Qu’est-ce que l’apprentissage fédéré ?¶
Bienvenue au tutoriel sur l’apprentissage fédéré de Flower !
Dans ce tutoriel, vous allez apprendre ce qu’est l’apprentissage fédéré, construire votre premier système en Flower et l’étendre progressivement. Si vous passez par toutes les parties du tutoriel, vous serez capable de construire des systèmes d’apprentissage fédéré avancés qui approchent l’état actuel de l’art dans le domaine.
🧑🏫 Ce tutoriel commence à zéro et ne suppose aucune familiarité avec l’apprentissage fédéré. Seule une compréhension de base des sciences des données et du programmation Python est supposée.
Astuce
Star Flower on GitHub ⭐️ et rejoignez la communauté Flower sur Flower Discuss ou Flower Slack pour vous présenter, poser des questions et obtenir de l’aide.
Dites-vous bonjour !
L’apprentissage classique¶
Avant de discuter de l’apprentissage fédéré, rappelons rapidement comment fonctionne la plupart de l’apprentissage automatique aujourd’hui.
Dans l’apprentissage automatique, nous avons un modèle et des données. Le modèle peut être un réseau neuronal (comme illustré ici), ou quelque chose d’autre, comme la régression linéaire classique.

Nous entraînons le modèle en utilisant les données pour effectuer une tâche utile. Une tâche peut consister à détecter des objets dans des images, à transcrire un enregistrement audio ou à jouer à un jeu comme le Go.

Dans la pratique, les données d’entraînement que nous travaillons ne proviennent pas du machine sur lequel on entraîne le modèle.
Ces données sont créées “d’ailleurs”. Par exemple, les données peuvent provenir d’un smartphone par l’utilisateur qui interagit avec une application, d’une voiture collectant des données de capteur, d’un ordinateur portable recevant des entrées via la touche, ou d’un haut-parleur intelligent enregistrant quelqu’un essayant de chanter une chanson.

Ce que l’on doit également mentionner, c’est que ce “d’ailleurs” n’est généralement pas un seul endroit, mais plusieurs. Cela pourrait être plusieurs appareils tous exécutant la même application. Mais cela pourrait aussi être plusieurs organisations, toutes générant des données pour la même tâche.
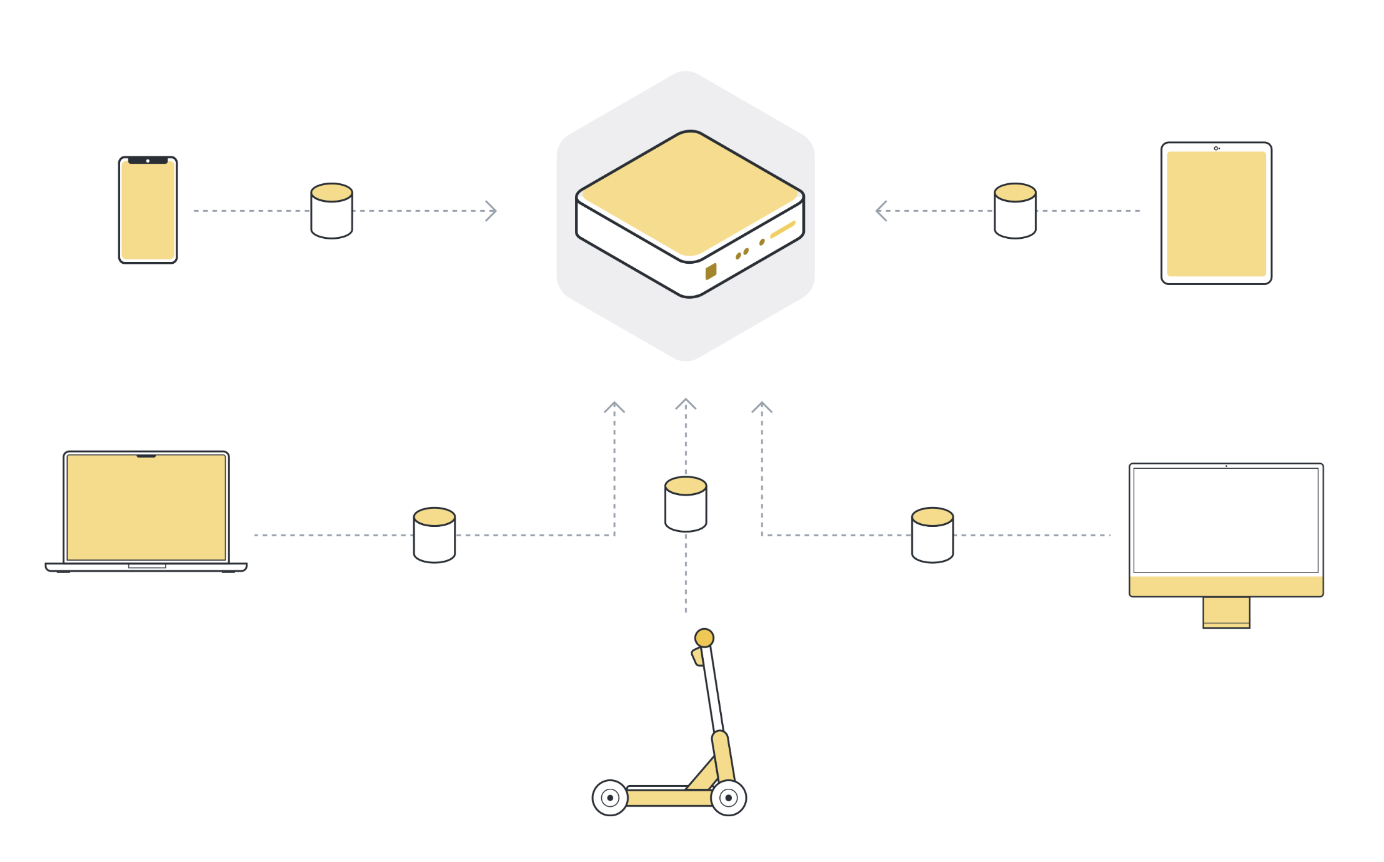
Pour utiliser l’apprentissage automatique ou toute sorte d’analyse de données, l’approche qui a été utilisée dans le passé était de collecter toutes ces données sur un serveur central. Ce serveur peut être situé quelque part dans un centre de données, ou quelque part dans le cloud.
