연합 학습이란 무엇입니까?¶
Welcome to the Flower federated learning tutorial!
이 튜토리얼에서 연합 학습이 무엇인지 배우고 Flower로 첫 번째 시스템을 구축하고 점진적으로 확장해 나갈 것입니다. 본 튜토리얼의 모든 부분을 완성할 수 있다면, 당신은 고급 연합 학습 시스템을 구축하여 그 분야의 현재 최고 기술 수준에 접근할 수 있을 것입니다.
🧑🏫 This tutorial starts from zero and expects no familiarity with federated learning. Only a basic understanding of data science and Python programming is assumed.
팁
Star Flower on GitHub ⭐️ and join the Flower community on Flower Discuss or Flower Slack to introduce yourself, ask questions, and get help.
Let’s get started!
Classical Machine Learning¶
Before we begin discussing federated learning, let us quickly recap how most machine learning works today.
머신러닝에서 우리는 모델과 데이터를 가지고 있습니다. 모델은 신경망(그림과 같이)일 수도 있고 고전적인 선형 회귀와 같은 다른 것일 수도 있습니다.

우리는 유용한 작업을 수행하기 위해 데이터를 사용하여 모델을 훈련합니다. 작업은 이미지 속 물체를 감지하거나 음성 녹음을 기록하거나 바둑과 같은 게임을 하는 것일 수 있습니다.

In practice, the training data we work with doesn’t originate on the machine we train the model on.
This data gets created “somewhere else”. For instance, the data can originate on a smartphone by the user interacting with an app, a car collecting sensor data, a laptop receiving input via the keyboard, or a smart speaker listening to someone trying to sing a song.

What’s also important to mention, this “somewhere else” is usually not just one place, it’s many places. It could be several devices all running the same app. But it could also be several organizations, all generating data for the same task.
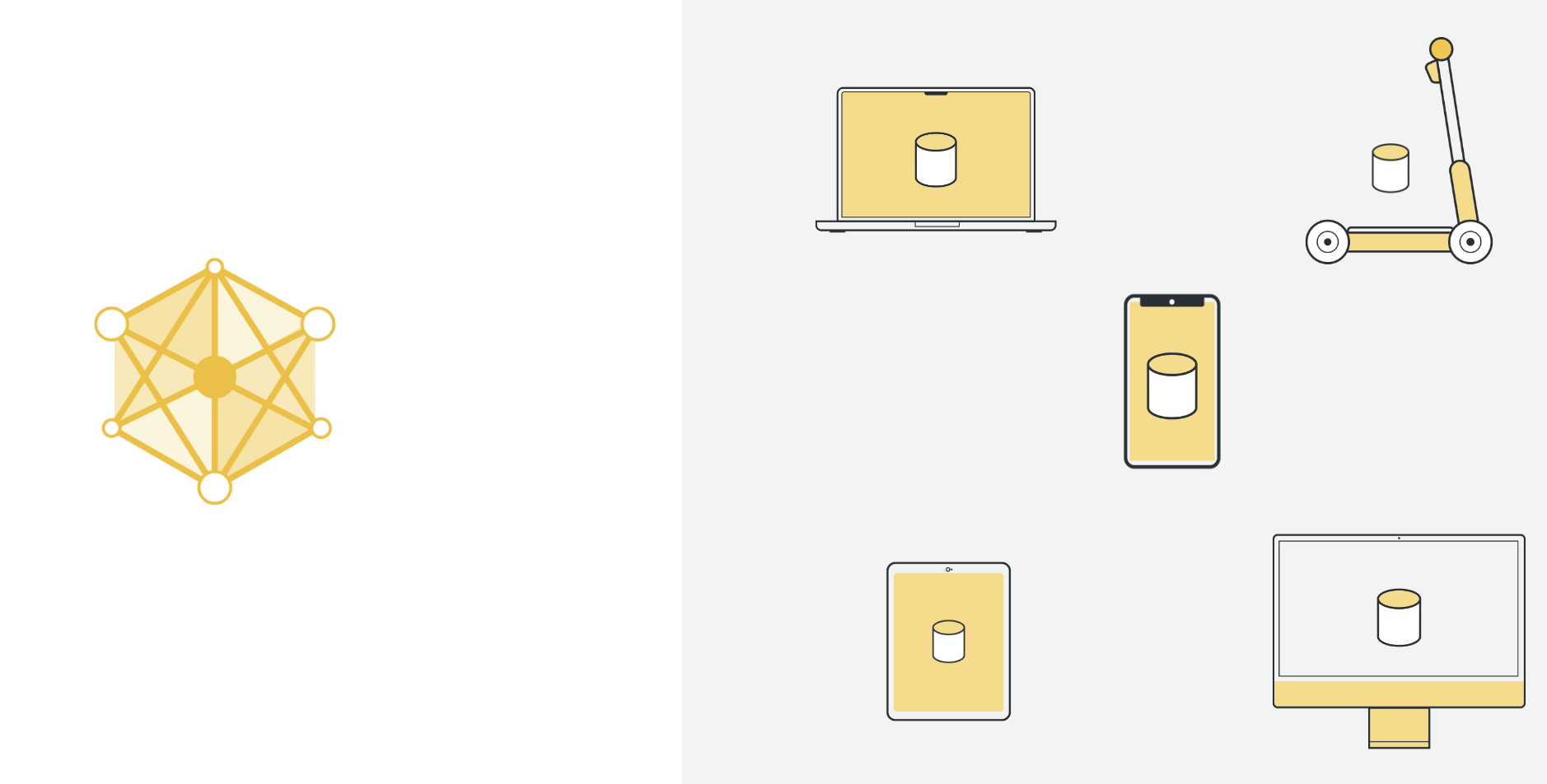
So to use machine learning, or any kind of data analysis, the approach that has been used in the past was to collect all this data on a central server. This server can be located somewhere in a data center, or somewhere in the cloud.
