What is Federated Learning?¶
Welcome to the Flower federated learning tutorial!
In this tutorial, you will learn what federated learning is, build your first system in Flower, and gradually extend it. If you work through all parts of the tutorial, you will be able to build advanced federated learning systems that approach the current state of the art in the field.
🧑🏫 This tutorial starts from zero and expects no familiarity with federated learning. Only a basic understanding of data science and Python programming is assumed.
Tip
Star Flower on GitHub ⭐️ and join the Flower community on Flower Discuss or Flower Slack to introduce yourself, ask questions, and get help.
Let’s get started!
Classical Machine Learning¶
Before we begin discussing federated learning, let us quickly recap how most machine learning works today.
In machine learning, we have a model, and we have data. The model could be a neural network (as depicted here), or something else, like classical linear regression.

We train the model using the data to perform a useful task. A task could be to detect objects in images, transcribe an audio recording, or play a game like Go.

In practice, the training data we work with doesn’t originate on the machine we train the model on.
This data gets created “somewhere else”. For instance, the data can originate on a smartphone by the user interacting with an app, a car collecting sensor data, a laptop receiving input via the keyboard, or a smart speaker listening to someone trying to sing a song.

What’s also important to mention, this “somewhere else” is usually not just one place, it’s many places. It could be several devices all running the same app. But it could also be several organizations, all generating data for the same task.
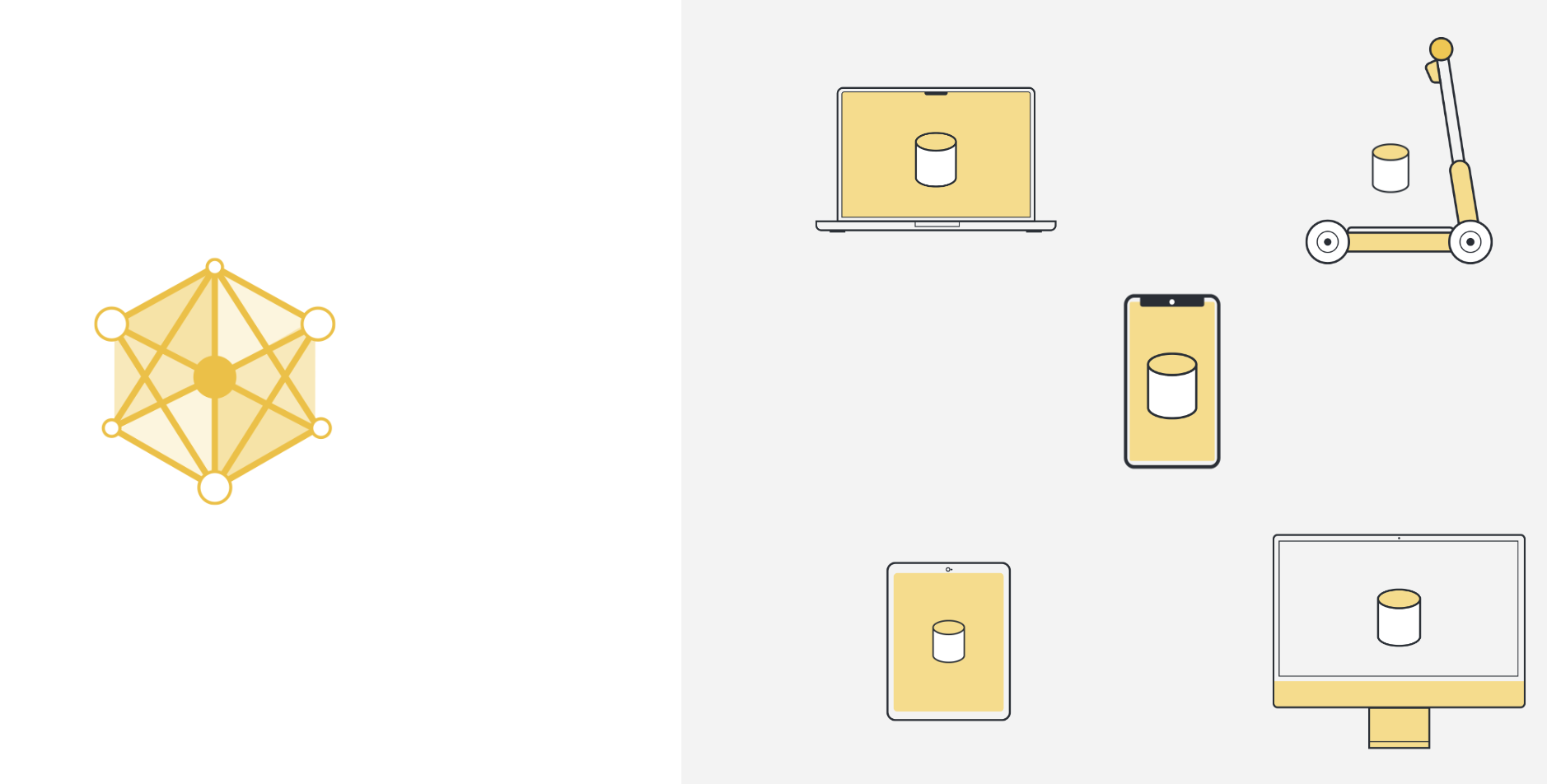
So to use machine learning, or any kind of data analysis, the approach that has been used in the past was to collect all this data on a central server. This server can be located somewhere in a data center, or somewhere in the cloud.