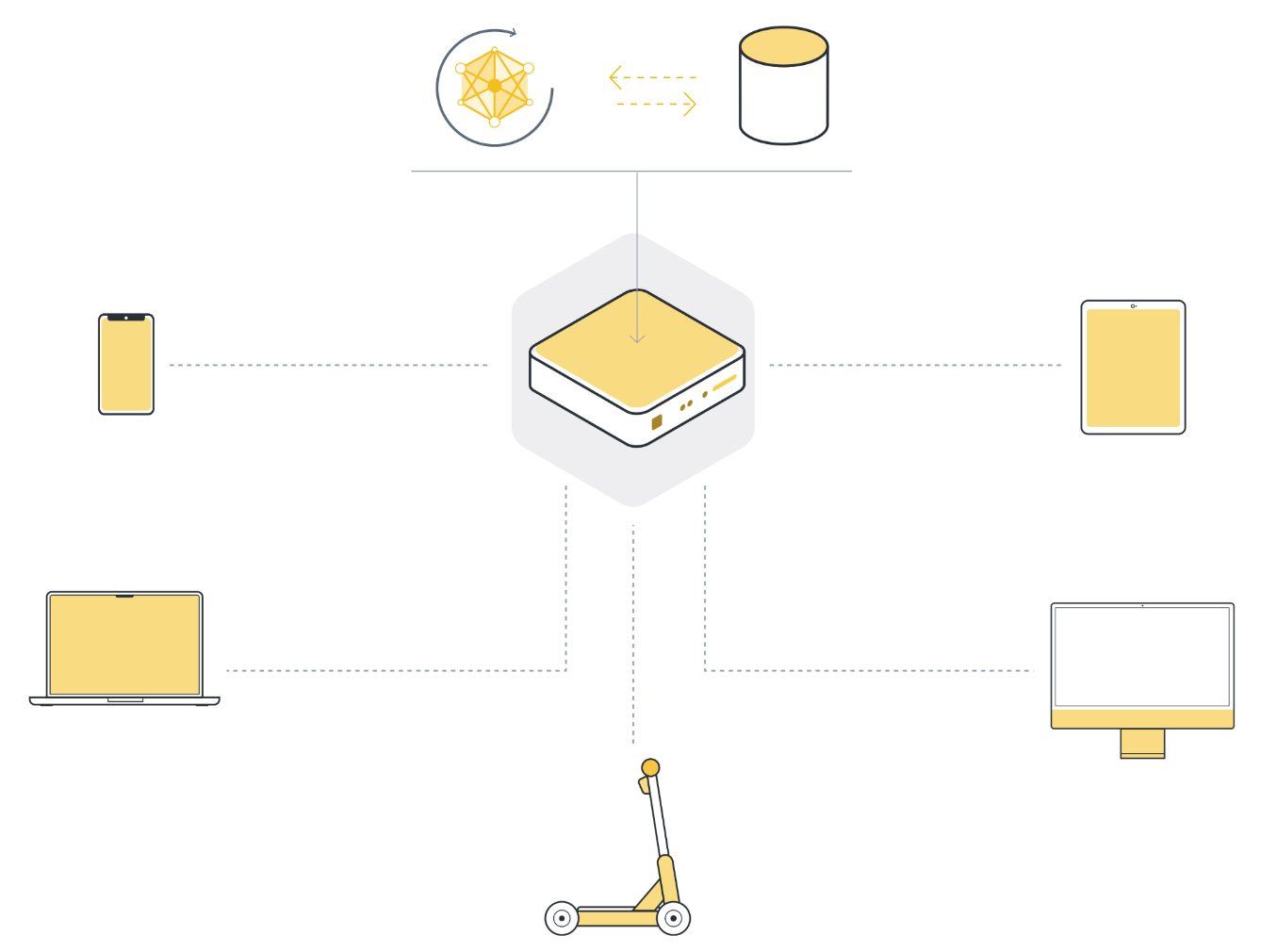
Une fois que toutes les données sont collectées en un seul endroit, nous pouvons finalement utiliser des algorithmes d’apprentissage automatique pour entraîner notre modèle sur les données. C’est l’approche classique d’apprentissage automatique que nous avons utilisée jusqu’à présent.
