FedDebug: Systematic Debugging for Federated Learning Applications¶

[!NOTE] If you use this baseline in your work, please remember to cite the original authors of the paper as well as the Flower paper.
Paper: dl.acm.org/doi/abs/10.1109/ICSE48619.2023.00053
Authors: Waris Gill (Virginia Tech, USA), Ali Anwar (University of Minnesota Twin Cities, USA), Muhammad Ali Gulzar (Virginia Tech, USA)
Abstract: In Federated Learning (FL), clients independently train local models and share them with a central aggregator to build a global model. Impermissibility to access clients’ data and collaborative training make FL appealing for applications with data-privacy concerns, such as medical imaging. However, these FL characteristics pose unprecedented challenges for debugging. When a global model’s performance deteriorates, identifying the responsible rounds and clients is a major pain point. Developers resort to trial-and-error debugging with subsets of clients, hoping to increase the global model’s accuracy or let future FL rounds retune the model, which are time-consuming and costly. We design a systematic fault localization framework, FedDebug, that advances the FL debugging on two novel fronts. First, FedDebug enables interactive debugging of realtime collaborative training in FL by leveraging record and replay techniques to construct a simulation that mirrors live FL. FedDebug’s breakpoint can help inspect an FL state (round, client, and global model) and move between rounds and clients’ models seamlessly, enabling a fine-grained step-by-step inspection. Second, FedDebug automatically identifies the client(s) responsible for lowering the global model’s performance without any testing data and labels—both are essential for existing debugging techniques. FedDebug’s strengths come from adapting differential testing in conjunction with neuron activations to determine the client(s) deviating from normal behavior. FedDebug achieves 100% accuracy in finding a single faulty client and 90.3% accuracy in finding multiple faulty clients. FedDebug’s interactive debugging incurs 1.2% overhead during training, while it localizes a faulty client in only 2.1% of a round’s training time. With FedDebug, we bring effective debugging practices to federated learning, improving the quality and productivity of FL application developers.
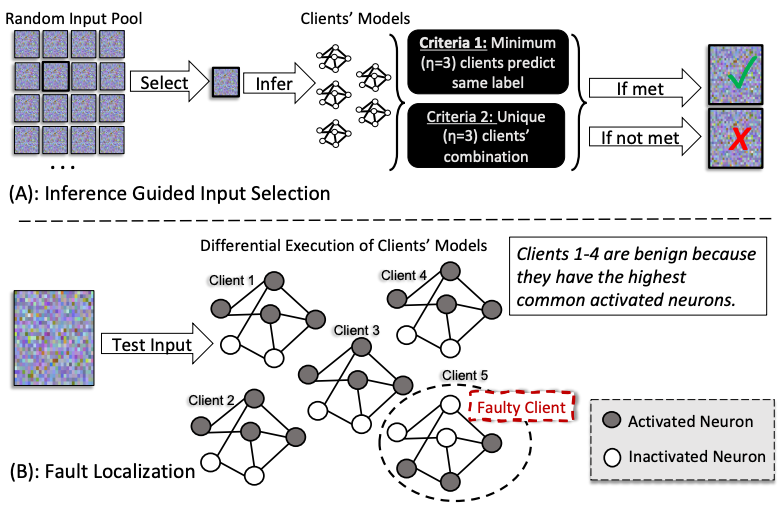
About this baseline¶
What’s implemented: FedDebug is a systematic malicious client(s) localization framework designed to advance debugging in Federated Learning (FL). It enables interactive debugging of real-time collaborative training and automatically identifies clients responsible for lowering global model performance without requiring testing data or labels.
This repository implements the FedDebug technique of localizing malicious client(s) in a generic way, allowing it to be used with various fusion techniques (FedAvg, FedProx) and CNN architectures. You can find the original code of FedDebug here.
Flower Datasets: This baseline integrates flwr-datasets and tested on CIFAR-10 and MNIST datasets. The code is designed to work with other datasets as well. You can easily extend the code to work with other datasets by following the Flower dataset guidelines.