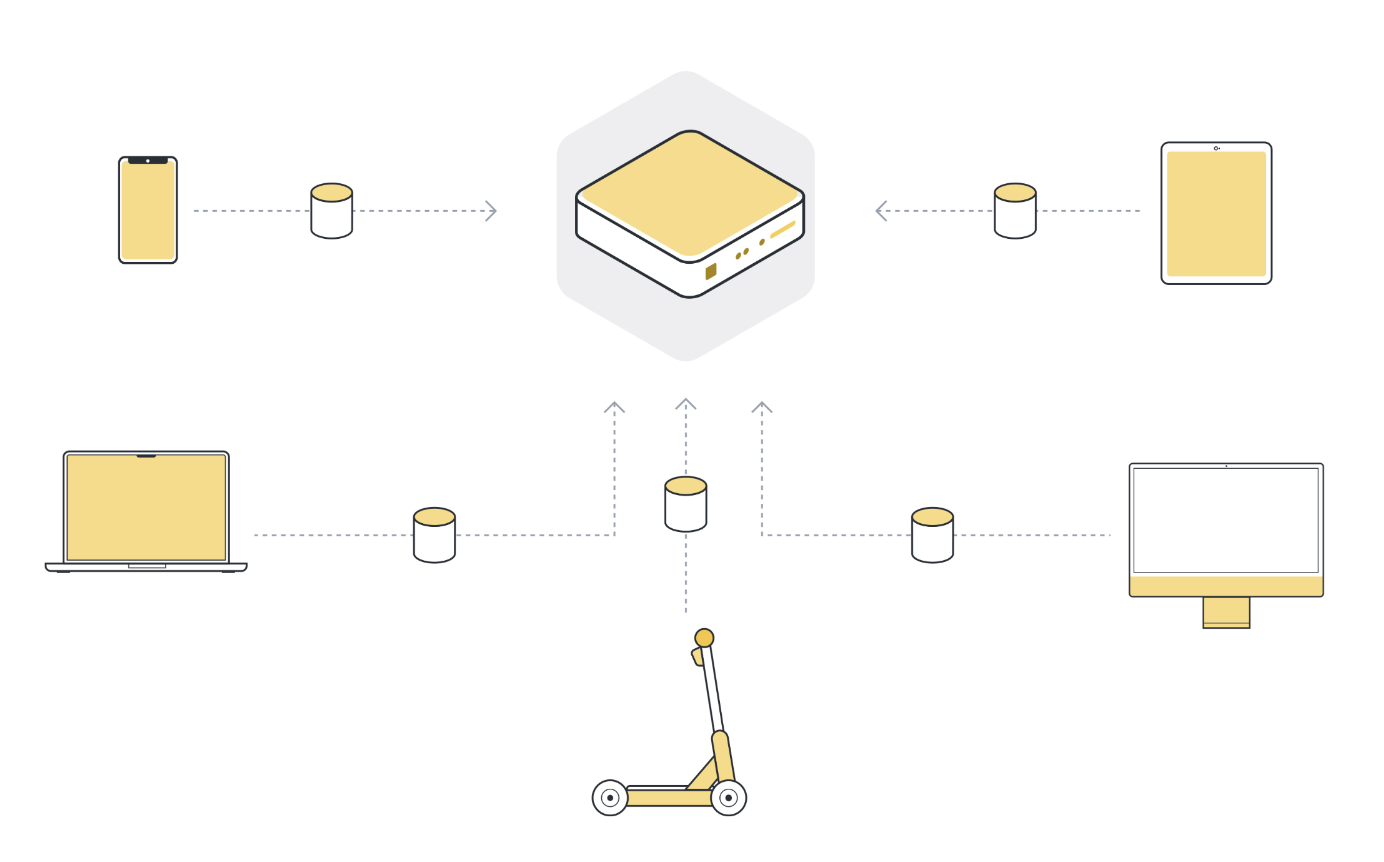
Once all the data is collected in one place, we can finally use machine learning algorithms to train our model on the data. This is the machine learning approach that we’ve basically always relied on.
Challenges of classical machine learning¶
This classical machine learning approach we’ve just seen can be used in some cases. Great examples include categorizing holiday photos, or analyzing web traffic. Cases, where all the data is naturally available on a centralized server.

But the approach can not be used in many other cases. Cases, where the data is not available on a centralized server, or cases where the data available on one server is not enough to train a good model.