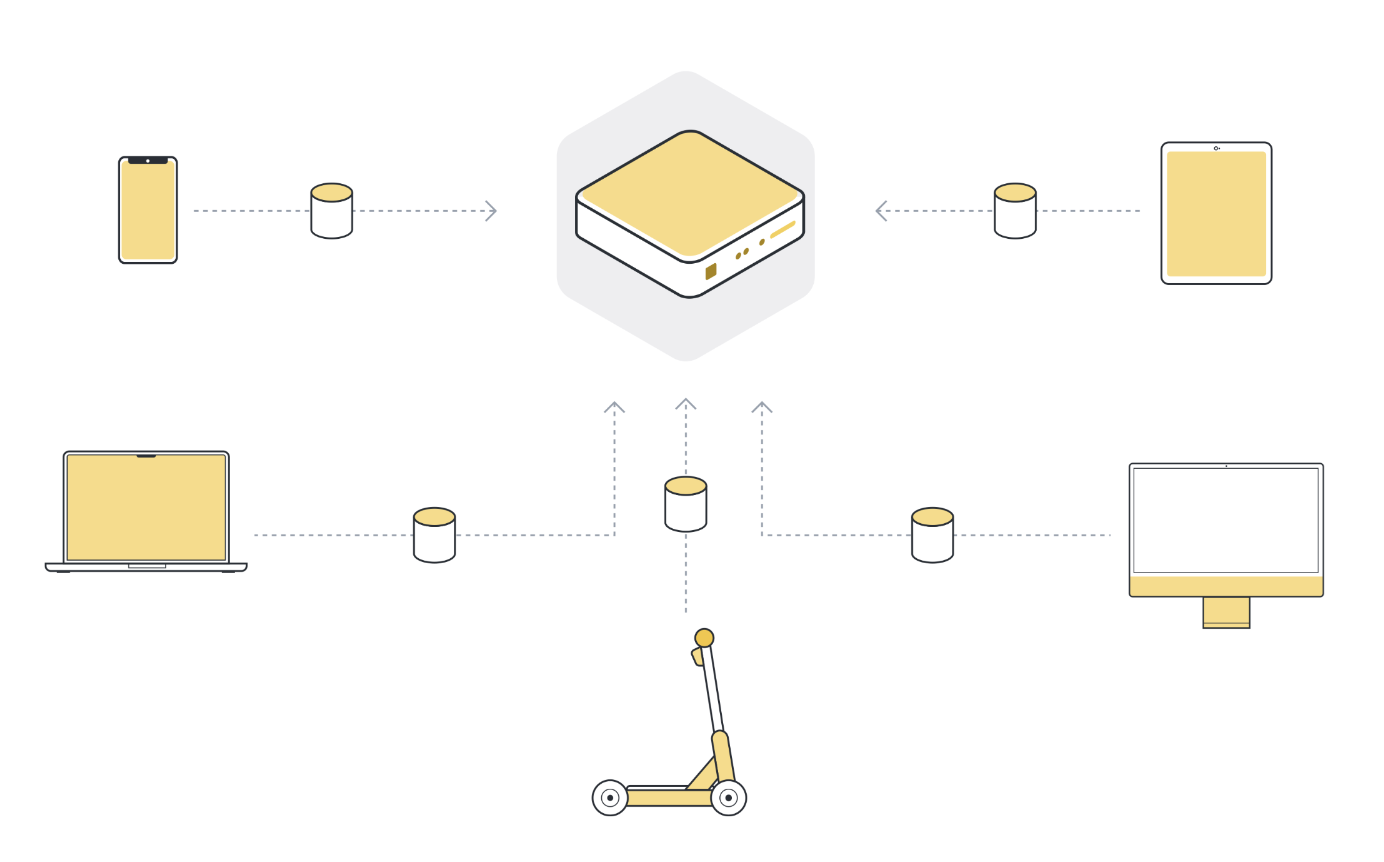
모든 데이터가 한 곳에 모이면, 우리는 궁극적으로 머신러닝 알고리즘을 사용하여 데이터에서 모델을 훈련시킬 수 있습니다. 이것이 바로 우리가 기본적으로 사용해 온 머신러닝 방법입니다.
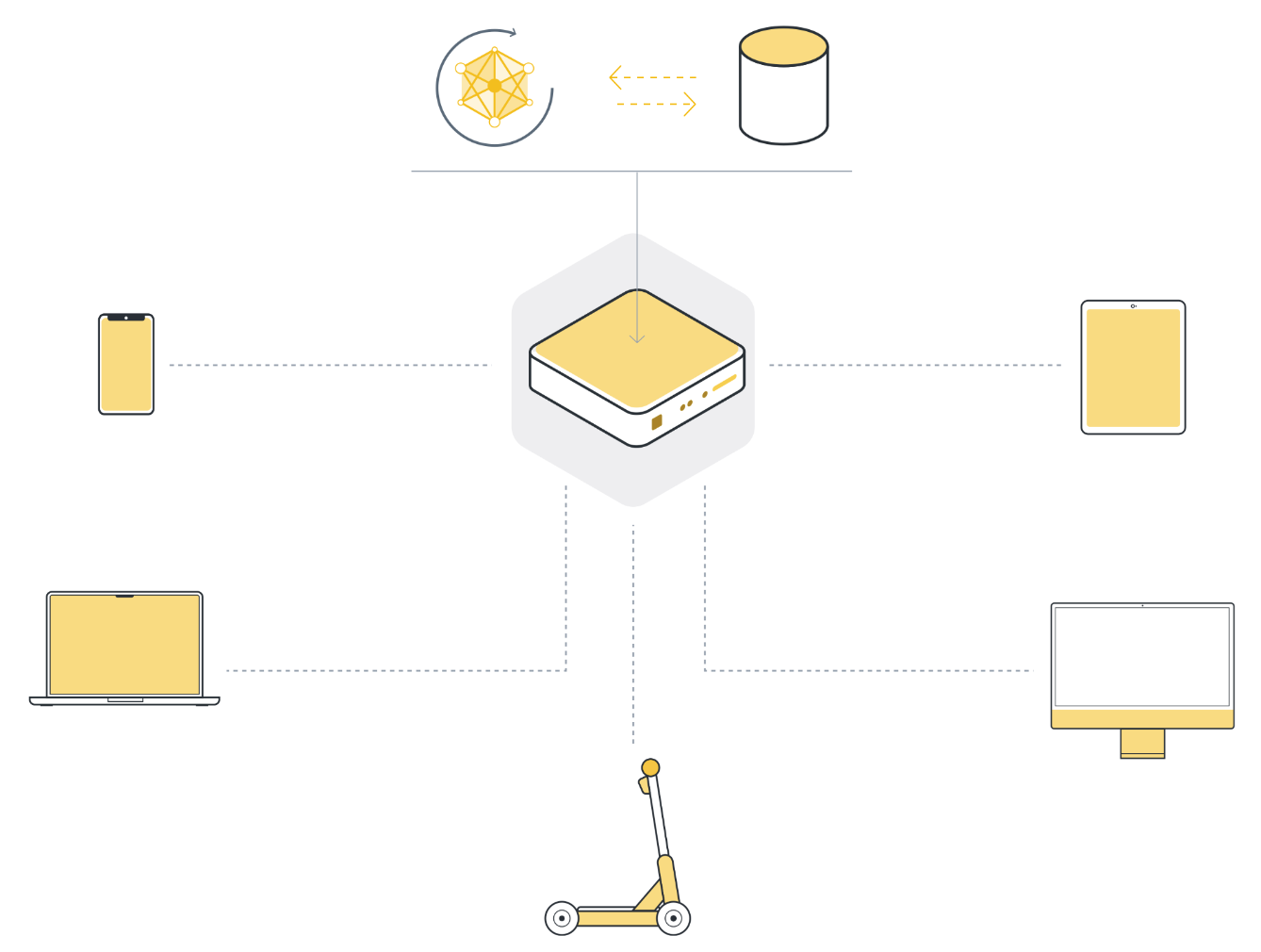
클래식 머신러닝의 어려움¶
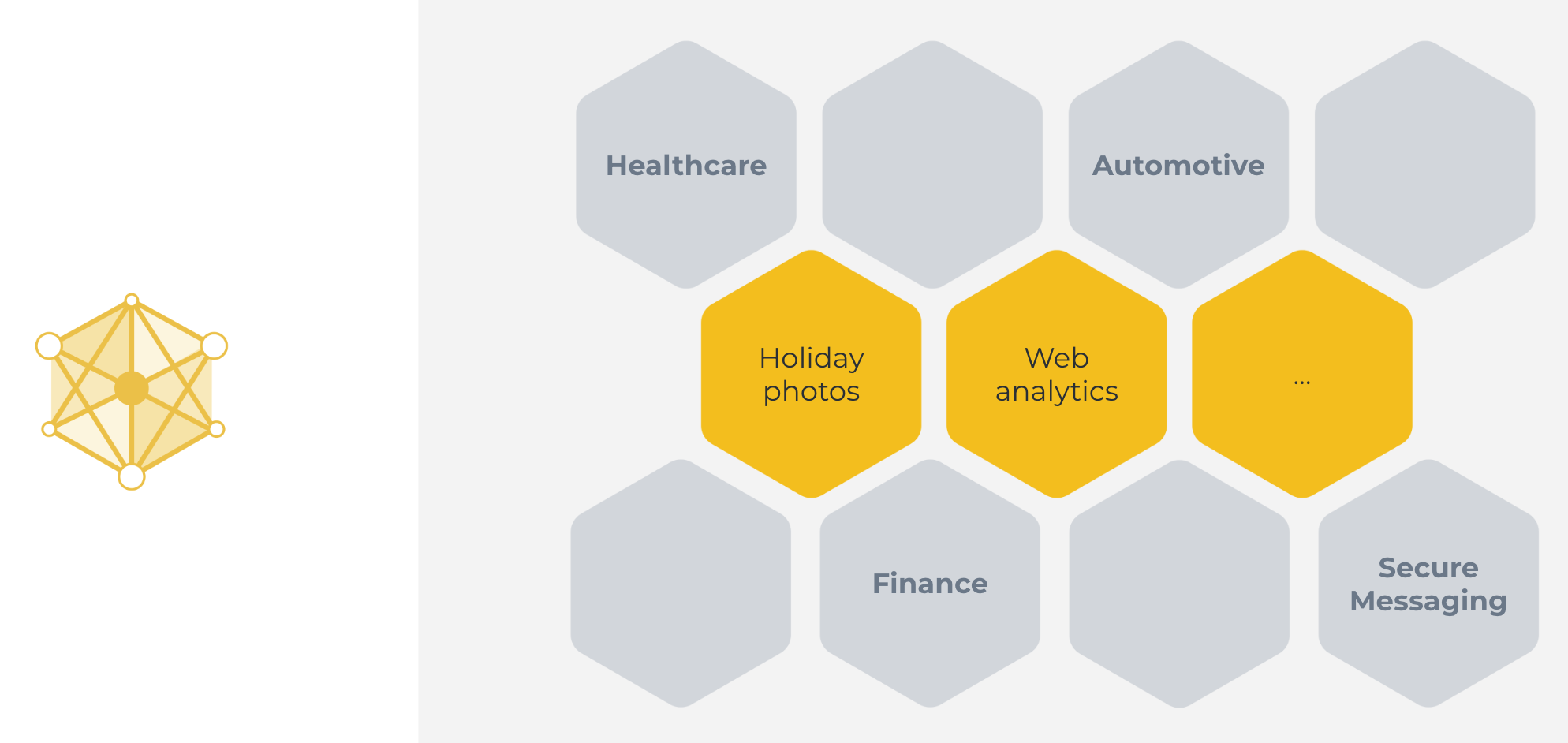
This classical machine learning approach we’ve just seen can be used in some cases. Great examples include categorizing holiday photos, or analyzing web traffic. Cases, where all the data is naturally available on a centralized server.

그러나 이 방법은 다른 많은 경우에 적용되지 않을 수 있습니다. 예를 들어, 중앙 집중식 서버에 데이터가 없거나 서버의 데이터가 좋은 모델을 훈련하기에 충분하지 않을 수 있습니다.
