
EXtreme Gradient Boosting (XGBoost) is a robust and efficient implementation of gradient-boosted decision tree (GBDT), that maximises the computational boundaries for boosted tree methods. It's primarily designed to enhance both the performance and computational speed of machine learning models. In XGBoost, trees are constructed concurrently, unlike the sequential approach taken by GBDT.
Often, for tabular data on medium-sized datasets with fewer than 10k training examples, XGBoost even surpasses the results of deep learning techniques!
Why federated XGBoost?
Indeed, as the demand for data privacy and decentralized learning grows, there's an increasing requirement to implement federated XGBoost systems for specialized applications, like survival analysis and financial fraud detection.
Federated learning (FL) ensures that raw data remains on the local device, making it an attractive approach for sensitive domains where data security and privacy are paramount. Given the robustness and efficiency of XGBoost, combining it with federated learning offers a promising solution for these specific challenges.
In this blogpost, you will learn how to train a federated XGBoost model with bagging aggregation strategy. The complete examples can be found on GitHub (quickstart example, comprehensive example).

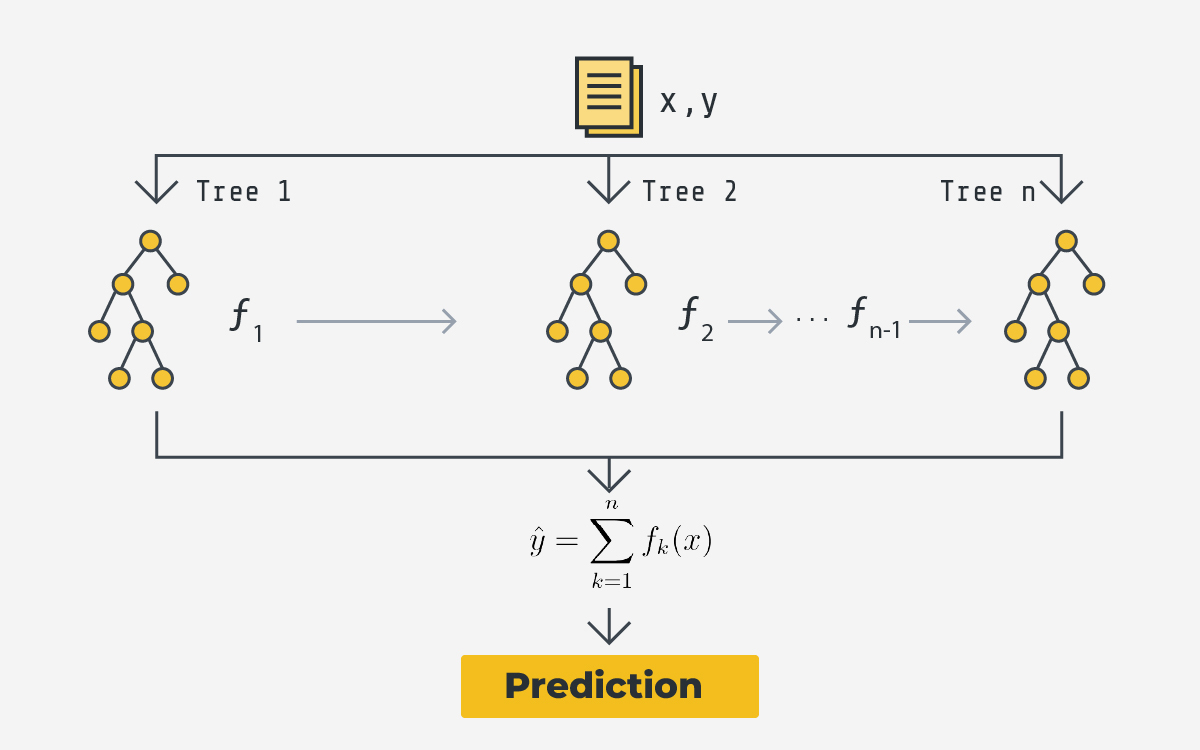
Overview of federated XGBoost
A typical federated training process for XGBoost includes four steps (see the diagram above):
- At the first round, the server samples certain clients participating in the training, and sends them an initialised tree configuration (i.e. global model). Note that the global model is empty at the 1st round.
