Federated Learning with XGBoost and Flower (Comprehensive Example)¶

This example demonstrates a comprehensive federated learning setup using Flower with XGBoost. We use HIGGS dataset to perform a binary classification task. This examples uses Flower Datasets to retrieve, partition and preprocess the data for each Flower client. It differs from the xgboost-quickstart example in the following ways:
Customised FL settings.
Customised partitioner type (uniform, linear, square, exponential).
Centralised/distributed evaluation.
Bagging/cyclic training methods.
Support of scaled learning rate.
Training Strategies¶
This example provides two training strategies, bagging aggregation and cyclic training.
Bagging Aggregation¶
Bagging (bootstrap) aggregation is an ensemble meta-algorithm in machine learning, used for enhancing the stability and accuracy of machine learning algorithms. Here, we leverage this algorithm for XGBoost trees.
Specifically, each client is treated as a bootstrap by random subsampling (data partitioning in FL). At each FL round, all clients boost a number of trees (in this example, 1 tree) based on the local bootstrap samples. Then, the clients’ trees are aggregated on the server, and concatenates them to the global model from previous round. The aggregated tree ensemble is regarded as a new global model.
This way, let’s consider a scenario with M clients. Given FL round R, the bagging models consist of (M * R) trees.
Cyclic Training¶
Cyclic XGBoost training performs FL in a client-by-client fashion. Instead of aggregating multiple clients, there is only one single client participating in the training per round in the cyclic training scenario. The trained local XGBoost trees will be passed to the next client as an initialised model for next round’s boosting.
Set up the project¶
Clone the project¶
Start by cloning the example project:
git clone --depth=1 https://github.com/flwrlabs/flower.git _tmp \
&& mv _tmp/examples/xgboost-comprehensive . \
&& rm -rf _tmp \
&& cd xgboost-comprehensive
This will create a new directory called xgboost-comprehensive with the following structure:
xgboost-comprehensive
├── xgboost_comprehensive
│ ├── __init__.py
│ ├── client_app.py # Defines your ClientApp
│ ├── server_app.py # Defines your ServerApp
│ └── task.py # Defines your model, training and data loading
├── pyproject.toml # Project metadata like dependencies and configs
└── README.md
Install dependencies and project¶
Install the dependencies defined in pyproject.toml as well as the xgboost_comprehensive package.
pip install -e .
Run the project¶
You can run your Flower project in both simulation and deployment mode without making changes to the code. If you are starting with Flower, we recommend you using the simulation mode as it requires fewer components to be launched manually. By default, flwr run will make use of the Simulation Engine.
Run with the Simulation Engine¶
[!NOTE] Check the Simulation Engine documentation to learn more about Flower simulations and how to optimize them.
flwr run . --stream
You can also override some of the settings for your ClientApp and ServerApp defined in pyproject.toml. For example:
# To run bagging aggregation for 5 rounds evaluated on centralised test set
flwr run . --run-config "train-method='bagging' num-server-rounds=5 centralised-eval=true" --stream
# To run cyclic training with linear partitioner type evaluated on centralised test set:
flwr run . --run-config "train-method='cyclic' partitioner-type='linear' centralised-eval-client=true" --stream
Run with the Deployment Engine¶
Follow this how-to guide to run the same app in this example but with Flower’s Deployment Engine. After that, you might be intersted in setting up secure TLS-enabled communications and SuperNode authentication in your federation.
If you are already familiar with how the Deployment Engine works, you may want to learn how to run it using Docker. Check out the Flower with Docker documentation.