Hardware Setup: These experiments were run on a machine with 8 CPU cores and an Nvidia Tesla P40 GPU.
[!NOTE] This baseline also contains a smaller CNN model (LeNet) to run all these experiments on a CPU. Furthermore, the experiments are also scaled down to obtain representative results of the FedDebug evaluations.
Contributors: Waris Gill (GitHub Profile)
Experimental Setup¶
Task: Image classification, Malicious/Faulty Client(s) Removal, Debugging and Testing
Models: This baseline implements two CNN architectures: LeNet and ResNet. Other CNN models (DenseNet, VGG, etc.) are also supported. Check the conf/base.yaml file for more details.
Dataset: The datasets are partitioned among clients, and each client participates in the training (cross-silo). However, you can easily extend the code to work in cross-device settings. This baseline uses Dirichlet partitioning to partition the datasets among clients for Non-IID experiments. However, the original paper uses quantity-based imbalance approach (niid_bench).
Dataset |
#classes |
#clients |
partitioning method |
|---|---|---|---|
CIFAR-10 |
10 |
10 |
IID and Non-IID |
MNIST |
10 |
10 |
IID and Non-IID |
FL Training Hyperparameters and FedDebug Configuration:
Default training hyperparameters are in conf/base.yaml.
Environment Setup¶
Experiments are conducted with Python 3.10.14. It is recommended to use Python 3.10 for the experiments.
Check the documentation for the different ways of installing pyenv, but one easy way is using the automatic installer:
curl https://pyenv.run | bash # then, don't forget links to your .bashrc/.zshrc
You can then install any Python version with pyenv install 3.10.14 Then, in order to use FedDebug baseline, you’d do the following:
# cd to your feddebug directory (i.e. where the `pyproject.toml` is)
pyenv local 3.10.14
poetry env use 3.10.14 # set that version for poetry
# run this from the same directory as the `pyproject.toml` file is
poetry install
poetry shell
# check the python version by running the following command
python --version # it should be >=3.10.14
This will create a basic Python environment with just Flower and additional packages, including those needed for simulation. Now you are inside your environment (pretty much as when you use virtualenv or conda).
Running the Experiments¶
[!NOTE] You can run almost any evaluation from the paper by changing the parameters in
conf/base.yaml. Also, you can change the resources (per client CPU and GPU) inconf/base.yamlto speed up the simulation. Please check the Flower simulation guide for more details (Flower Framework main).
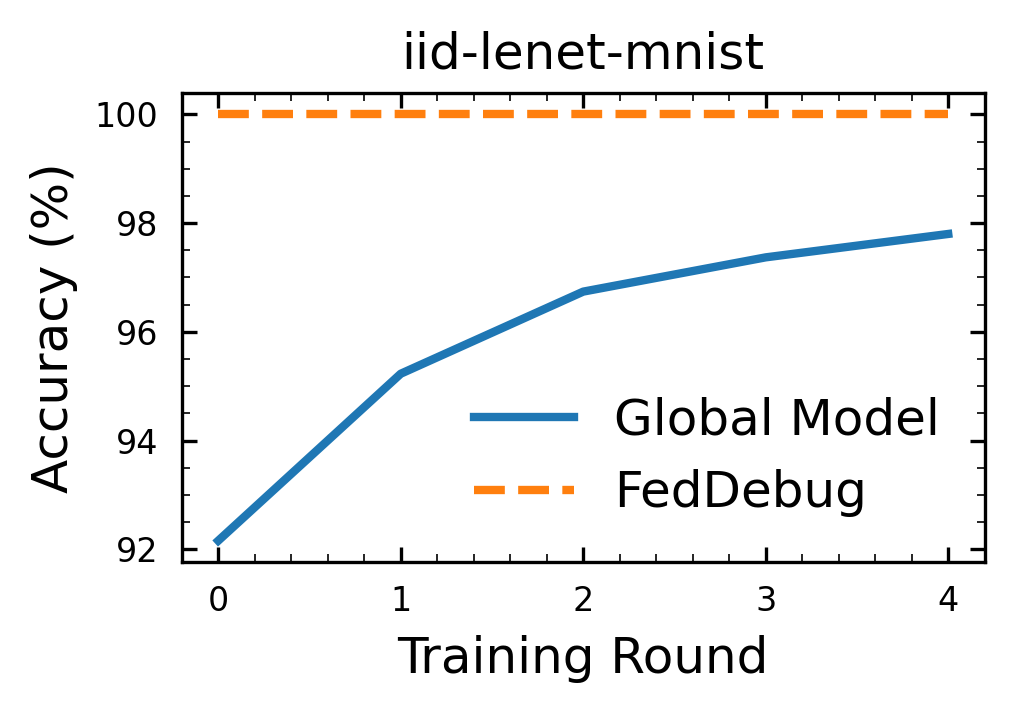
The following command will run the default experimental setting in conf/base.yaml (LeNet, MNIST, with a total of 10 clients, where client-0 is malicious). FedDebug will identify client-0 as the malicious client. The experiment took on average 60 seconds to complete.