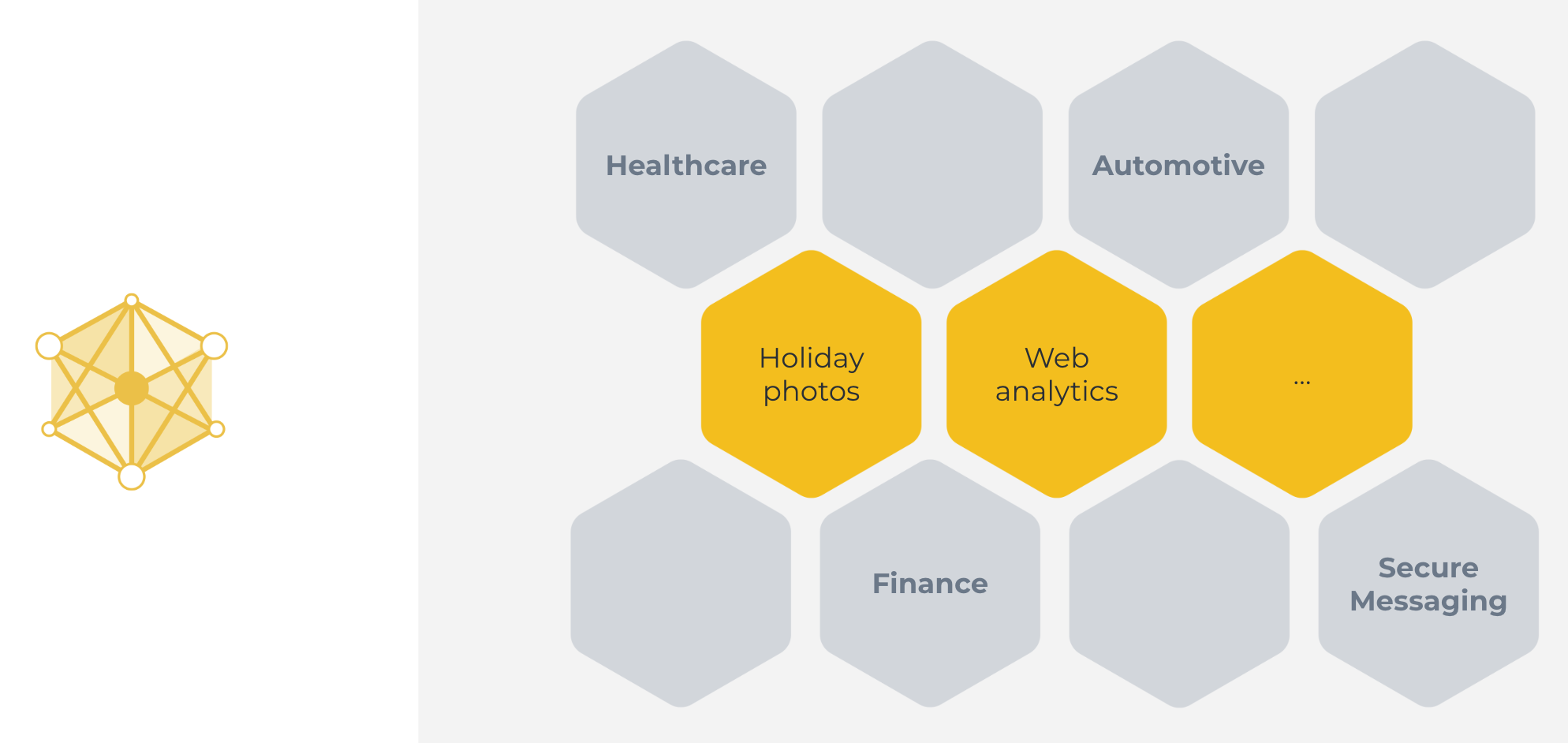
Les défis de l’apprentissage automatique classique¶
Cette approche classique d’apprentissage automatique centralisé que nous venons de voir peut être utilisé dans certains cas. De grands exemples incluent la catégorisation des photos de vacances, ou l’analyse du trafic web. Des cas où toutes les données sont naturellement disponibles sur un serveur central.

Mais cette approche ne peut pas être utilisée dans de nombreux autres cas : lorsque les données ne sont pas disponibles sur un serveur centralisé, ou lorsque les données disponibles sur un serveur ne sont pas suffisantes pour entraîner un bon modèle.
Existe de nombreuses raisons pour lesquelles l’approche classique d’apprentissage automatique centralisé ne fonctionne pas pour un grand nombre de cas réels importants dans le monde réel. Ces raisons incluent :
Règlementations : RGPD (Europe), CCPA (Californie), PIPEDA (Canada), LGPD (Brésil), PDPL (Argentine), KVKK (Turquie), POPI (Afrique du Sud), FSS (Russie), CDPR (Chine), PDPB (Inde), PIPA (Corée), APPI (Japon), PDP (Indonésie) et autres réglementations protègent les données sensibles d’être déplacées. En fait, certaines de ces réglementations empêchent même parfois que des organisations individuelles combinent leurs propres données utilisateurs pour l’entraînement à l’apprentissage automatique car ces utilisateurs vivent dans différentes parties du monde et leurs données sont régies par différentes réglementations de protection des données.
Préférence de l’utilisateur : En plus de la réglementation, il existe des cas d’utilisation où les utilisateurs s’attendent tout simplement à ce qu’aucune donnée ne quitte leur appareil, jamais. Si tu tapes tes mots de passe et tes informations de carte de crédit sur le clavier numérique de ton téléphone, tu ne t’attends pas à ce que ces mots de passe finissent sur le serveur de l’entreprise qui a développé ce clavier, n’est-ce pas ? En fait, ce cas d’utilisation est la raison pour laquelle l’apprentissage fédéré a été inventé en premier lieu.
Volume de données : Certaines capteurs, comme les caméras, produisent un tel volume de données que ce n’est ni faisable ni économique de collecter toutes les données (par exemple en raison du débit ou de l’efficacité de la communication). Pensez à un service ferroviaire national avec des centaines d’agences de voyage dans tout le pays. Si chaque agence de voyage est équipée d’un certain nombre de caméras de sécurité, le volume de données brutes sur les appareils qu’ils produisent nécessite une infrastructure incroyablement puissante et extrêmement coûteuse pour traiter et stocker. Et la plupart des données n’en ont même pas besoin.
Voici quelques exemples où l’apprentissage automatique centralisé ne fonctionne pas :
Données de santé sensibles provenant de plusieurs hôpitaux pour entraîner des modèles de détection du cancer.
Informations financières provenant de différentes organisations pour détecter la fraude financière.
Données de localisation de votre voiture électrique pour améliorer les prédictions de portée.
Messages chiffrés à bout ouvert pour entraîner des modèles d’autocomplétion meilleurs.
La popularité de systèmes qui améliorent la confidentialité, comme le navigateur Brave ou le messager Signal, montre que les utilisateurs s’intéressent à la confidentialité. En fait, ils choisissent la version qui améliore la confidentialité plutôt qu’autres alternatives, si telles alternatives existent. Mais quoi pouvons-nous faire pour appliquer l’apprentissage automatique et les sciences des données dans ces cas afin d’utiliser des données privées ? Après tout, ces sont tous des domaines qui bénéficieraient significativement des progrès récents en intelligence artificielle.