There are many reasons why the classical centralized machine learning approach does not work for a large number of highly important real-world use cases. Those reasons include:
Regulations: GDPR (Europe), CCPA (California), PIPEDA (Canada), LGPD (Brazil), PDPL (Argentina), KVKK (Turkey), POPI (South Africa), FSS (Russia), CDPR (China), PDPB (India), PIPA (Korea), APPI (Japan), PDP (Indonesia), PDPA (Singapore), APP (Australia), and other regulations protect sensitive data from being moved. In fact, those regulations sometimes even prevent single organizations from combining their own users’ data for machine learning training because those users live in different parts of the world, and their data is governed by different data protection regulations.
사용자 선호도: 규정 외에도 일부 사용 사례에서 사용자는 데이터가 자기 장치를 떠나지 않기를 예상합니다. 휴대폰의 디지털 키보드에 비밀번호와 신용카드 정보를 입력하면 비밀번호가 해당 키보드를 개발한 회사의 서버에 뜨길 원하지는 않겠죠? 사실, 이 사용 사례가 애당초 연합 학습이 발명된 이유였습니다.
데이터 볼륨: 일부 센서(예:카메라)는 너무 많은 데이터 볼륨을 생성하여 모든 데이터를 수집하는 것이 실현 가능하지도 않고 경제적이지도 않습니다(예: 대역폭 또는 통신 효율로 인해). 전국에 수백 개 기차역이 있는 국가 철도 서비스를 생각해 보세요. 각 기차역에 수 많은 보안 카메라가 설치되어 있다면, 그들이 생산하는 대량의 미가공 된 온디바이스 데이터는 처리 및 저장을 위해 엄청나게 강력하고 매우 비싼기반 구조를 필요로 합니다. 그런데 대부분의 데이터는 유용하지도 않습니다.
중앙 집중식 머신러닝이 작동하지 않는 예는 다음과 같습니다:
Sensitive healthcare records from multiple hospitals to train cancer detection models.
Financial information from different organizations to detect financial fraud.
Location data from your electric car to make better range prediction.
End-to-end encrypted messages to train better auto-complete models.
Brave 브라우저나 Signal 메신저와 같은 개인 정보 보호 시스템의 인기는 사용자들이 개인 정보 보호에 신경 쓴다는 것을 보여줍니다. 실제로 그러한 대안이 존재하는 경우 다른 대안보다 개인 정보 보호 강화 버전을 선택합니다. 그런데 이러한 사례에 머신러닝 및 데이터 과학을 적용하여 프라이버시 데이터를 활용하려면 어떻게 해야 합니까? 이 모든 분야는 최근 AI의 발전으로 상당한 이익을 얻을 수 있는 분야입니다.
Federated Learning¶
Federated Learning simply reverses this approach. It enables machine learning on distributed data by moving the training to the data, instead of moving the data to the training. Here’s a one-liner explanation:
