Using Vana and Flower Together


Using Vana and Flower Together
Flower and Vana are working together to unlock a new powerful source of data for training AI models. The Vana network hosts some of the most unique personal data in its DataDAOs (e.g., there are DataDAOs for storing Twitter Data, Browser Data, Synthetic Data, etc). This data is willfully shared by the owners to agreed purposes in the expectation that they are compensated and shall receive part-ownership in assets such as AI models created using their data. Together with Flower, the leading open-source framework for Federated AI, this network is now able to be used to build next-gen foundation models and for finetuning LLMs on private data, just to name a few of the many exciting possibilities.
This blog post provides a primer to people wanting to use Vana and Flower together, offering high-level overviews of the Flower architecture and how it integrates with Vana. It will be updated regularly as the documentation and the code examples evolve.
Building foundational models with data on the Vana network
DataDAOs on the Vana network, with their unprecedented scope and scale of data, could unravel the next generation of foundational models. Leveraging the flower framework, the data collected at different DAOs can be used to train machine learning models in a distributed fashion. Below is an outline of the process to run an FL workload with the Flower framework on the Vana network of DataDAOs.
1. Setup DataDAO nodes as clients in federated learning
A typical federated learning setup involves clients that hold the data and perform local model training, along with a server that coordinates the training process as well as aggregating the updates it receives from the clients in each round. The first step in this process pipeline is to ensure that the DAOs are ready to function as clients in FL. This means ensuring that they have access to the appropriate data, compute resources, and software package requirements ready to train the model locally. Depending on the trust level, these compute nodes could be simple CPUs/GPUs or Trusted Execution Environments (TEEs).
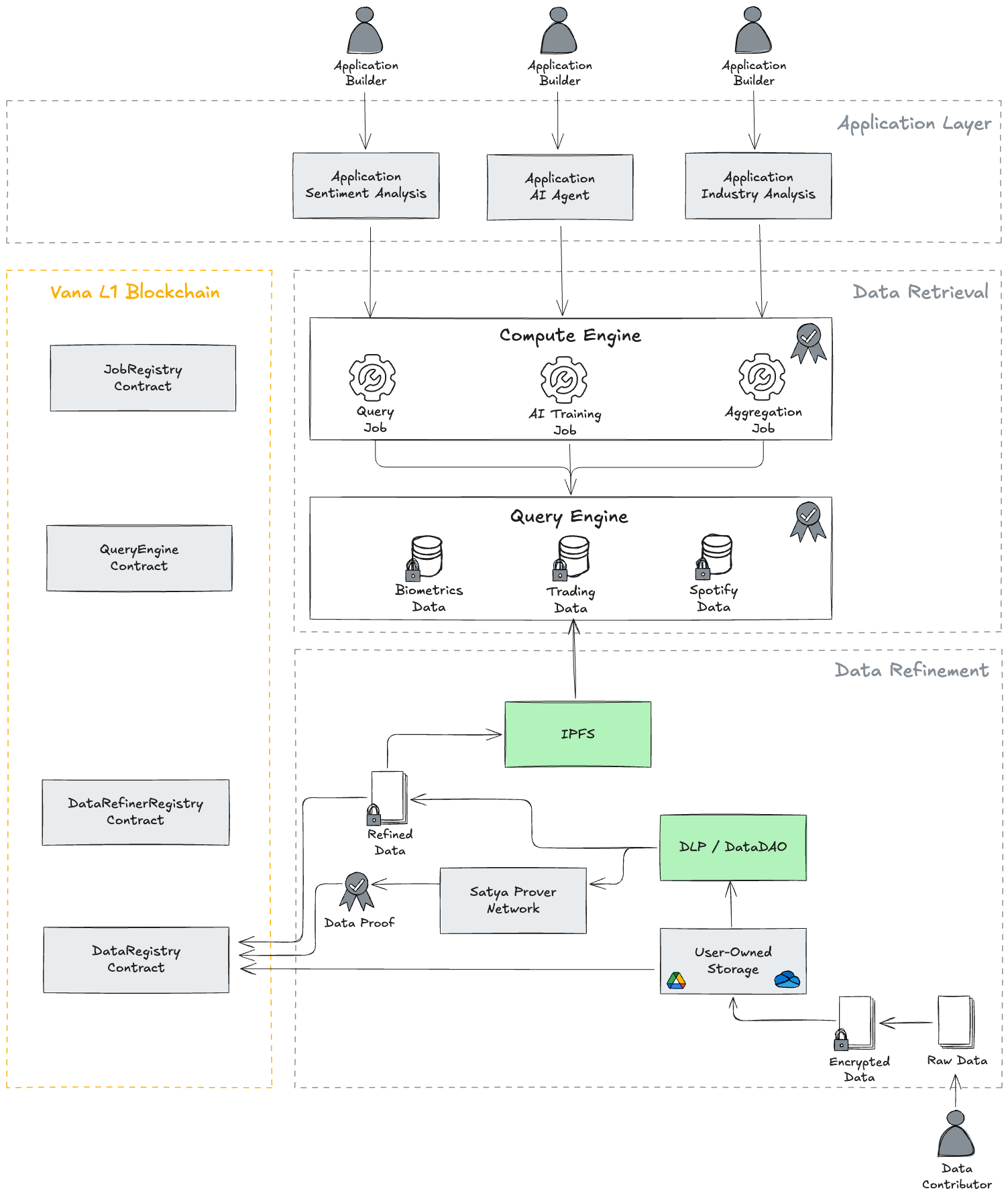
2. Setup the aggregation server
The next step is to set up the aggregation server that acts as a coordinator for the entire training process. This node (or set of nodes) could be part of the compute engine in the Vana data access layer. An overview of the Vana Data Access Layer is shown above (source). Given the training of machine learning models is an iterative process where the server receives model updates from clients over different rounds, it is recommended that the access to this aggregation server is well-guarded and ideally, the aggregations happen only in trusted execution environments.