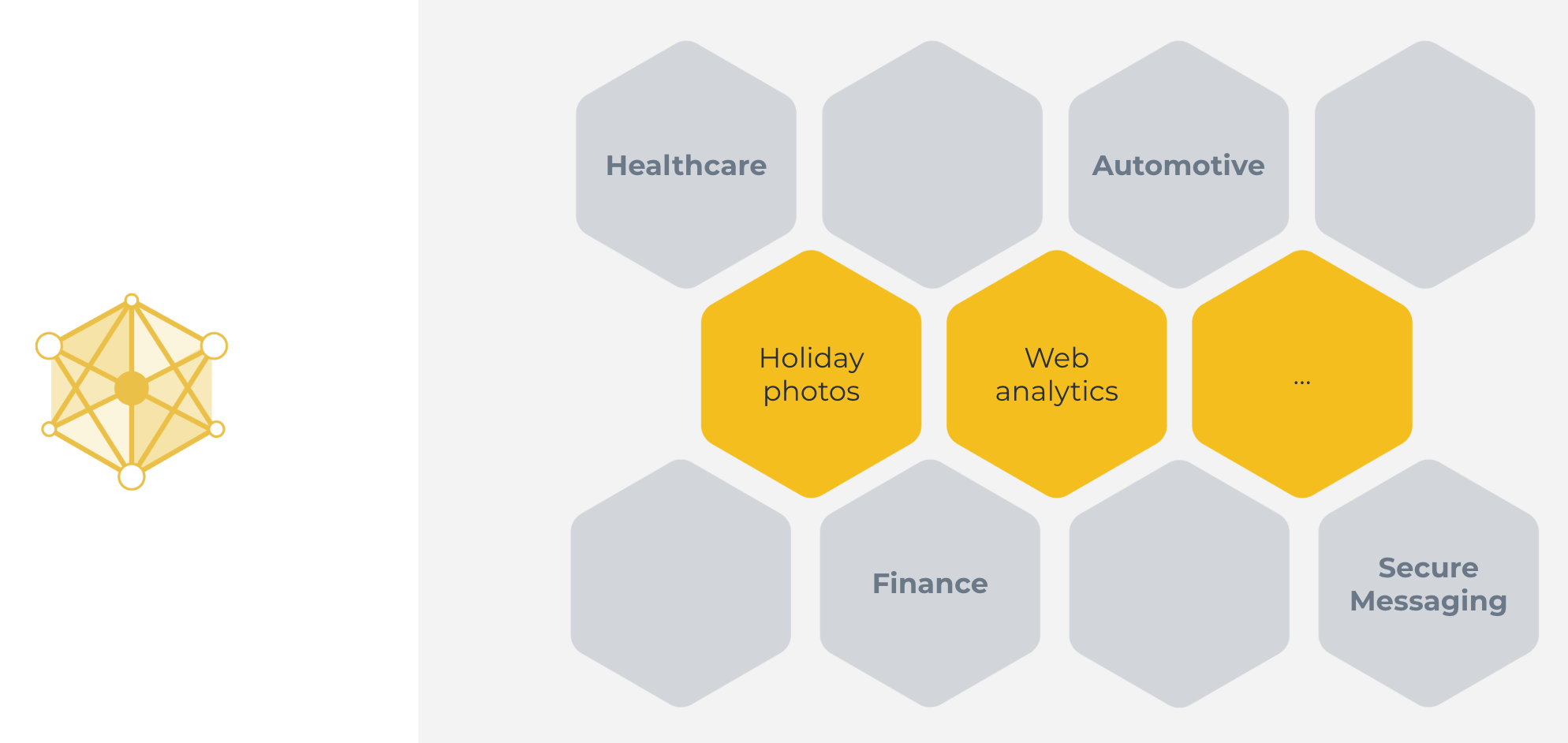
There are many reasons why the classical centralized machine learning approach does not work for a large number of highly important real-world use cases. Those reasons include:
Regulations: GDPR (Europe), CCPA (California), PIPEDA (Canada), LGPD (Brazil), PDPL (Argentina), KVKK (Turkey), POPI (South Africa), FSS (Russia), CDPR (China), PDPB (India), PIPA (Korea), APPI (Japan), PDP (Indonesia), PDPA (Singapore), APP (Australia), and other regulations protect sensitive data from being moved. In fact, those regulations sometimes even prevent single organizations from combining their own users’ data for machine learning training because those users live in different parts of the world, and their data is governed by different data protection regulations.
User preference: In addition to regulation, there are use cases where users just expect that no data leaves their device, ever. If you type your passwords and credit card info into the digital keyboard of your phone, you don’t expect those passwords to end up on the server of the company that developed that keyboard, do you? In fact, that use case was the reason federated learning was invented in the first place.
Data volume: Some sensors, like cameras, produce such a high data volume that it is neither feasible nor economic to collect all the data (due to, for example, bandwidth or communication efficiency). Think about a national rail service with hundreds of train stations across the country. If each of these train stations is outfitted with a number of security cameras, the volume of raw on-device data they produce requires incredibly powerful and exceedingly expensive infrastructure to process and store. And most of the data isn’t even useful.
Examples where centralized machine learning does not work include:
Sensitive healthcare records from multiple hospitals to train cancer detection models.
Financial information from different organizations to detect financial fraud.
Location data from your electric car to make better range prediction.
End-to-end encrypted messages to train better auto-complete models.
The popularity of privacy-enhancing systems like the Brave browser or the Signal messenger shows that users care about privacy. In fact, they choose the privacy-enhancing version over other alternatives, if such an alternative exists. But what can we do to apply machine learning and data science to these cases to utilize private data? After all, these are all areas that would benefit significantly from recent advances in AI.
Federated Learning¶
Federated Learning simply reverses this approach. It enables machine learning on distributed data by moving the training to the data, instead of moving the data to the training. Here’s a one-liner explanation:
Centralized machine learning: move the data to the computation
Federated (machine) Learning: move the computation to the data
By doing so, Federated Learning enables us to use machine learning (and other data science approaches) in areas where it wasn’t possible before. We can now train excellent medical AI models by enabling different hospitals to work together. We can solve financial fraud by training AI models on the data of different financial institutions. We can build novel privacy-enhancing applications (such as secure messaging) that have better built-in AI than their non-privacy-enhancing alternatives. And those are just a few of the examples that come to mind. As we deploy Federated Learning, we discover more and more areas that can suddenly be reinvented because they now have access to vast amounts of previously inaccessible data.
So how does Federated Learning work, exactly? Let’s start with an intuitive explanation.
Federated learning in five steps¶
Step 0: Initialize global model¶
We start by initializing the model on the server. This is exactly the same in classic centralized learning: we initialize the model parameters, either randomly or from a previously saved checkpoint.