python -m feddebug.main device=cpu
Output of the last round will show the FedDebug output as follows:
...
[2024-10-24 12:25:48,758][flwr][INFO] - ***FedDebug Output Round 5 ***
[2024-10-24 12:25:48,758][flwr][INFO] - True Malicious Clients (Ground Truth) = ['0']
[2024-10-24 12:25:48,758][flwr][INFO] - Total Random Inputs = 10
[2024-10-24 12:25:48,758][flwr][INFO] - Predicted Malicious Clients = {'0': 1.0}
[2024-10-24 12:25:48,758][flwr][INFO] - FedDebug Localization Accuracy = 100.0
[2024-10-24 12:25:49,577][flwr][INFO] - fit progress: (5, 0.00015518503449857236, {'accuracy': 0.978, 'loss': 0.00015518503449857236, 'round': 5}, 39.02993568999227)
[2024-10-24 12:25:49,577][flwr][INFO] - configure_evaluate: no clients selected, skipping evaluation
[2024-10-24 12:25:49,577][flwr][INFO] -
[2024-10-24 12:25:49,577][flwr][INFO] - [SUMMARY]
...
It predicts the malicious client(s) with 100% accuracy. Predicted Malicious Clients = {'0': 1.0} means that client-0 is predicted as the malicious client with 1.0 probability. It will also generate a graph iid-lenet-mnist.png as shown below:
FedDebug Diverse Experiment Scenarios¶
Next, we demonstrate FedDebug experiments across key scenarios: detecting multiple malicious clients (Section 5-B), running with various models, datasets, and devices (including GPU), and examining how neuron activation thresholds impact localization accuracy (Section 5-C). Understanding these scenarios will help you adapt FedDebug to your specific needs and evaluate any configuration you wish to explore from the paper.