Apprentissage fédéré¶
L’apprentissage fédéré inverse cette approche. Il permet l’apprentissage automatique sur des données réparties en déplaçant l’entraînement vers les données, au lieu de déplacer les données vers l’entraînement. Voici une explication en un paragraphe :
Apprentissage automatique centralisé : déplacez les données vers la computation
Fédéré (machine) Apprentissage : déplacez la computation vers les données
En faisant cela, l’apprentissage fédéré nous permet d’utiliser l’apprentissage automatique (et d’autres approches de science des données) dans des domaines où il n’était pas possible auparavant. Nous pouvons maintenant former des modèles AI médicaux excellents en permettant à différents hôpitaux de travailler ensemble. Nous pouvons résoudre le fraude financière en formant des modèles AI sur les données de différentes institutions financières. Nous pouvons construire des applications novatrices qui améliorent la confidentialité (comme des messages sécurisés) qui ont une meilleure intelligence artificielle intégrée que leurs alternatives non-confidentielles. Et ceux-ci sont juste quelques-uns des exemples qui me viennent à l’esprit. Lorsque nous déployons l’apprentissage fédéré, nous découvrons de plus en plus d’aires qui peuvent soudainement être réinventées car elles ont maintenant accès à des quantités vastes de données précédemment inaccessibles.
Alors comment fonctionne l’apprentissage fédéré exactement ? Commencez par une explication intuitive.
L’apprentissage fédéré en cinq étapes¶
Étape 0 : Initialisation du modèle global¶
Nous commençons par initialiser le modèle sur le serveur. C’est exactement la même chose dans l’apprentissage centralisé classique : nous initialisons les paramètres du modèle, soit de façon aléatoire, soit à partir d’un point de contrôle précédemment sauvegardé.
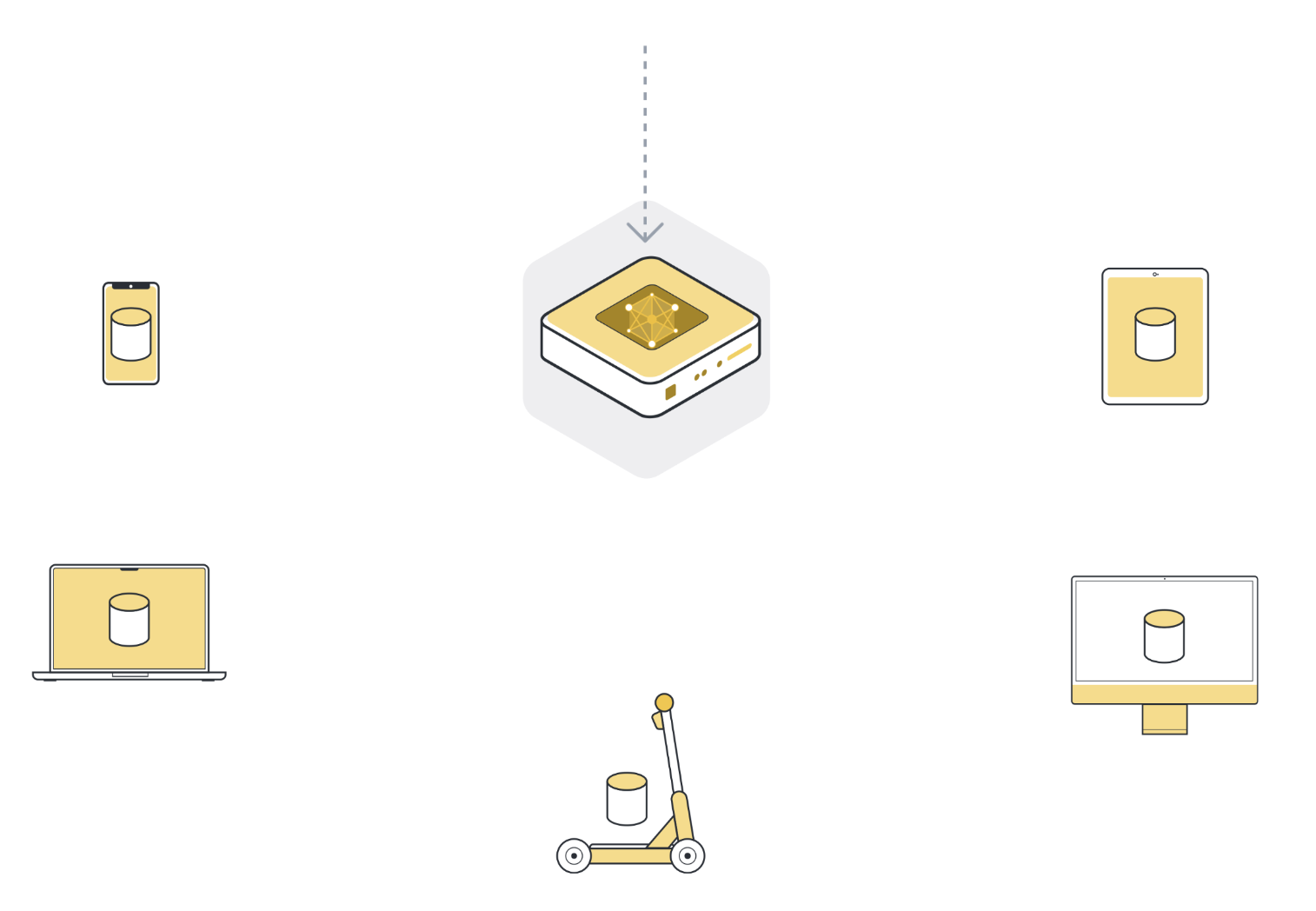
Étape 1 : envoyer le modèle à un certain nombre d’organisations/appareils connectés (nœuds clients)¶
Ensuite, nous envoyons les paramètres du modèle global aux nœuds clients connectés (pensez à des appareils d’interface utilisateur comme des smartphones ou des serveurs appartenant à des organisations). Cela est fait pour s’assurer que chaque nœud participant commence son entraînement local en utilisant les mêmes paramètres de modèle. Nous utilisons souvent uniquement quelques-uns des nœuds connectés au lieu de tous les nœuds. La raison de ceci est que la sélection de plus et plus de nœuds clients a des rendements diminuants.