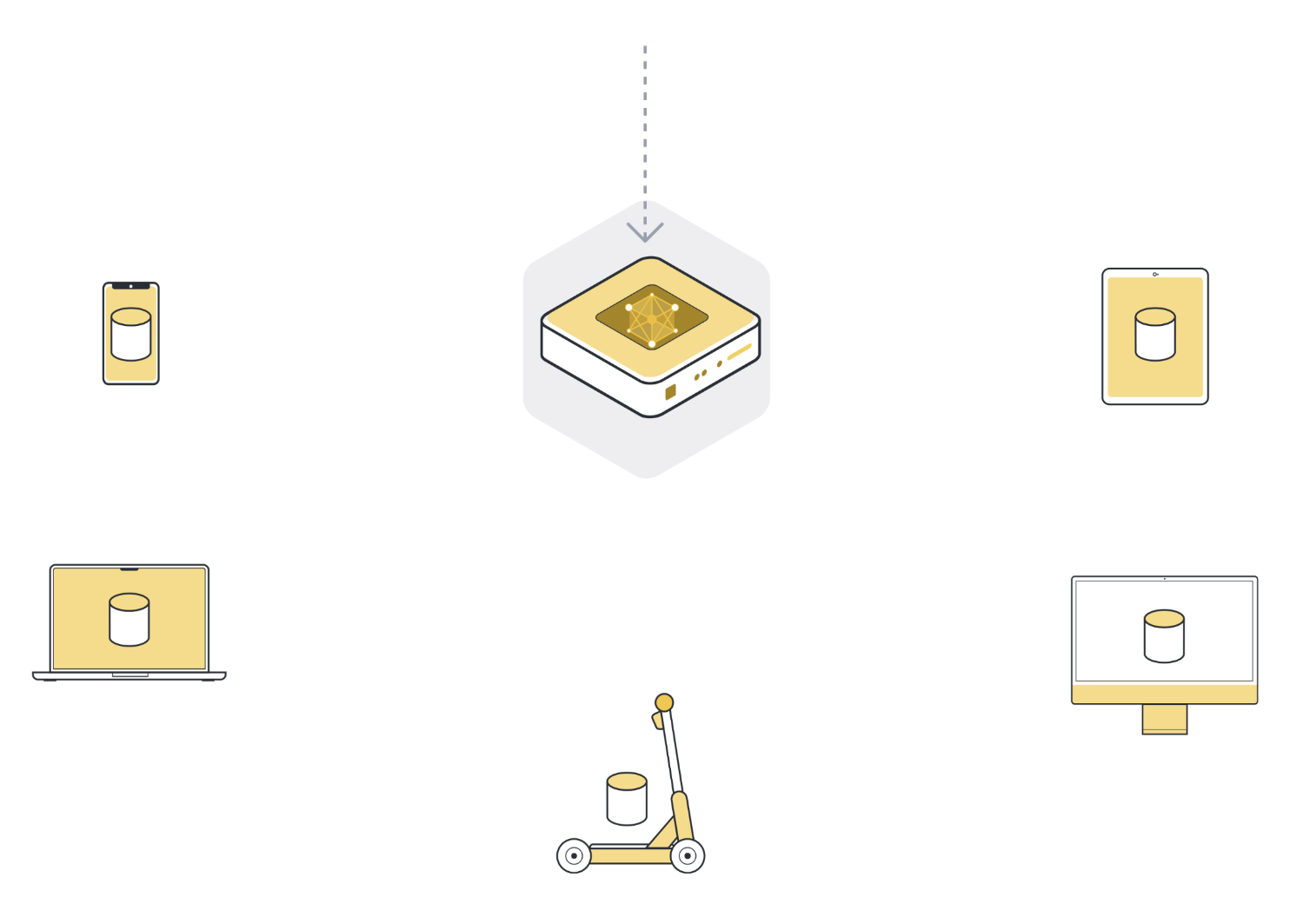
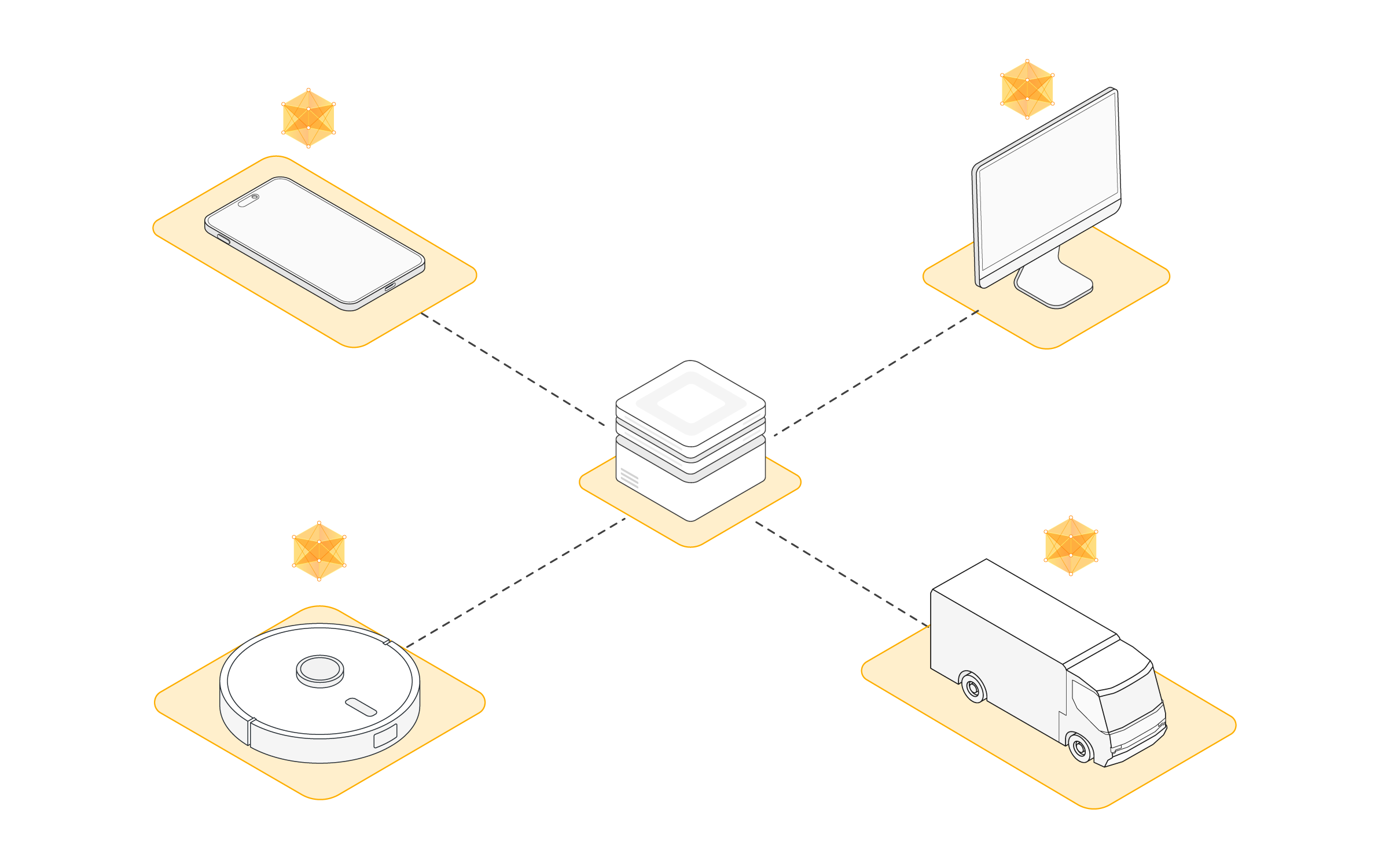
Step 1: Send model to a number of connected organizations/devices (client nodes)¶
Next, we send the parameters of the global model to the connected client nodes (think: edge devices like smartphones or servers belonging to organizations). This is to ensure that each participating node starts its local training using the same model parameters. We often use only a few of the connected nodes instead of all nodes. The reason for this is that selecting more and more client nodes has diminishing returns.