Centralized machine learning: move the data to the computation
Federated (machine) Learning: move the computation to the data
By doing so, Federated Learning enables us to use machine learning (and other data science approaches) in areas where it wasn’t possible before. We can now train excellent medical AI models by enabling different hospitals to work together. We can solve financial fraud by training AI models on the data of different financial institutions. We can build novel privacy-enhancing applications (such as secure messaging) that have better built-in AI than their non-privacy-enhancing alternatives. And those are just a few of the examples that come to mind. As we deploy Federated Learning, we discover more and more areas that can suddenly be reinvented because they now have access to vast amounts of previously inaccessible data.
So how does Federated Learning work, exactly? Let’s start with an intuitive explanation.
연합 학습의 5단계¶
0단계: 글로벌 모델 초기화¶
서버에서 모델을 초기화하는 것으로 시작합니다. 이것은 전통적인 중앙 집중식 학습과도 동일합니다: 임의로 또는 이전에 저장된 체크포인트에서 모델 매개변수를 초기화합니다.
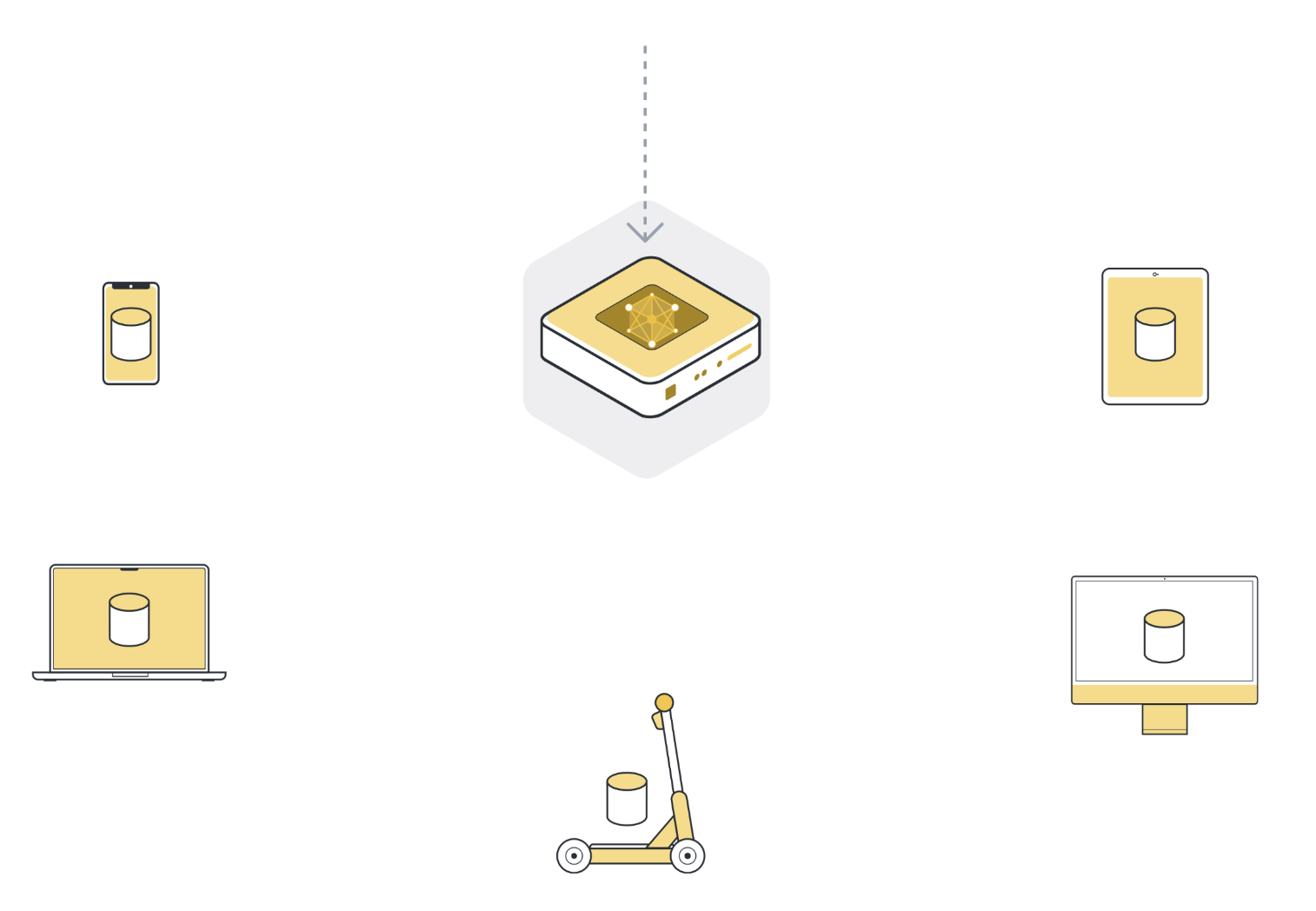
1단계: 연결된 여러 조직/장치(클라이언트 노드)에 모델 전송¶
Next, we send the parameters of the global model to the connected client nodes (think: edge devices like smartphones or servers belonging to organizations). This is to ensure that each participating node starts its local training using the same model parameters. We often use only a few of the connected nodes instead of all nodes. The reason for this is that selecting more and more client nodes has diminishing returns.
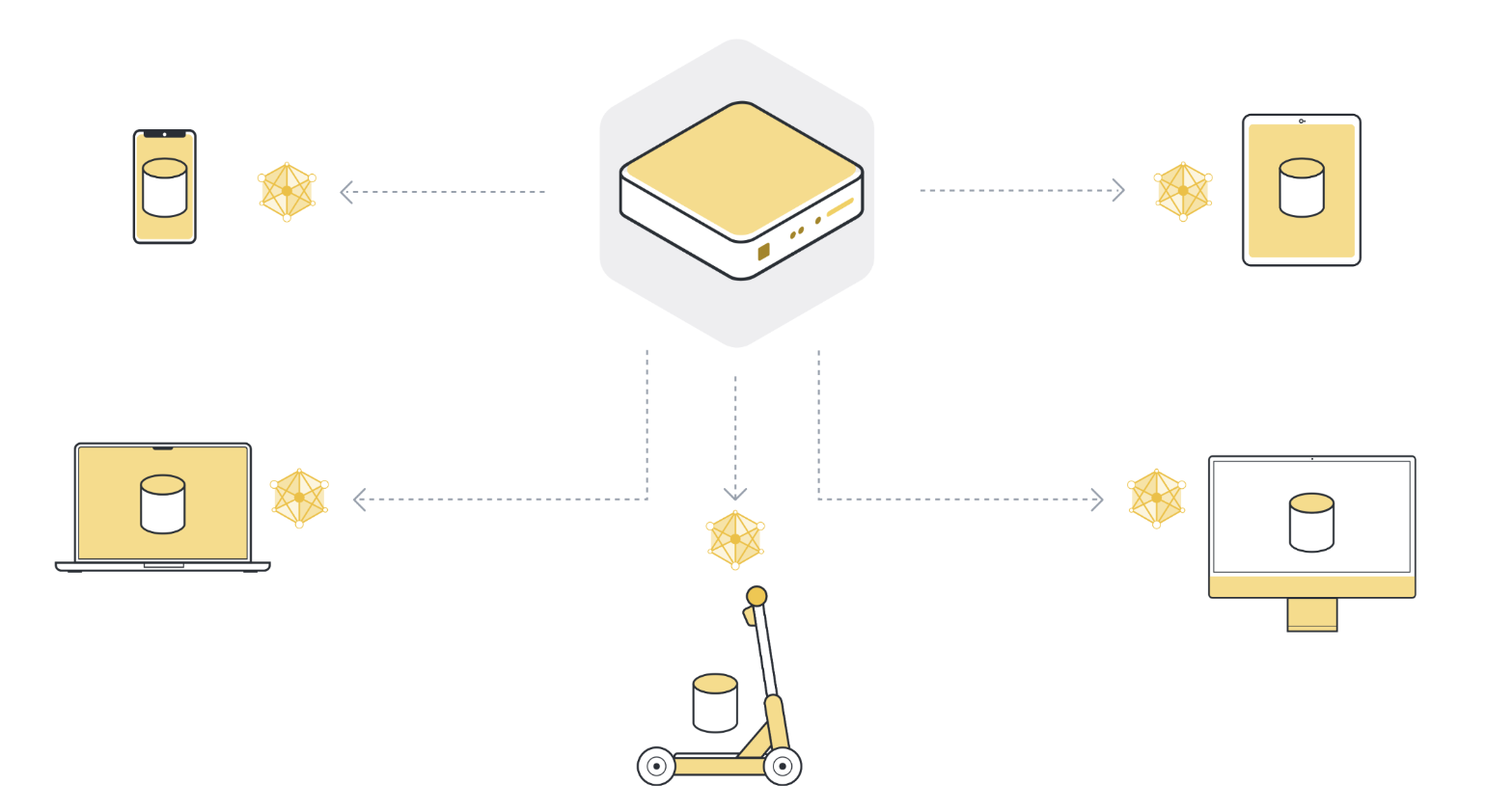
2단계: 각 조직/장치(클라이언트 노드)의 데이터에 대해 로컬로 모델 훈련¶
이제 모든(선택된) 클라이언트 노드에는 최신 버전의 글로벌 모델 파라미터가 있으며 로컬 훈련을 시작합니다. 그들은 자신의 로컬 데이터 세트를 사용하여 자신의 로컬 모델을 훈련합니다. 모델이 완전히 수렴할 때까지 훈련하지 않고 잠시만 훈련합니다. 이는 로컬 데이터에서 한 단계 정도로 짧거나 몇 단계(mini-batches)에 불과할 수 있습니다.