Expected Experimental Results¶
Bagging aggregation experiment¶
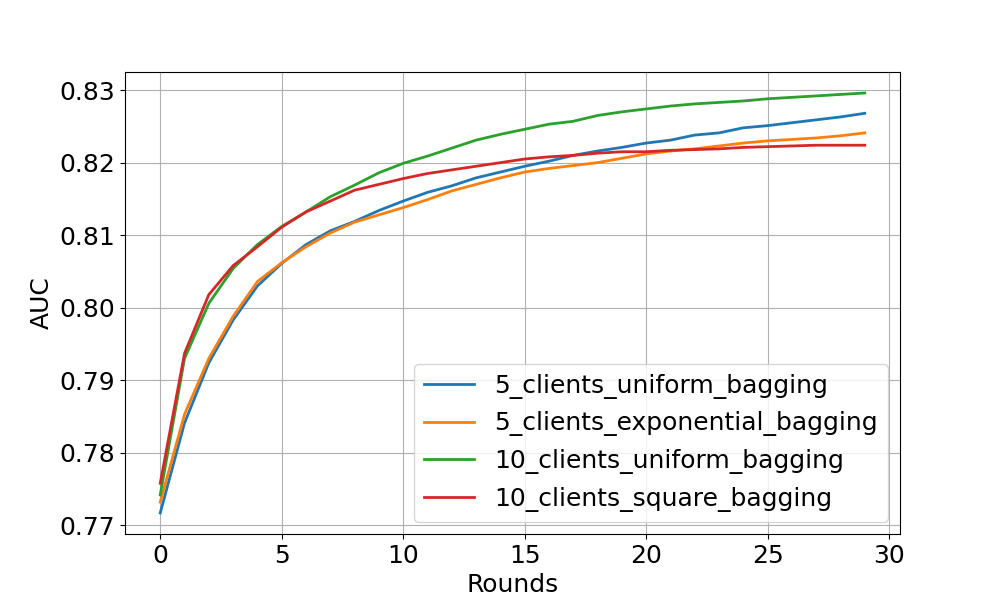
The figure above shows the centralised tested AUC performance over FL rounds with bagging aggregation strategy on 4 experimental settings. One can see that all settings obtain stable performance boost over FL rounds (especially noticeable at the start of training). As expected, uniform client distribution shows higher AUC values than square/exponential setup.
Cyclic training experiment¶
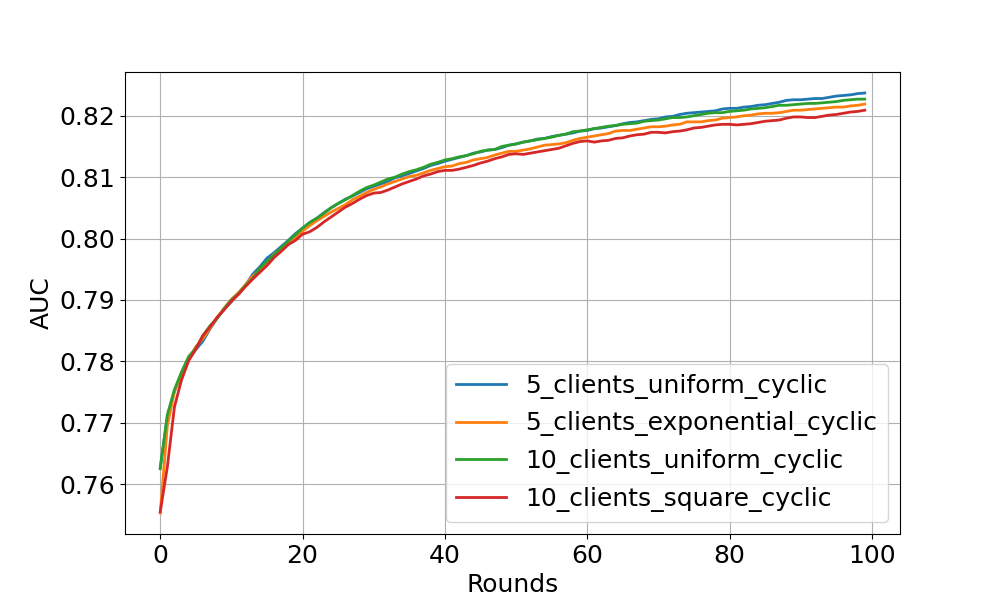
This figure shows the cyclic training results on centralised test set. The models with cyclic training requires more rounds to converge because only a single client participate in the training per round.
Feel free to explore more interesting experiments by yourself !