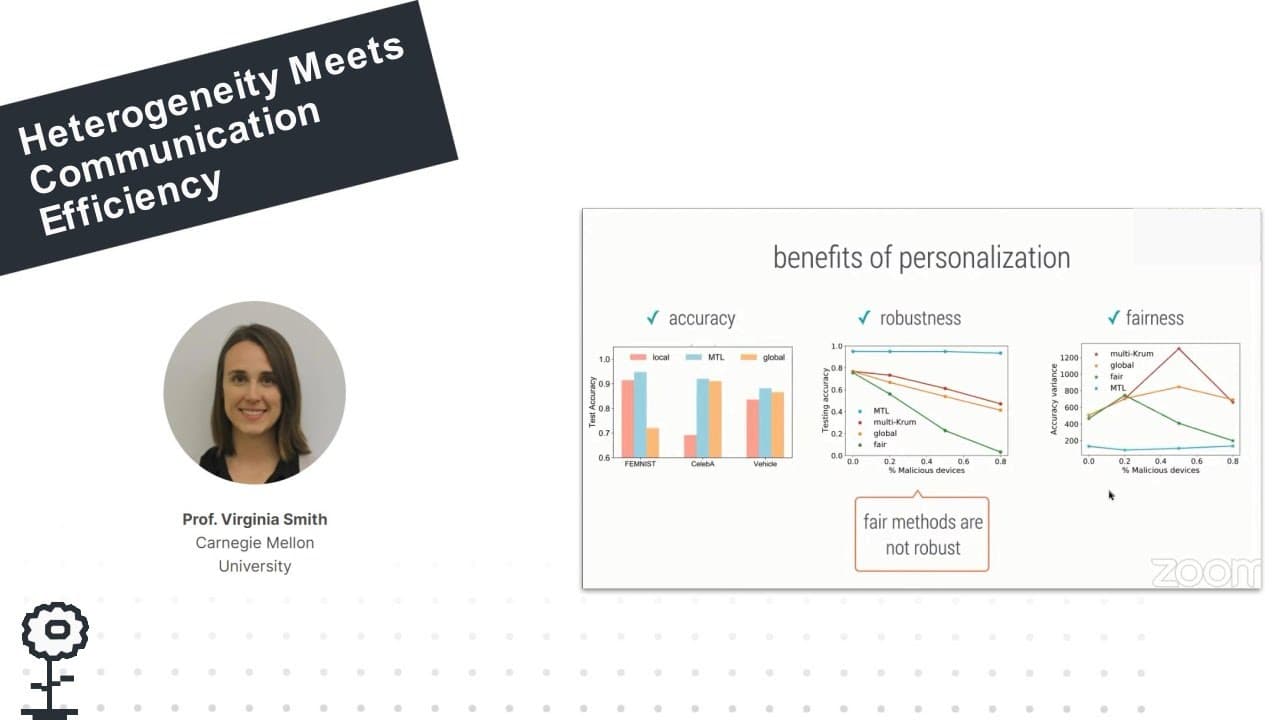
Keynote: Heterogeneity Meets Communication-Efficiency: Challenges and Opportunities
Due to its decentralized nature, federated learning lends itself to adversarial attacks in the form of backdoors during training. A range of attacks has been introduced in the literature, but also defense mechanisms, and it is currently an open question whether FL systems can be made robust against malicious attackers. In this work, we provide evidence to the contrary. We first establish that, robustness to backdoors implies model robustness to adversarial examples, a major open problem in itself. Furthermore, we show that even detecting a backdoor is unlikely to be possible in polynomial time. We then present a new family of attacks: edge-case backdoors. An edge-case backdoor forces a model to misclassify on seemingly easy inputs that are however unlikely to be part of the training, or test data, i.e., they live on the tail of the input distribution. We explain how these edge-case backdoors can lead to unsavory failures and may have serious repercussions on fairness, and exhibit that with careful tuning at the side of the adversary one can insert them across a big range of machine learning tasks.