1. Multiple Malicious Clients¶
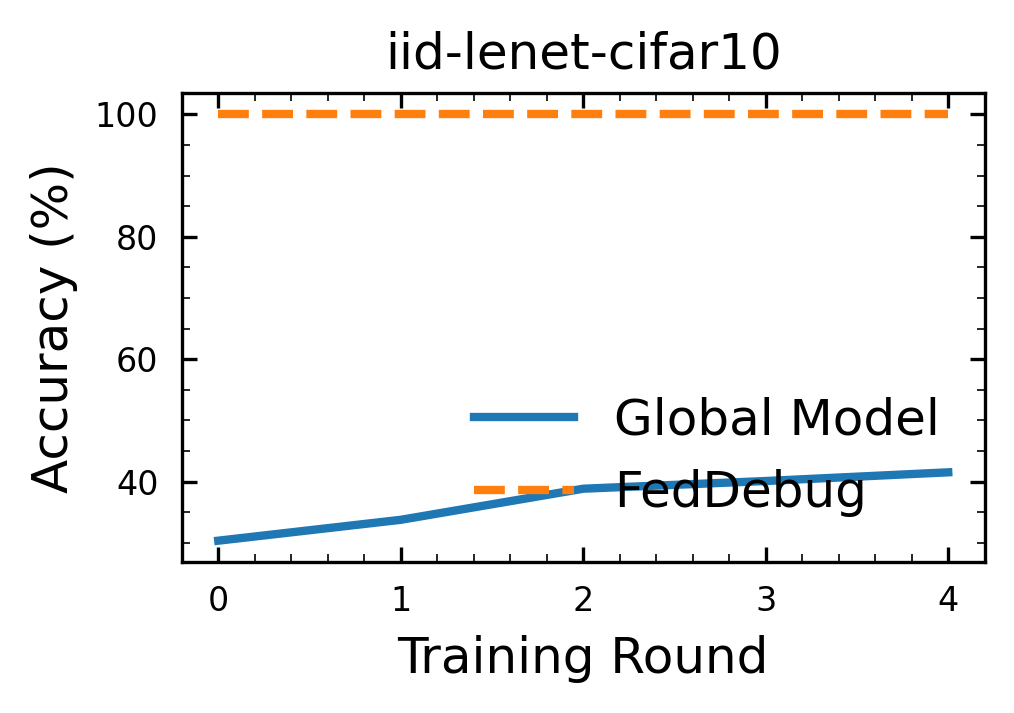
To test the localization of multiple malicious clients, you can change the total_malicious_clients. Total Time Taken: 46.7 seconds.
python -m feddebug.main device=cpu total_malicious_clients=2 dataset.name=cifar10
In this scenario, clients 0 and 1 are now malicious. The output will show the FedDebug output as follows:
...
[2024-10-24 12:28:14,125][flwr][INFO] - ***FedDebug Output Round 5 ***
[2024-10-24 12:28:14,125][flwr][INFO] - True Malicious Clients (Ground Truth) = ['0', '1']
[2024-10-24 12:28:14,125][flwr][INFO] - Total Random Inputs = 10
[2024-10-24 12:28:14,125][flwr][INFO] - Predicted Malicious Clients = {'0': 1.0, '1': 1.0}
[2024-10-24 12:28:14,125][flwr][INFO] - FedDebug Localization Accuracy = 100.0
[2024-10-24 12:28:15,148][flwr][INFO] - fit progress: (5, 0.003398957598209381, {'accuracy': 0.4151, 'loss': 0.003398957598209381, 'round': 5}, 35.81892481799878)
[2024-10-24 12:28:15,148][flwr][INFO] - configure_evaluate: no clients selected, skipping evaluation
[2024-10-24 12:28:15,148][flwr][INFO] -
[2024-10-24 12:28:15,148][flwr][INFO] - [SUMMARY]
...
FedDebug predicts the malicious clients with 100% accuracy. Predicted Malicious Clients = {'0': 1.0, '1': 1.0} means that clients 0 and 1 are predicted as the malicious clients with 1.0 probability. It will also generate a graph iid-lenet-cifar10.png as shown below:
2. Changing the Model and Device¶
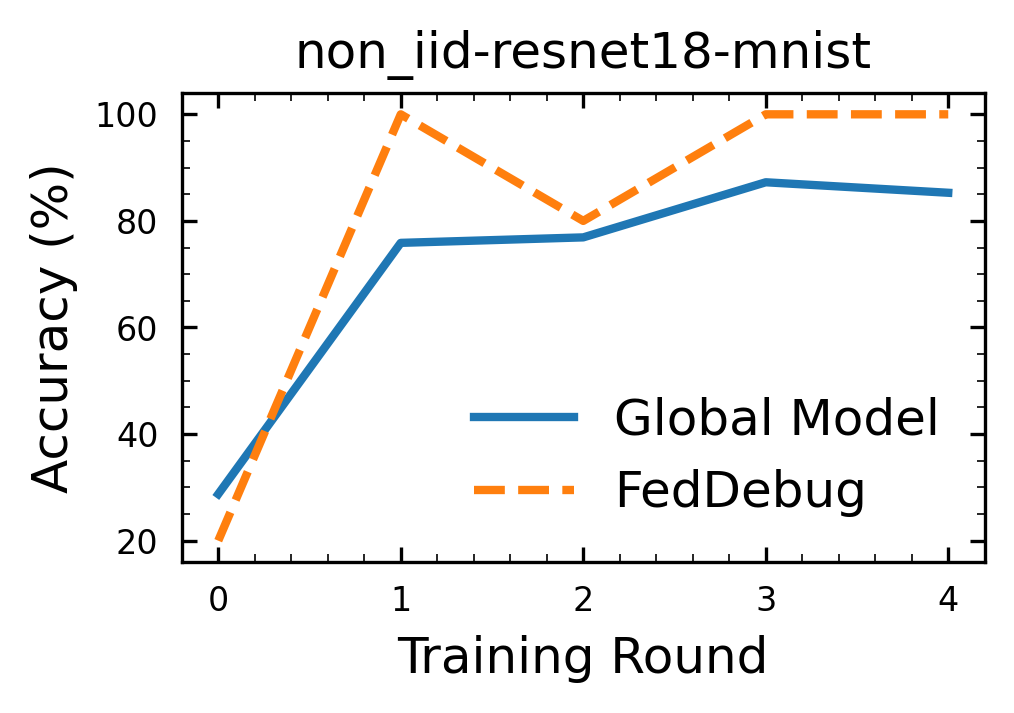