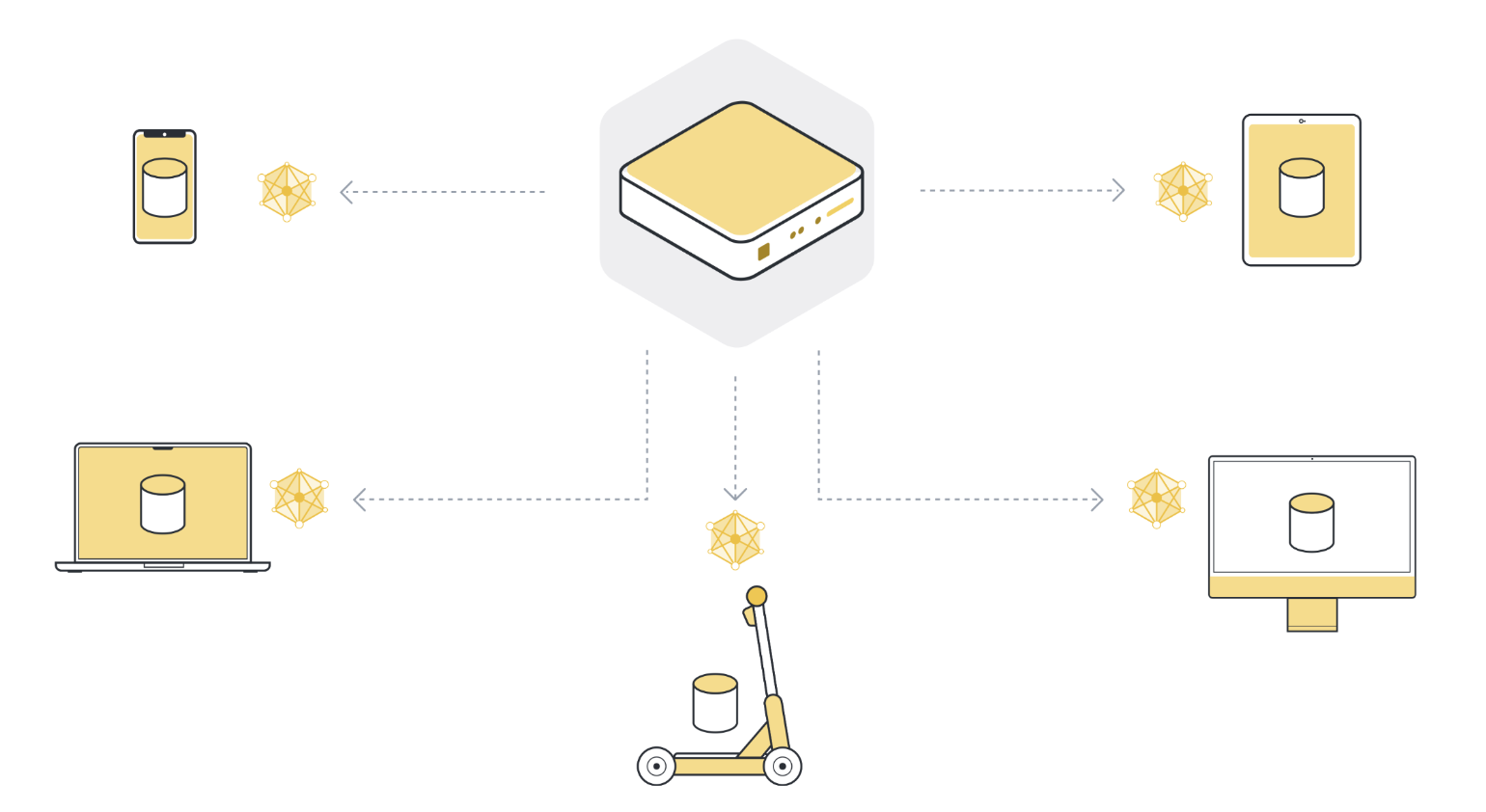
Étape 2 : Entraîne le modèle localement sur les données de chaque organisation/appareil (nœud client)¶
Maintenant que tous les nœuds clients (sélectionnés) disposent de la dernière version des paramètres du modèle global, ils commencent l’entraînement local. Ils utilisent leur propre ensemble de données locales pour entraîner leur propre modèle local. Ils n’entraînent pas le modèle jusqu’à la convergence totale, mais ils ne s’entraînent que pendant un petit moment. Il peut s’agir d’une seule époque sur les données locales, ou même de quelques étapes (mini-batchs).
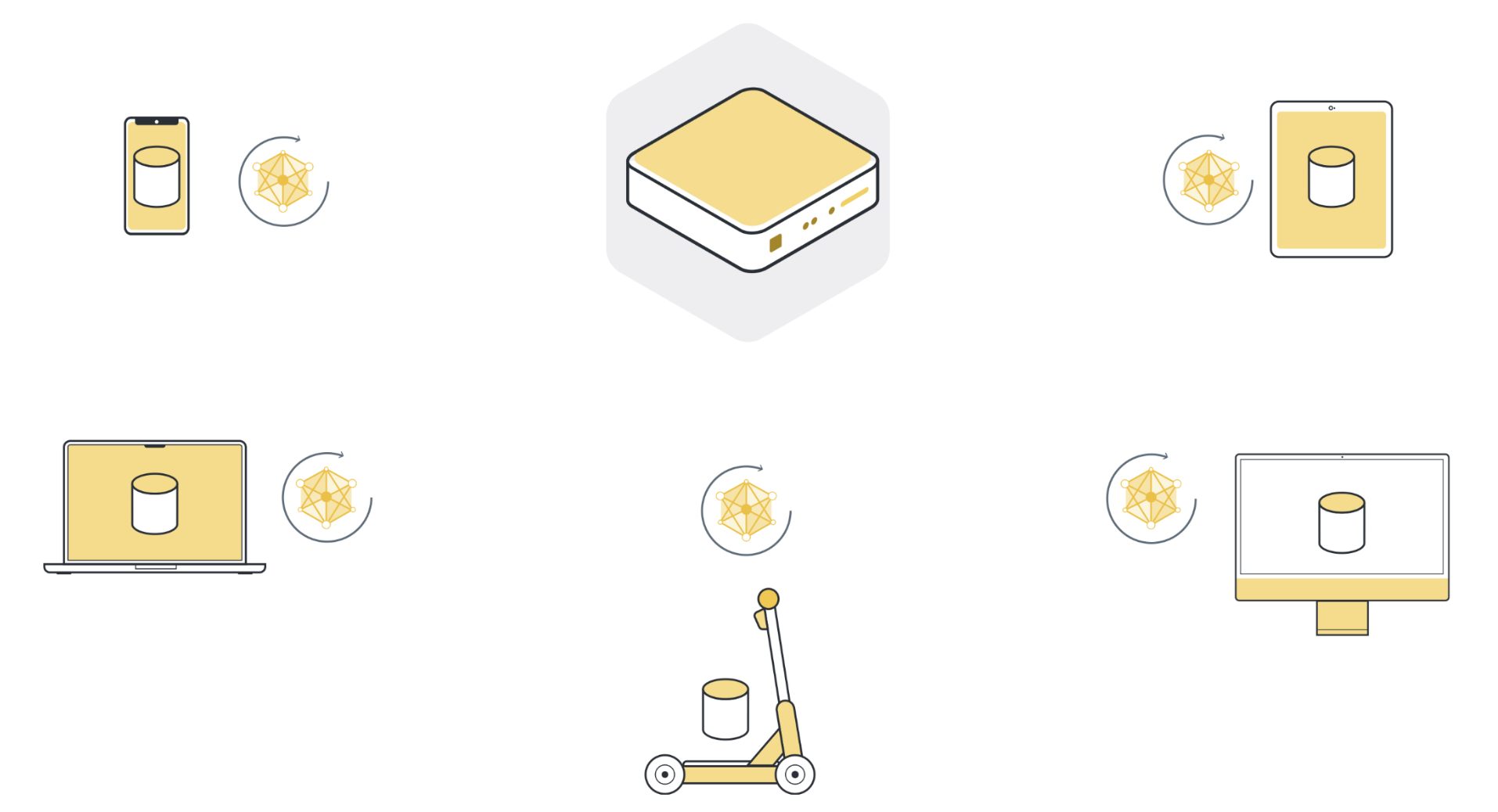
Étape 3 : Renvoyer les mises à jour du modèle au serveur¶
Après l’entraînement local, chaque nœud client possède une version légèrement différente des paramètres du modèle qu’il a reçus à l’origine. Les paramètres sont