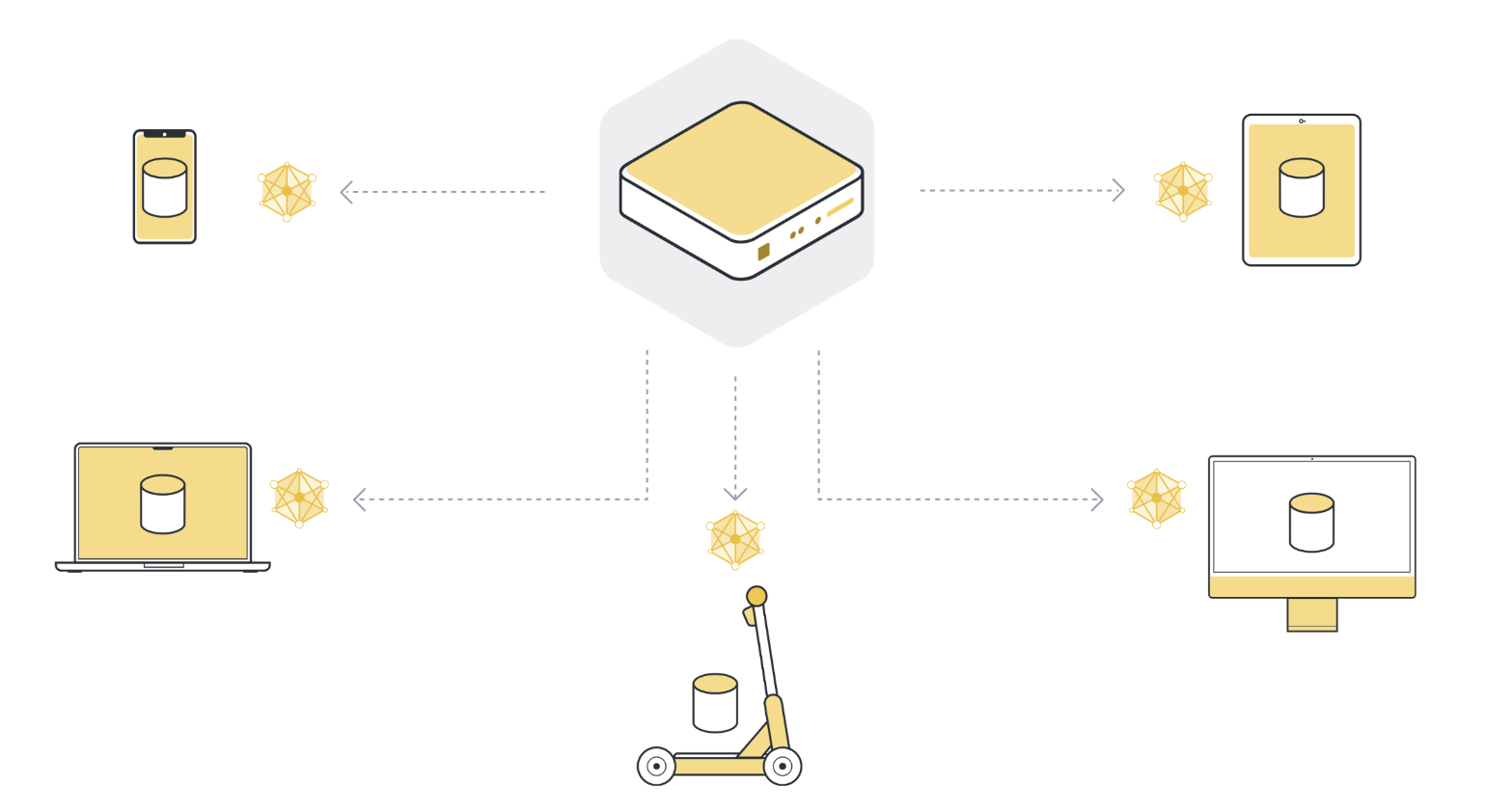
Step 2: Train model locally on the data of each organization/device (client node)¶
Now that all (selected) client nodes have the latest version of the global model parameters, they start the local training. They use their own local dataset to train their own local model. They don’t train the model until full convergence, but they only train for a little while. This could be as little as one epoch on the local data, or even just a few steps (mini-batches).