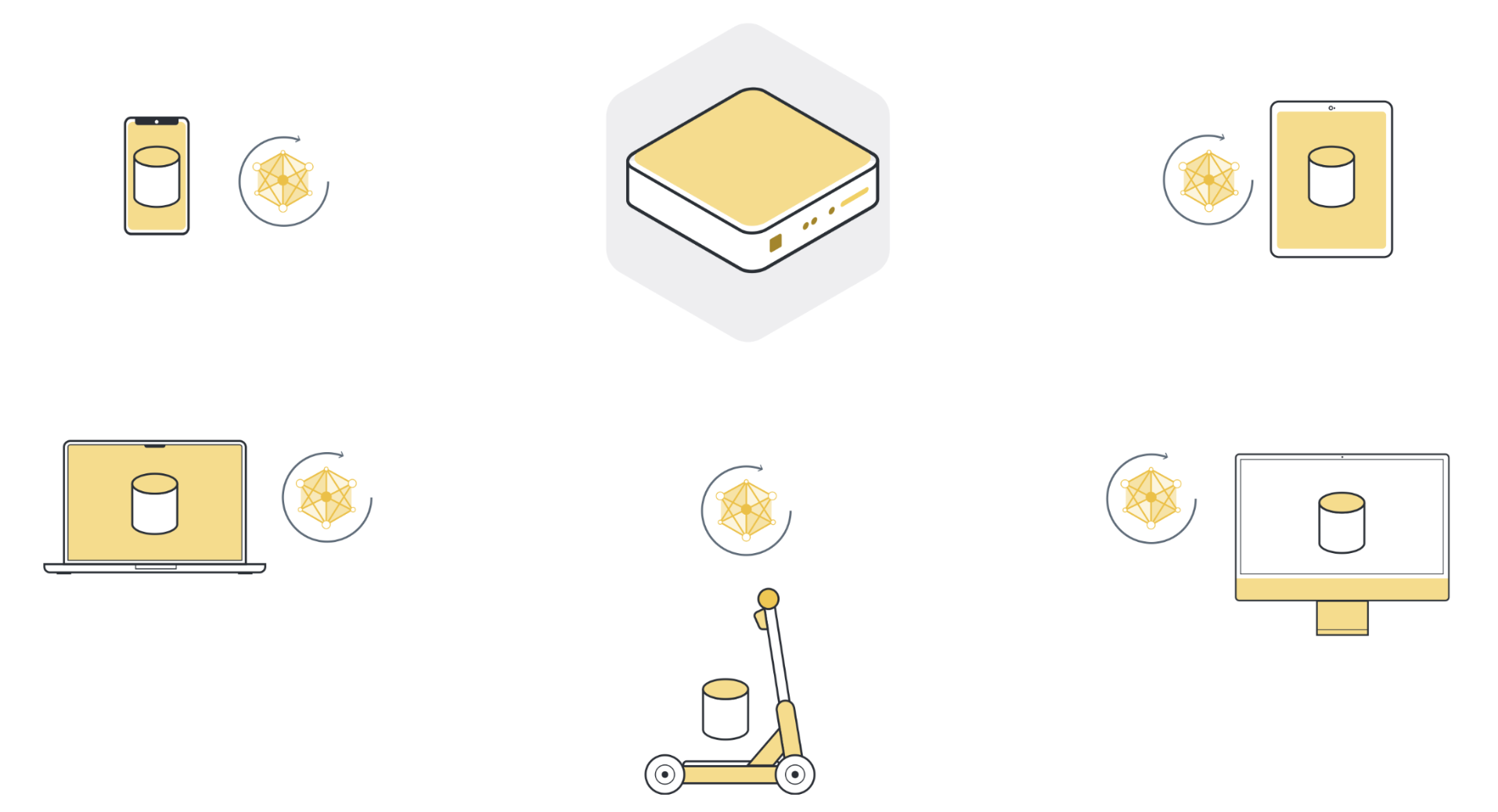
3단계: 모델 파라미터를 업데이트하여 서버로 되돌리기¶
로컬 훈련 후에는 클라이언트 노드마다 원래 받은 모델 파라미터의 버전이 조금씩 다릅니다. 파라미터가 다른 이유는 각 클라이언트 노드의 로컬 데이터 세트에 다른 데이터가 있기 때문입니다. 그런 다음 클라이언트 노드는 이러한 모델 업데이트를 서버로 다시 보냅니다. 보내는 모델 업데이트는 전체 모델 파라미터거나 로컬 교육 중에 누적된 그레디언트(gradient)일 수 있습니다.