- The selected clients construct their own trees (i.e. training) with gradient-boosting based on its own data.
- After the local trees' construction completes, only the updated trees will be sent back to the server.
- The server aggregates the received clients' trees to generate a new global model (tree ensemble). The new global model will be transmitted to clients in the next round.
Tree-based bagging aggregation
Bagging (bootstrap) aggregation is an ensemble meta-algorithm in machine learning, used for enhancing the stability and accuracy of machine learning algorithms. Here, we leverage this algorithm for XGBoost trees.
Specifically, each client is treated as a bootstrap by random subsampling (data partitioning in FL). At each FL round, all clients boost a number of trees (in this example, 1 tree) based on the local bootstrap samples. Then, the clients' trees are aggregated on the server, and concatenates them to the global model from previous round. The aggregated tree ensemble is regarded as a new global model.
This way, let's consider a scenario with M clients. Given FL round R and full client participation, the bagging models consist of (M * R) trees.
Running the example
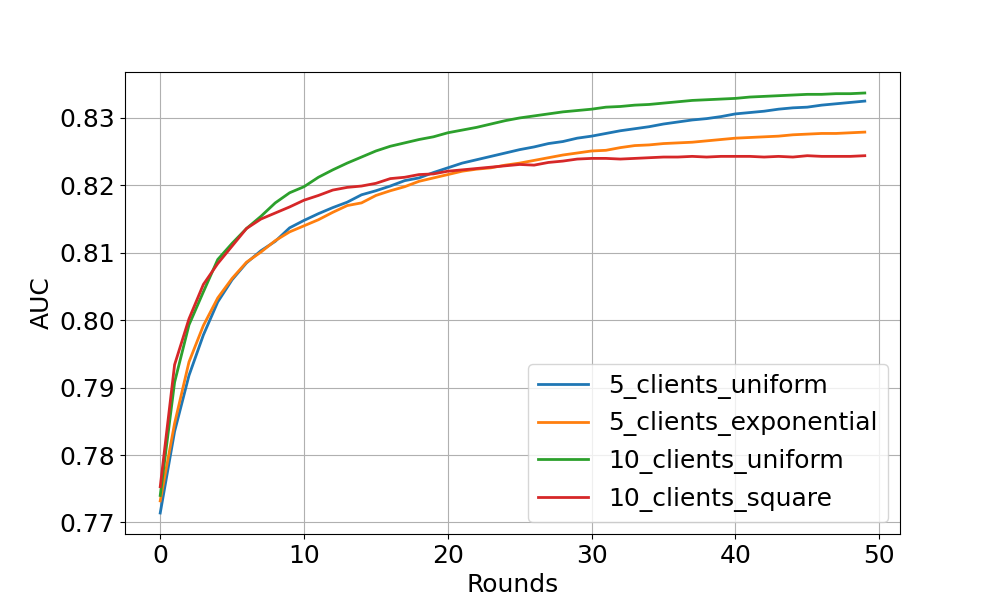
The example available on GitHub runs federated XGBoost training on HIGGS dataset. One can specify experimental setups via Flower Datasets, with varying numbers of clients and a range of client data distributions, including uniform, linear, square, and exponential. The figure above shows the tested AUC performance over FL rounds on 4 settings. One can see that all settings obtain stable performance boost over FL rounds (especially noticeable at the start of training). As expected, uniform setup shows higher AUC values (beyond 83% at the end) than square/exponential distribution.
Look at the code and tutorial for a detailed explanation. Feel free to explore more interesting setups with federated XGBoost!