To run the experiments with ResNet and Cuda with Non-IID distribution you can run the following command. Total Time Taken: 84 seconds.
[!NOTE] You can run FedDebug with any model list in the
conf/base.yamlfile at line 24. Furthermore, you can quickly add additional models infeddebug/models.pyat line 47.
python -m feddebug.main device=cuda model=resnet18 distribution=non_iid
Output
...
[2024-10-24 12:13:40,679][flwr][INFO] - ***FedDebug Output Round 5 ***
[2024-10-24 12:13:40,679][flwr][INFO] - True Malicious Clients (Ground Truth) = ['0']
[2024-10-24 12:13:40,679][flwr][INFO] - Total Random Inputs = 10
[2024-10-24 12:13:40,679][flwr][INFO] - Predicted Malicious Clients = {'0': 1.0}
[2024-10-24 12:13:40,679][flwr][INFO] - FedDebug Localization Accuracy = 100.0
[2024-10-24 12:13:41,595][flwr][INFO] - fit progress: (5, 0.000987090128660202, {'accuracy': 0.8528, 'loss': 0.000987090128660202, 'round': 5}, 75.3773579710105)
[2024-10-24 12:13:41,595][flwr][INFO] - configure_evaluate: no clients selected, skipping evaluation
[2024-10-24 12:13:41,602][flwr][INFO] -
[2024-10-24 12:13:41,602][flwr][INFO] - [SUMMARY]
Following is the graph non_iid-resnet18-mnist.png generated by the code:
3. Threshold Impact on Localization¶
You can also test the impact of the neuron activation threshold on localization accuracy. A higher threshold decreases the localization accuracy. Total Time Taken: 84 seconds.
python -m feddebug.main device=cuda model=resnet18 feddebug.na_t=0.7
...