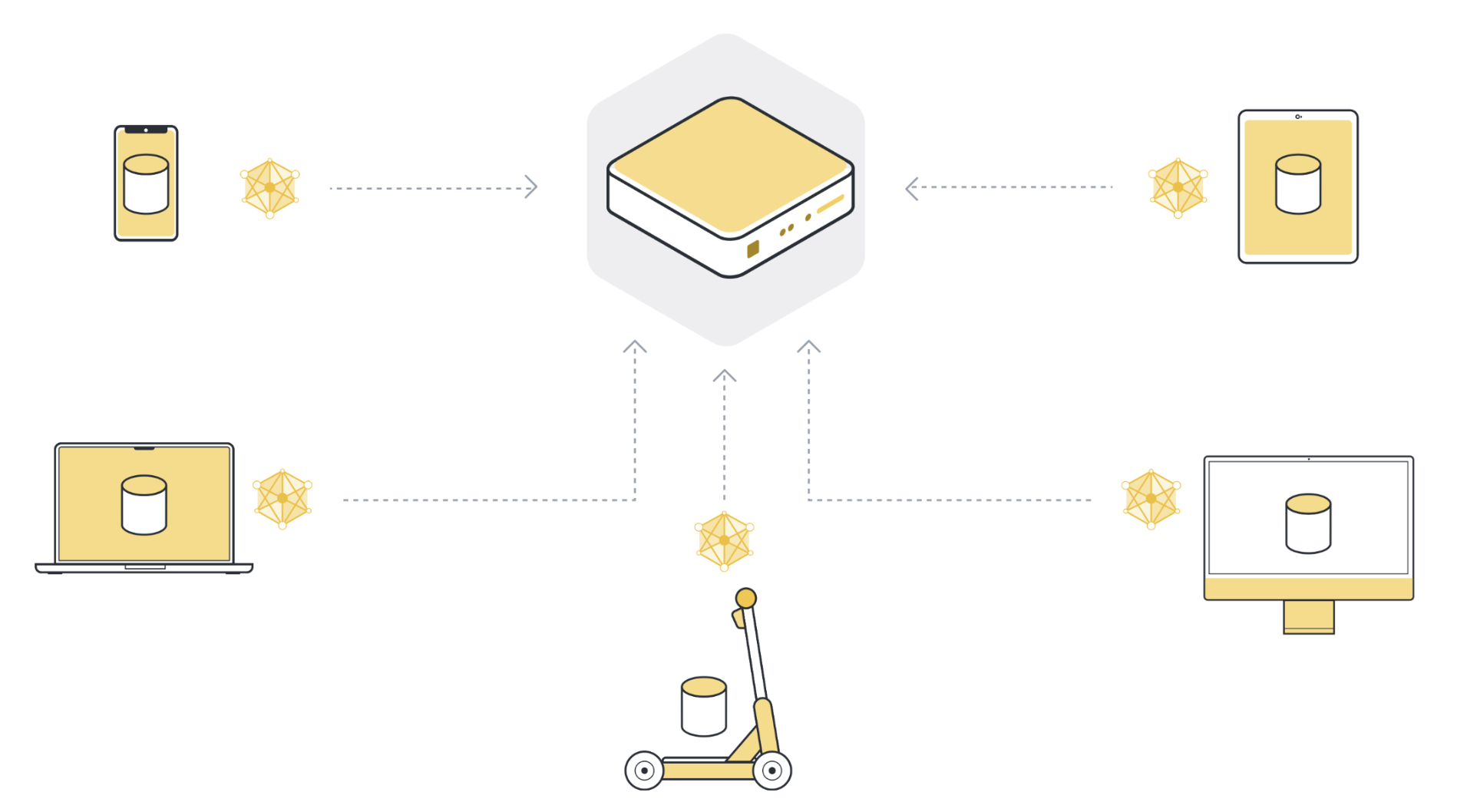
4단계: 모델 업데이트를 새 글로벌 모델로 집계¶
서버는 선택된 클라이언트 노드들로부터 모델 업데이트들을 수신합니다. 서버가 100개의 클라이언트 노드를 선택했다면 이제 각각 클라이언트의 로컬 데이터를 기반으로 훈련된 100개의 조금씩 다른 원래 글로벌 모델 버전을 갖게 됩니다. 하지만 우리는 100개의 모든 클라이언트 노드의 데이터에서 학습한 내용을 포함하는 모델을 하나만 갖고 싶지 않았습니까?
In order to get one single model, we have to combine all the model updates we received from the client nodes. This process is called aggregation, and there are many different ways to do it. The most basic way is called Federated Averaging (McMahan et al., 2016), often abbreviated as FedAvg. FedAvg takes the 100 model updates and, as the name suggests, averages them. To be more precise, it takes the weighted average of the model updates, weighted by the number of examples each client used for training. The weighting is important to make sure that each data example has the same “influence” on the resulting global model. If one client has 10 examples, and another client has 100 examples, then - without weighting - each of the 10 examples would influence the global model ten times as much as each of the 100 examples.
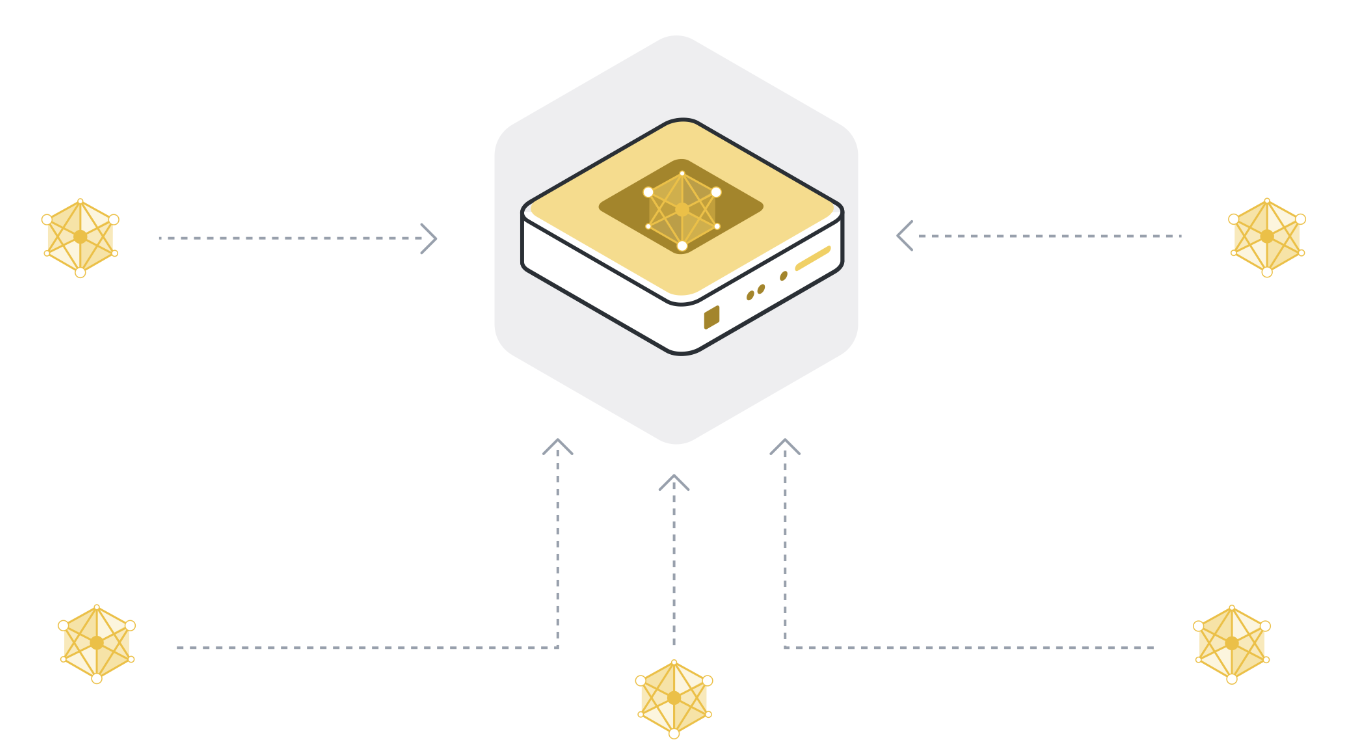
5단계: 모델이 수렴할 때까지 1~4단계를 반복합니다¶
단계 1에서 4는 우리가 말하는 단일 라운드 연합 학습입니다. 글로벌 모델 파라미터는 참여하는 클라이언트 노드에 전송되고(1단계), 클라이언트 노드는 로컬 데이터에 대한 훈련을 받고(2단계), 업데이트된 모델을 서버에 전송하고(3단계), 서버는 모델 업데이트를 집계하여 글로벌 모델의 새로운 버전을 얻습니다(4단계).
한 라운드의 반복에서 해당 반복에 참여하는 각 클라이언트 노드는 짧은 시간 동안만 훈련합니다. 집계 단계(4단계) 이후 우리 모델이 관련된 모든 클라이언트 노드의 모든 데이터에 대해 잠시 동안만 훈련되었음을 의미합니다. 그런 다음 모든 클라이언트 노드의 데이터에서 잘 작동하는 완전히 훈련된 모델에 도달하려면 이 훈련 과정을 계속 반복해야 합니다.
결론¶
축하합니다, 이제 연합 학습의 기초에 대해 알게 되었습니다. 물론 아직 논의해야 할 내용이 많지만 이는 연합 학습의 축소판일 뿐입니다. 본 튜토리얼의 후반부에는 좀 더 자세히 설명하겠습니다. 흥미로운 질문은 다음과 같습니다: 다음 라운드에 참여해야 할 가장 좋은 클라이언트 노드를 어떻게 선택할 수 있을까요? 모델 업데이트를 집계하는 가장 좋은 방법은 무엇일까요? 실패한 클라이언트 노드(낙오자)를 어떻게 처리할 수 있을까요?
연합 평가¶
다양한 클라이언트 노드의 분산된 데이터에 대해 모델을 훈련할 수 있는 것처럼 해당 데이터에 대한 모델을 평가하여 가치 있는 메트릭(metrics)을 받을 수도 있습니다. 이를 연합 평가라고 하며 FE라고 약칭하기도 합니다. 사실 연합 평가는 대부분의 연합 학습 시스템에서 필수적인 부분입니다.