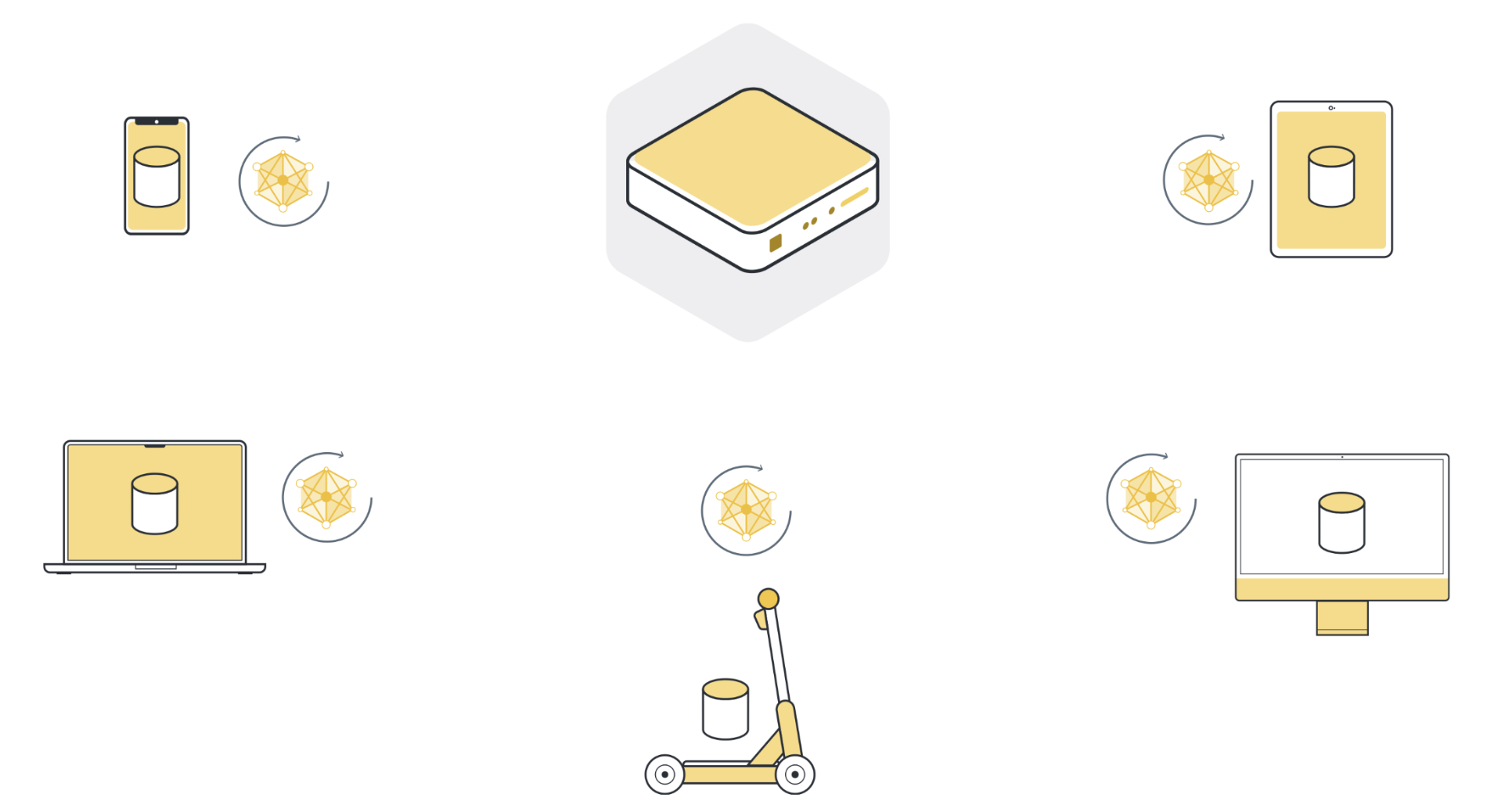
Step 3: Return model updates back to the server¶
After local training, each client node has a slightly different version of the model parameters they originally received. The parameters are all different because each client node has different examples in its local dataset. The client nodes then send those model updates back to the server. The model updates they send can either be the full model parameters or just the gradients that were accumulated during local training.