tous différents parce que chaque nœud client a des exemples différents dans son ensemble de données local. Les nœuds clients renvoient ensuite ces mises à jour du modèle au serveur. Les mises à jour du modèle qu’ils envoient peuvent être soit les paramètres complets du modèle, soit seulement les gradients qui ont été accumulés au cours de l’entraînement local.
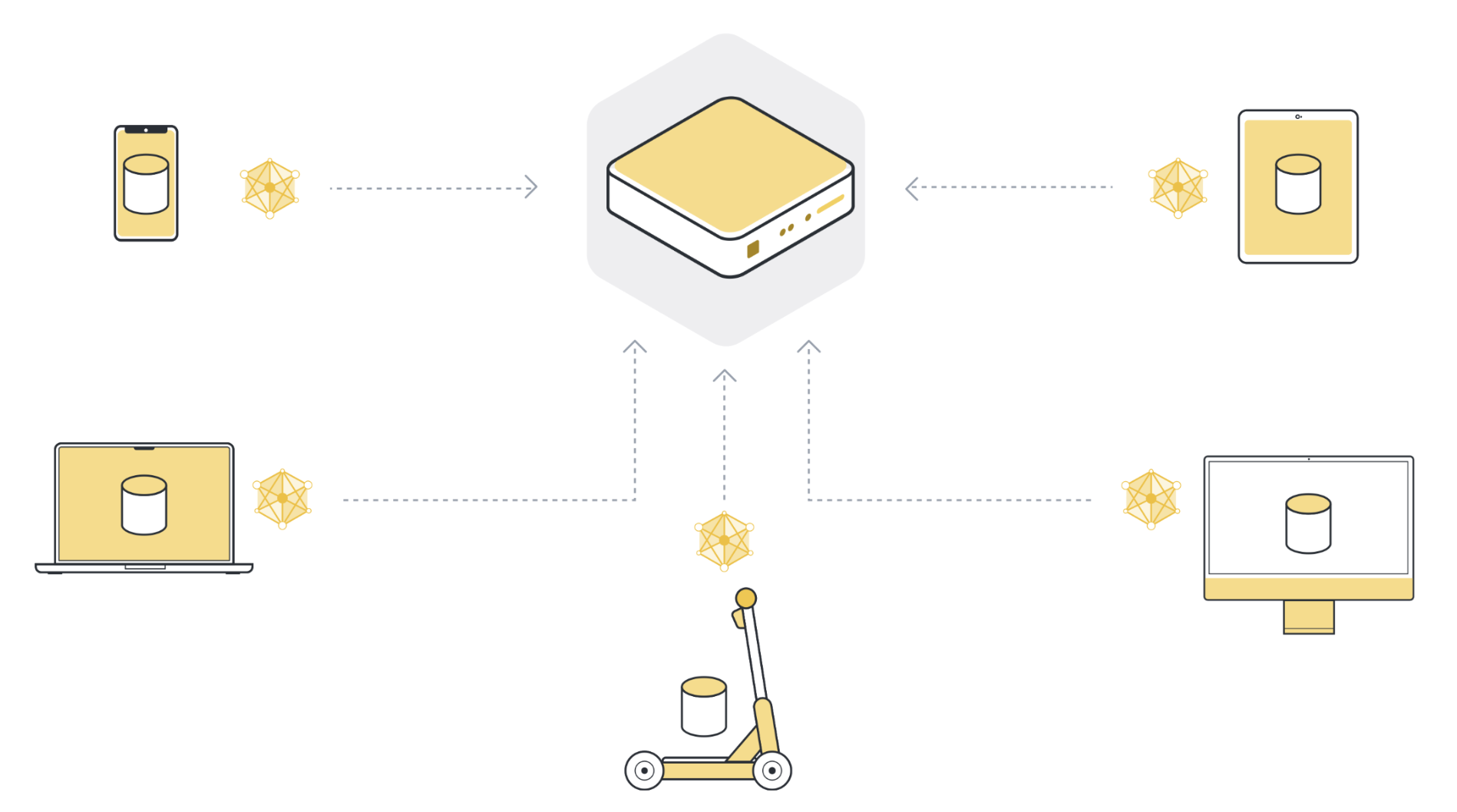
Étape 4 : Agréger les mises à jour des modèles dans un nouveau modèle global¶
Le serveur reçoit les mises à jour du modèle des nœuds clients sélectionnés. S’il a sélectionné 100 nœuds clients, il dispose maintenant de 100 versions légèrement différentes du modèle global original, chacune ayant été formée sur les données locales d’un client. Mais ne voulions-nous pas avoir un seul modèle qui contienne les apprentissages des données de l’ensemble des 100 nœuds clients ?