[2024-10-24 12:21:26,923][flwr][INFO] - ***FedDebug Output Round 2 ***
[2024-10-24 12:21:26,923][flwr][INFO] - True Malicious Clients (Ground Truth) = ['0']
[2024-10-24 12:21:26,923][flwr][INFO] - Total Random Inputs = 10
[2024-10-24 12:21:26,923][flwr][INFO] - Predicted Malicious Clients = {'5': 0.7, '0': 0.3}
[2024-10-24 12:21:26,923][flwr][INFO] - FedDebug Localization Accuracy = 30.0
[2024-10-24 12:21:27,773][flwr][INFO] - fit progress: (2, 0.001345307207107544, {'accuracy': 0.9497, 'loss': 0.001345307207107544, 'round': 2}, 31.669926984992344)
[2024-10-24 12:21:27,773][flwr][INFO] - configure_evaluate: no clients selected, skipping evaluation
[2024-10-24 12:21:27,773][flwr][INFO] -
Following is the graph iid-resnet18-mnist.png generated by the code:
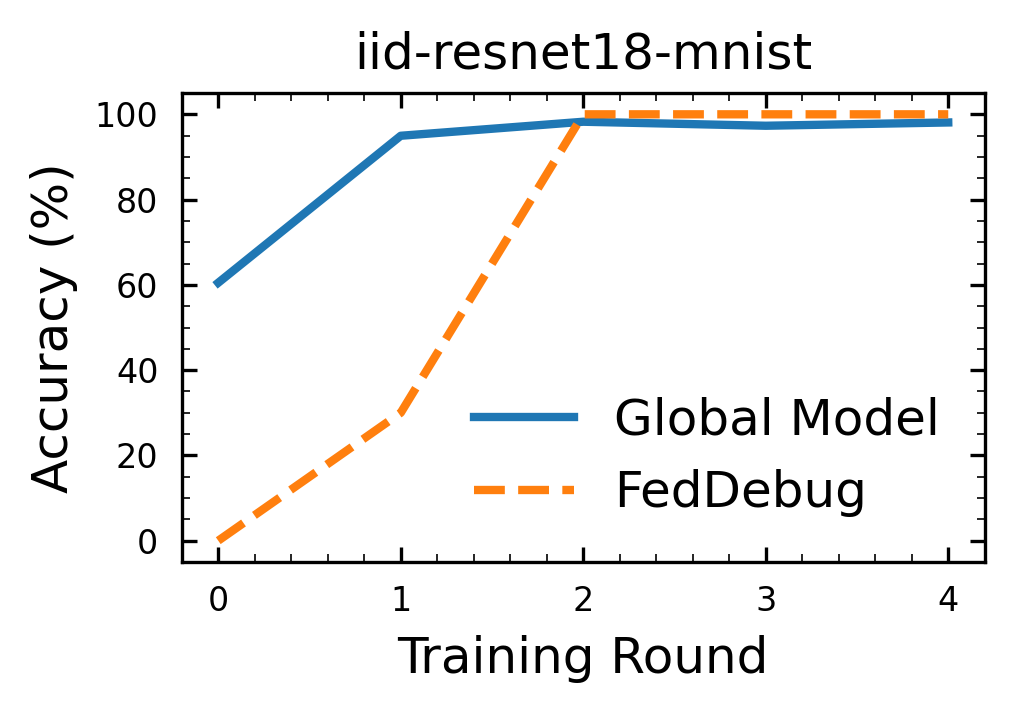
[!WARNING] FedDebug generates random inputs to localize malicious client(s). Thus, results might vary slightly on each run due to randomness.
Limitations and Discussion¶
Compared to the current baseline, FedDebug was originally evaluated using only a single round of training. It was not initially tested with Dirichlet partitioning for data distribution, which means it may deliver suboptimal performance under different data distribution settings. Enhancing FedDebug’s performance could be achieved by generating more effective random inputs, for example, through the use of Generative Adversarial Networks (GANs).
Application of FedDebug¶
We used FedDebug to detect backdoor attacks in Federated Learning, resulting in FedDefender. The code is implemented using the Flower Framework in this repository. We plan to adapt FedDefender to Flower baseline guidelines soon.
Citation¶
If you have any questions or feedback, feel free to contact me at waris@vt.edu. Please cite FedDebug as follows:
@inproceedings{gill2023feddebug,
title={{Feddebug: Systematic Debugging for Federated Learning Applications}},
author={Gill, Waris and Anwar, Ali and Gulzar, Muhammad Ali},
booktitle={2023 IEEE/ACM 45th International Conference on Software Engineering (ICSE)},
pages={512--523},
year={2023},
organization={IEEE}
}