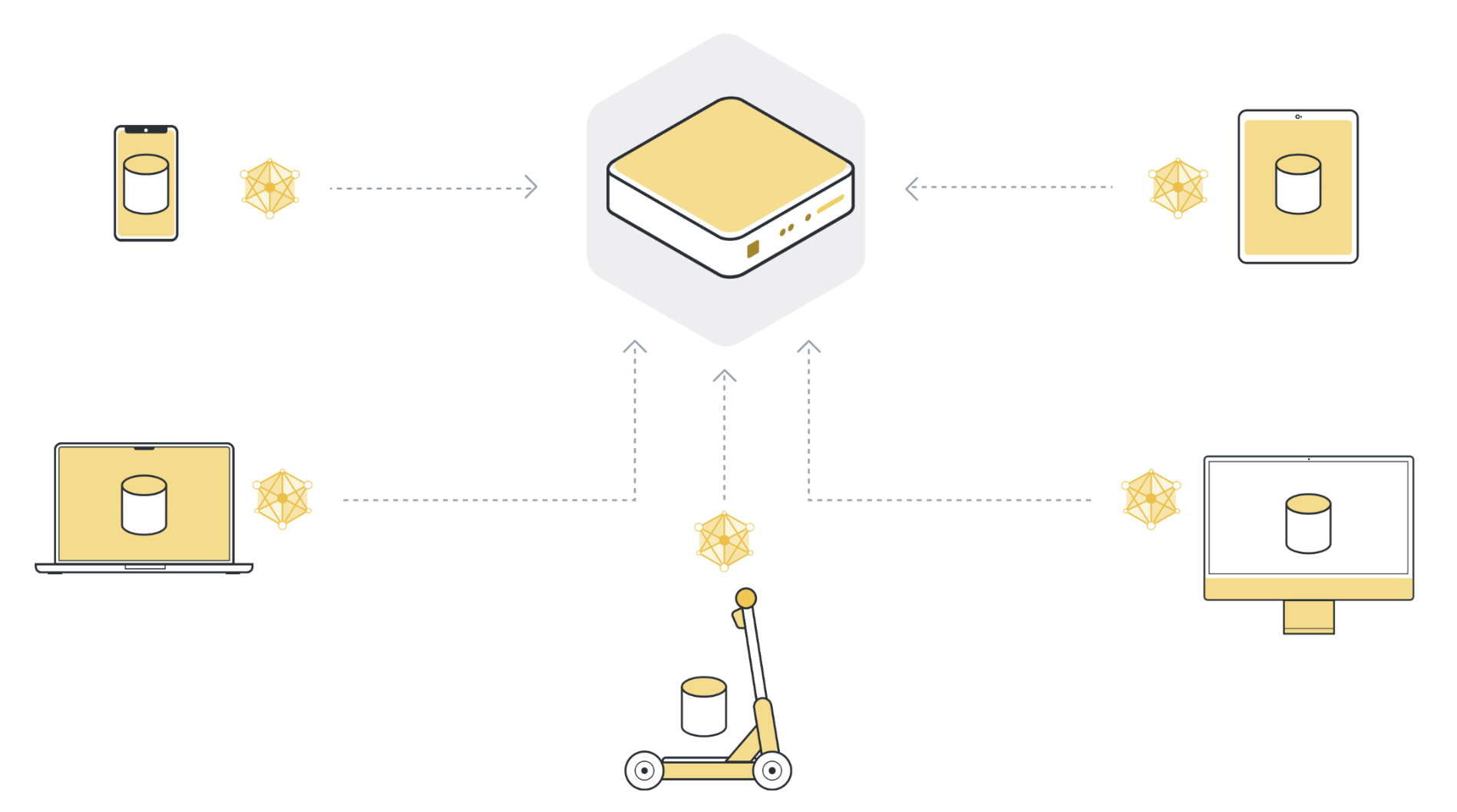
Step 4: Aggregate model updates into a new global model¶
The server receives model updates from the selected client nodes. If it selected 100 client nodes, it now has 100 slightly different versions of the original global model, each trained on the local data of one client. But didn’t we want to have one model that contains the learnings from the data of all 100 client nodes?
In order to get one single model, we have to combine all the model updates we received from the client nodes. This process is called aggregation, and there are many different ways to do it. The most basic way is called Federated Averaging (McMahan et al., 2016), often abbreviated as FedAvg. FedAvg takes the 100 model updates and, as the name suggests, averages them. To be more precise, it takes the weighted average of the model updates, weighted by the number of examples each client used for training. The weighting is important to make sure that each data example has the same “influence” on the resulting global model. If one client has 10 examples, and another client has 100 examples, then - without weighting - each of the 10 examples would influence the global model ten times as much as each of the 100 examples.