Pour obtenir un seul modèle, il faut combiner toutes les mises à jour de modèle que nous avons reçues des nœuds clients. Ce processus s’appelle agrégation, et il existe de nombreuses façons de le faire. La méthode la plus basique est appelée Fédération d’agrégation (McMahan et al., 2016), souvent abrégée en FedAvg. FedAvg prend les 100 mises à jour de modèle et, comme son nom l’indique, les moyenne. Pour être plus précis, il prend la moyenne pondérée des mises à jour de modèle, pondérées par le nombre d’exemples que chaque client a utilisés pour l’entraînement. Le pondération est importante pour s’assurer que chaque exemple de données a le même « influence » sur le modèle global résultant. Si un client a 10 exemples et un autre client a 100 exemples, alors - sans pondération - chacun des 10 exemples aurait une influence dix fois supérieure sur le modèle global par rapport à chaque l’un des 100 exemples.
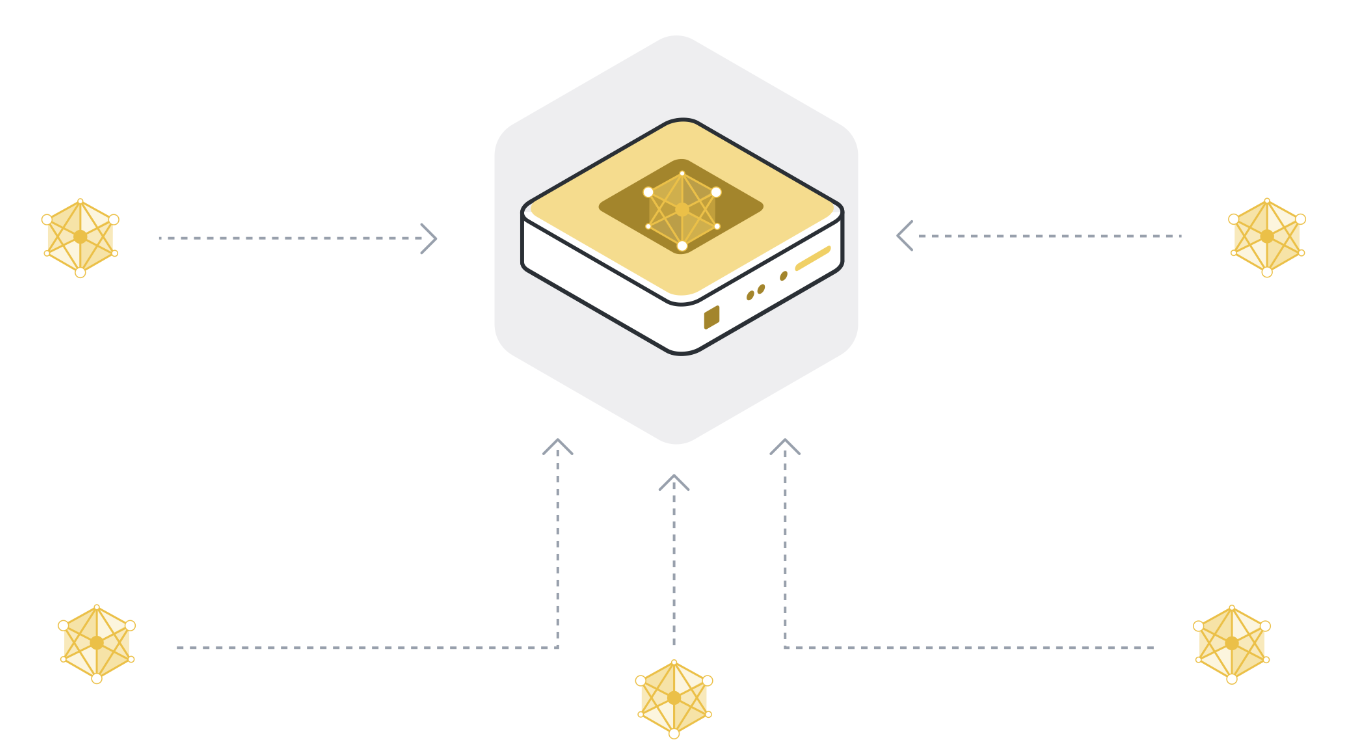
Étape 5 : répète les étapes 1 à 4 jusqu’à ce que le modèle converge¶
Les étapes 1 à 4 constituent ce que nous appelons un cycle unique d’apprentissage fédéré. Les paramètres du modèle global sont envoyés aux nœuds clients participants (étape 1), les nœuds clients s’entraînent sur leurs données locales (étape 2), ils envoient leurs modèles mis à jour au serveur (étape 3), et le serveur agrège ensuite les mises à jour du modèle pour obtenir une nouvelle version du modèle global (étape 4).
Au cours d’une seule itération, chaque nœud client qui participe à cette itération ne s’entraîne que pendant un peu de temps. Cela signifie que, après l’étape d’agrégation (étape 4), nous avons un modèle qui a été entraîné sur tous les données de tous les nœuds clients participant, mais seulement pour un peu de temps. Nous devons alors répéter ce processus d’entraînement à plusieurs reprises pour arriver finalement à un modèle entièrement entraîné qui fonctionne bien sur les données de tous les nœuds clients.