3. Use Flower CLI to run training jobs
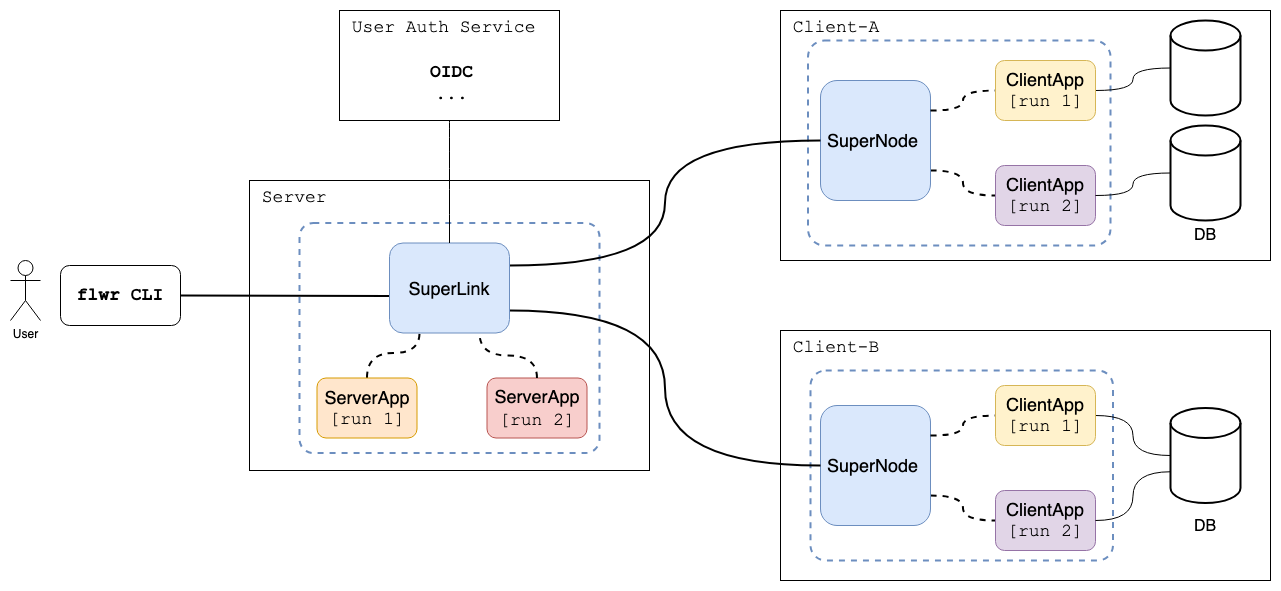
As described in the Vana data access layer, the federated learning workload can be triggered from the Flower CLI acting as the “Application Builder”. The Data Retrieval component of the Vana network retrieves the appropriate aggregation server and the corresponding clients for the given application. The application builder never directly interacts with the clients in the Flower architecture (shown below), which aligns well with Vana’s data access principle. This setup could also be made manually, wherein the application builder requests the compute engine to set up an aggregation server with requests to the required DataDAOs. The DataDAOs could then join the federation network by accepting invitations from the aggregation server.
4. Monitor the training pipeline, save the final model, and send payments to the data contributors
Once the training starts, monitor metrics of choice at the aggregate server node and the DataDAO clients. The DataDAOs could choose to store intermediate checkpoint models locally. The final model along with requested metrics is communicated from the aggregation server to the application layer after training converges. The data contributors are rewarded with the appropriate and agreed amount (could be based on the contributions to the “data liquidity pool” or based on custom metrics that measure how much their data helped in improving the model).
Finetuning LLMs on private DataDAOs and more!
Finetuning large language models (LLMs) on private data allows building powerful AI models that have improved relevance and better performance for domain-specific tasks. Flower framework, with its innate capabilities for handling private data in a distributed setting, can be used to finetune LLMs on DataDAOs. The setup is very similar to what's described above and the FlowerTune library could be readily used out of the box for efficient parameter tuning.
The Flower framework can also be easily leveraged to learn other types of machine learning models beyond LLMs, such as XGBoost models. Of course, beyond model training there are other challenges with FL on DataDAOs - e.g., defining the appropriate model architectures, selecting hyperparameters, and being robust to data discrepancies as all data is user-uploaded. Irrespective of the challenges, we see interesting opportunities ahead in working together with Vana. We’ll be sharing more updates here as the partnership evolves—stay tuned!