FlowerTune LLM: Federated LLM Fine-tuning with Flower¶

Large language models (LLMs), which have been trained on vast amounts of publicly accessible data, have shown remarkable effectiveness in a wide range of areas. However, despite the fact that more data typically leads to improved performance, there is a concerning prospect that the supply of high-quality public data will deplete within a few years. Federated LLM training could unlock access to an endless pool of distributed private data by allowing multiple data owners to collaboratively train a shared model without the need to exchange raw data.
This introductory example conducts federated instruction tuning with pretrained OpenLLaMA models on Alpaca-GPT4 dataset. We implement FlowerTune LLM by integrating a bundle of techniques: 1) We use Flower Datasets to download, partition and preprocess the dataset. 2) The fine-tuning is done using the 🤗PEFT library. 3) We use Flower’s Simulation Engine to simulate the LLM fine-tuning process in federated way, which allows users to perform the training on a single GPU.
Set up the project¶
Start by cloning the example project:
git clone --depth=1 https://github.com/flwrlabs/flower.git _tmp \
&& mv _tmp/examples/flowertune-llm . \
&& rm -rf _tmp \
&& cd flowertune-llm
This will create a new directory called flowertune-llm with the following structure:
flowertune-llm
├── flowertune_llm
│ ├── __init__.py
│ ├── client_app.py # Defines your ClientApp
│ ├── server_app.py # Defines your ServerApp
│ ├── dataset.py # Defines your dataset and tokenizer
│ └── models.py # Defines your models
│
├── pyproject.toml # Project metadata like dependencies and configs
├── test.py # Test pre-trained model
└── README.md
Install dependencies and project¶
Install the dependencies defined in pyproject.toml as well as the flowertune_llm package.
pip install -e .
Run the project¶
You can run your Flower project in both simulation and deployment mode without making changes to the code. If you are starting with Flower, we recommend you using the simulation mode as it requires fewer components to be launched manually. By default, flwr run will make use of the Simulation Engine.
This example is designed to run with 20 virtual SuperNodes which have GPU-enabled ClientApp execution. First we need to change the configuration of the Simulation Runtime (which by default uses 10 nodes and only CPU). This guide assumes your default SuperLink connection points to one ready for simulations. If you aren’t sure, please refer to the How-to run Flower locally guide.
flwr federation simulation-config \
--num-supernodes=20 \
--client-resources-num-cpus=8 \
--client-resources-num-gpus=1.0
Run with the Simulation Engine¶
[!NOTE] Check the Simulation Engine documentation to learn more about Flower simulations and how to optimize them.
flwr run . --stream
This command will run FL simulations with a 4-bit OpenLLaMA 3Bv2 model involving 2 clients per rounds for 100 FL rounds. You can override configuration parameters directly from the command line. Below are a few settings you might want to test:
# Use OpenLLaMA-7B instead of 3B and 8-bits quantization
flwr run . --run-config "model.name='openlm-research/open_llama_7b_v2' model.quantization=8" --stream
# Run for 50 rounds but increasing the fraction of clients that participate per round to 25%
flwr run . --run-config "num-server-rounds=50 strategy.fraction-train=0.25" --stream
Run with the Deployment Engine¶
Follow this how-to guide to run the same app in this example but with Flower’s Deployment Engine. After that, you might be intersted in setting up secure TLS-enabled communications and SuperNode authentication in your federation.
If you are already familiar with how the Deployment Engine works, you may want to learn how to run it using Docker. Check out the Flower with Docker documentation.
Expected results¶
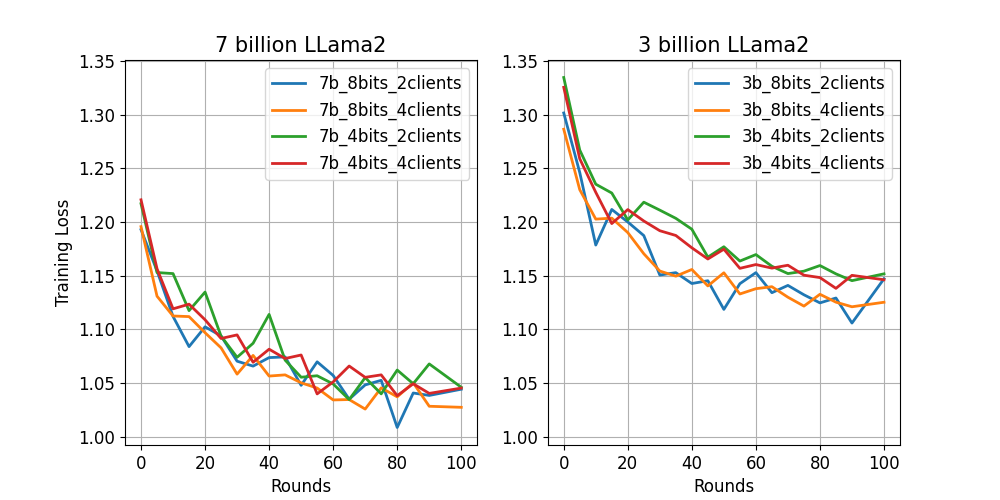
As expected, OpenLLaMA-7B model works better than its 3B version with lower training loss. With the hyperparameters tested, the 8-bit model seems to deliver lower training loss for the smaller 3B model compared to its 4-bit version.
VRAM consumption¶
Models |
7-billion (8-bit) |
7-billion (4-bit) |
3-billion (8-bit) |
3-billion (4-bit) |
|---|---|---|---|---|
VRAM |
~22.00 GB |
~16.50 GB |
~13.50 GB |
~10.60 GB |
We make use of the bitsandbytes library in conjunction with PEFT to derive LLMs that can be fine-tuned efficiently.
The above table shows the VRAM consumption per client for the different models considered in this example.
You can adjust the CPU/GPU resources you assign to each of the clients based on your device.
For example, it is easy to train 2 concurrent clients on each GPU (24 GB VRAM) if you choose 3-billion (4-bit) model.
Assigning 50% of the GPU’s VRAM to each client by setting options.backend.clientapp-gpus = 0.5 under [superlink.local] in your Flower Configuration file.
Test with your Questions¶
We provide a script to test your trained model by passing your specified questions. For example:
python test.py --peft-path=/path/to/trained-model-dir/ \
--question="What is the ideal 1-day plan in London?"
An answer generated from federated trained 7-billion (8-bit) OpenLLaMA model:
Great choice.
London has so much to offer, and you can really soak up all the sights and sounds in just a single day.
Here's a suggested itinerary for you.
Start your day off with a hearty breakfast at an authentic British diner.
Then head to the iconic Big Ben and the Houses of Parliament to learn about the history of the city.
Next, make your way to Westminster Abbey to see the many historical monuments and memorials.
From there, cross the river Thames to the Tower of London, which is home to the Crown Jewels of England and Scotland.
Finally, end your day with a relaxing visit to the London Eye, the tallest Ferris wheel in Europe, for a beautiful view of the city.
The Vicuna template we used in this example is for a chat assistant.
The generated answer is expected to be a multi-turn conversations. Feel free to try more interesting questions!