Federated Analytics¶
많은 경우 머신러닝은 데이터로부터 가치를 얻기 위한 필수 조건이 아닙니다. 데이터 분석을 통해 귀중한 통찰력을 얻을 수 있지만, 명확한 답변을 얻기에는 데이터가 충분하지 않은 경우가 많습니다. 특정 유형의 건강 상태가 발생하는 평균 연령은 몇 살입니까? 연합 분석을 사용하면 여러 클라이언트 노드에서 이러한 쿼리(query)를 실행할 수 있습니다. 서버가 단일 클라이언트 노드에서 제출한 결과를 보지 못하도록 보안을 강화한 집합 방식과 같은 다른 프라이버시 향상 기술과 함께 자주 사용됩니다.
차등 프라이버시¶
Differential privacy (DP) is often mentioned in the context of Federated Learning. It is a privacy-preserving method used when analyzing and sharing statistical data, ensuring the privacy of individual participants. DP achieves this by adding statistical noise to the model updates, ensuring any individual participants’ information cannot be distinguished or re-identified. This technique can be considered an optimization that provides a quantifiable privacy protection measure.
Flower¶
연합 학습, 연합 평가 및 연합 분석은 머신러닝 모델을 앞뒤로 이동하고 로컬 데이터에 대해 훈련 및 평가한 다음 업데이트된 모델을 통합하기 위한 기본 프레임워크가 필요합니다. Flower가 제공하는 기반 구조는 간단하고 확장 가능하며 안전한 방식으로 이러한 목표를 달성합니다. 간단히 말해서, Flower는 연합 학습, 분석 및 평가를 위한 통합 접근 방식을 제공합니다. 이를 통해 사용자는 모든 워크로드, 머신러닝 프레임워크 및 모든 프로그래밍 언어를 통합할 수 있습니다.
Final Remarks¶
Congratulations, you just learned the basics of federated learning and how it relates to classic centralized machine learning.
In the next tutorial, you will take the first practical step with Flower: create a simulated federation on SuperGrid, run an existing Flower App from Flower Hub, and use the SuperGrid dashboard to follow the run and inspect its logs.
다음 단계¶
Before you continue, make sure to join the Flower community on Flower Discuss (Join Flower Discuss) and on Slack (Join Slack).
There’s a dedicated #questions Slack channel if you need help, but we’d also love to
hear who you are in #introductions!
The Flower Collaborative AI Tutorial - Part 1: Get started with Flower shows how to create your first federation on SuperGrid and run a Flower App without writing code.