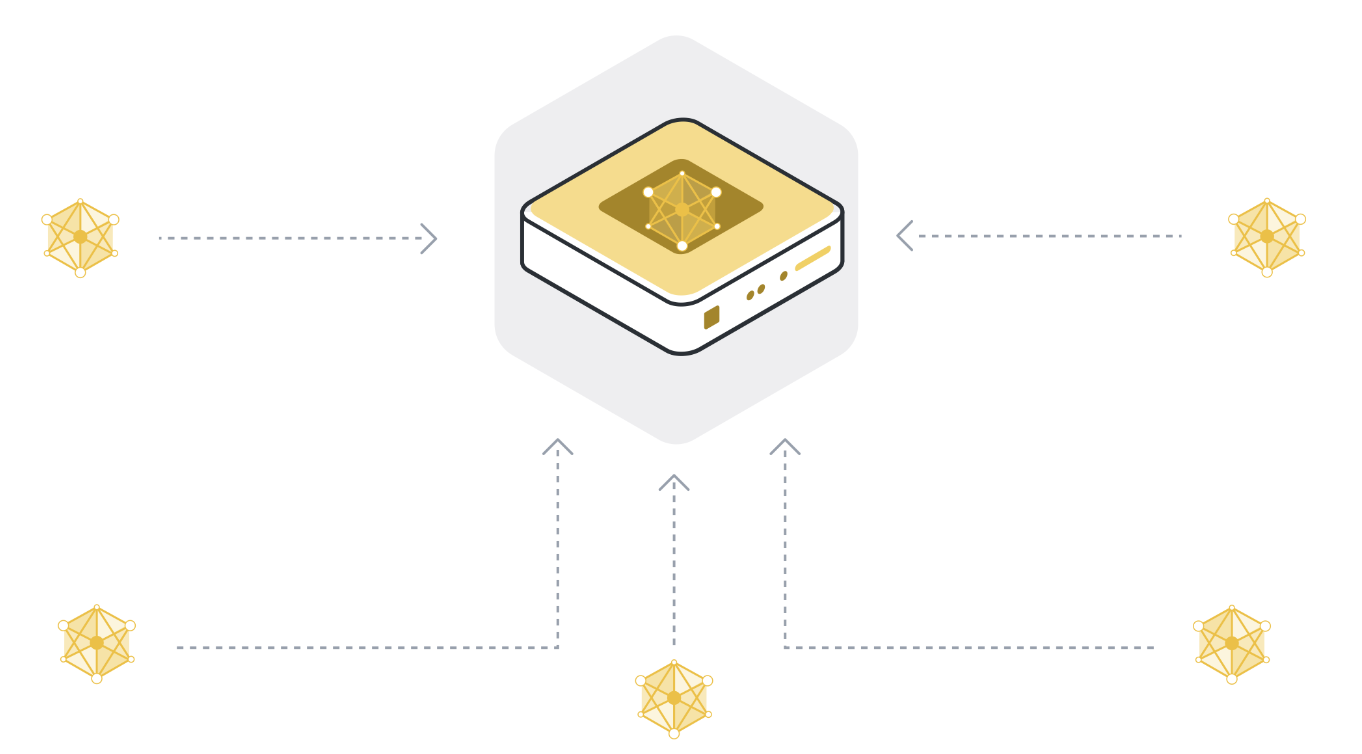
Step 5: Repeat steps 1 to 4 until the model converges¶
Steps 1 to 4 are what we call a single round of federated learning. The global model parameters get sent to the participating client nodes (step 1), the client nodes train on their local data (step 2), they send their updated models to the server (step 3), and the server then aggregates the model updates to get a new version of the global model (step 4).
During a single round, each client node that participates in that iteration only trains for a little while. This means that after the aggregation step (step 4), we have a model that has been trained on all the data of all participating client nodes, but only for a little while. We then have to repeat this training process over and over again to eventually arrive at a fully trained model that performs well across the data of all client nodes.
Conclusion¶
Congratulations, you now understand the basics of federated learning. There’s a lot more to discuss, of course, but that was federated learning in a nutshell. In later parts of this tutorial, we will go into more detail. Interesting questions include: How can we select the best client nodes that should participate in the next round? What’s the best way to aggregate model updates? How can we handle failing client nodes (stragglers)?
Federated Evaluation¶
Just like we can train a model on the decentralized data of different client nodes, we can also evaluate the model on that data to receive valuable metrics. This is called federated evaluation, sometimes abbreviated as FE. In fact, federated evaluation is an integral part of most federated learning systems.
Federated Analytics¶
In many cases, machine learning isn’t necessary to derive value from data. Data analysis can yield valuable insights, but again, there’s often not enough data to get a clear answer. What’s the average age at which people develop a certain type of health condition? Federated analytics enables such queries over multiple client nodes. It is usually used in conjunction with other privacy-enhancing technologies like secure aggregation to prevent the server from seeing the results submitted by individual client nodes.
Differential Privacy¶
Differential privacy (DP) is often mentioned in the context of Federated Learning. It is a privacy-preserving method used when analyzing and sharing statistical data, ensuring the privacy of individual participants. DP achieves this by adding statistical noise to the model updates, ensuring any individual participants’ information cannot be distinguished or re-identified. This technique can be considered an optimization that provides a quantifiable privacy protection measure.
Flower¶
Federated learning, federated evaluation, and federated analytics require infrastructure to move machine learning models back and forth, train and evaluate them on local data, and then aggregate the updated models. Flower provides the infrastructure to do exactly that in an easy, scalable, and secure way. In short, Flower presents a unified approach to federated learning, analytics, and evaluation. It allows the user to federate any workload, any ML framework, and any programming language.
Final Remarks¶
Congratulations, you just learned the basics of federated learning and how it relates to classic centralized machine learning.
In the next tutorial, you will take the first practical step with Flower: create a simulated federation on SuperGrid, run an existing Flower App from Flower Hub, and use the SuperGrid dashboard to follow the run and inspect its logs.
Next steps¶
Before you continue, make sure to join the Flower community on Flower Discuss (Join Flower Discuss) and on Slack (Join Slack).
There’s a dedicated #questions Slack channel if you need help, but we’d also love to
hear who you are in #introductions!
The Flower Collaborative AI Tutorial - Part 1: Get started with Flower shows how to create your first federation on SuperGrid and run a Flower App without writing code.