Conclusion¶
Félicitations, tu comprends maintenant les bases de l’apprentissage fédéré. Il y a bien sûr beaucoup plus à discuter, mais c’était l’apprentissage fédéré en quelques mots. Dans les parties suivantes de ce tutoriel, nous irons plus en détail. Les questions intéressantes comprennent : comment pouvons-nous sélectionner les meilleurs nœuds clients qui devraient participer au prochain tour ? Quelle est la meilleure façon d’agréger les mises à jour du modèle ? Comment pouvons-nous gérer les nœuds clients qui échouent (stragglers) ?
Federated Evaluation (évaluation fédérée)¶
Juste comme nous pouvons entraîner un modèle sur les données décentralisées des différents nœuds clients, nous pouvons également évaluer le modèle sur ces données pour obtenir des métriques précieuses. C’est appelé l’évaluation fédérée, parfois abrégée en FE. En fait, l’évaluation fédérée est une partie intégrante de la plupart des systèmes d’apprentissage fédéré.
Analytique Fédérée¶
Dans de nombreux cas, l’apprentissage automatique n’est pas nécessaire pour tirer de la valeur des données. L’analyse des données peut donner des indications précieuses, mais là encore, il n’y a souvent pas assez de données pour obtenir une réponse claire. Quel est l’âge moyen auquel les gens développent un certain type de problème de santé ? L’analyse fédérée permet de telles requêtes sur plusieurs nœuds clients. Elle est généralement utilisée en conjonction avec d’autres technologies de renforcement de la confidentialité, comme l’agrégation sécurisée, pour empêcher le serveur de voir les résultats soumis par les nœuds clients individuels.
Differential Privacy (confidentialité différentielle)¶
La confidentialité différentielle (DP) est souvent mentionnée dans le contexte de l’apprentissage fédéré. Il s’agit d’une méthode qui garantit la confidentialité individuelle lors de l’analyse et de la partage des données statistiques, en ajoutant du bruit statistique aux mises à jour de modèle pour empêcher toute identification ou re-identification individuelle. Cette technique peut être considérée comme une optimisation qui fournit une mesure de protection de la vie privée quantifiable.
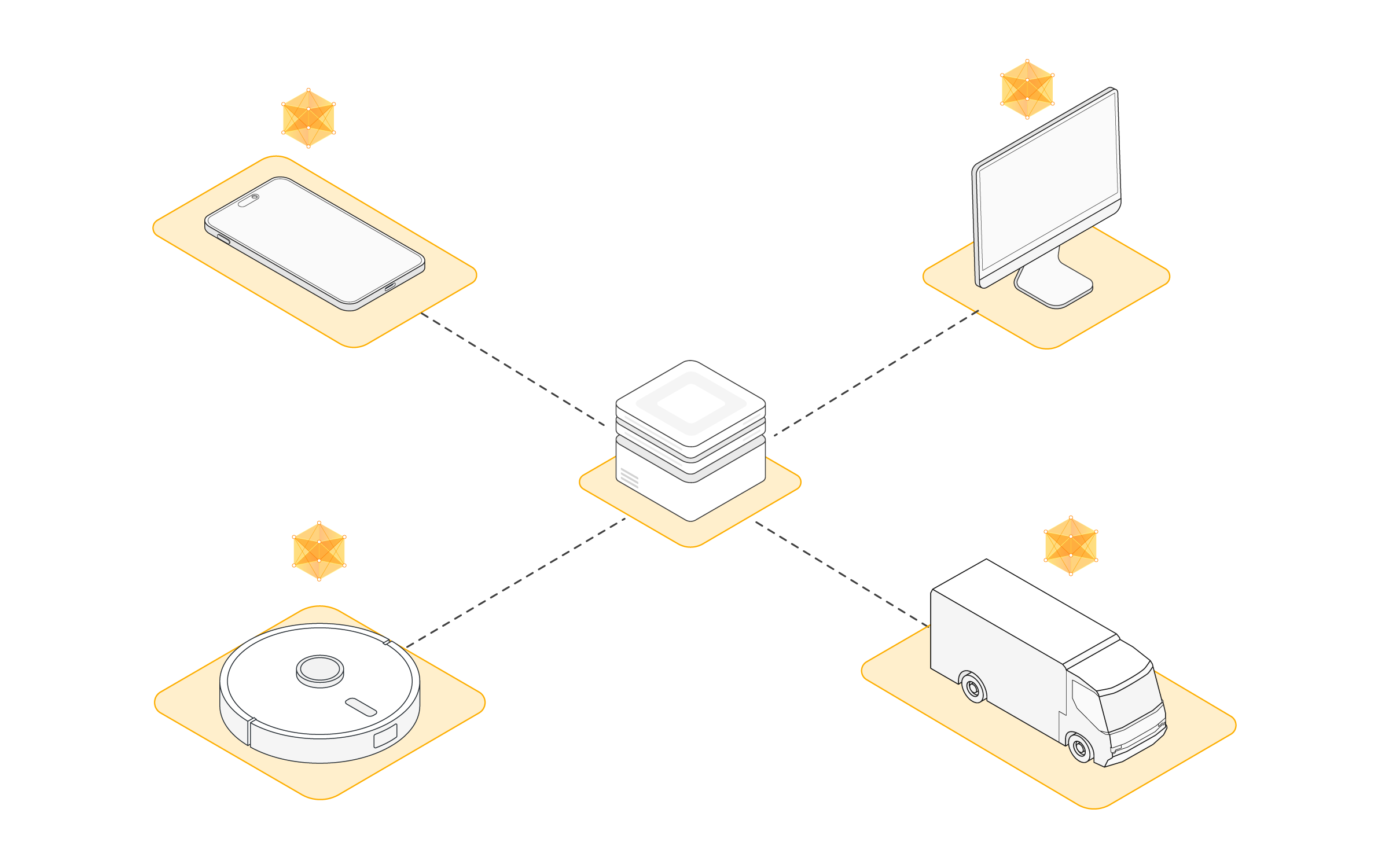
Flower¶
L’apprentissage fédéré, l’évaluation fédérée et l’analyse fédérée nécessitent une infrastructure pour déplacer les modèles d’apprentissage automatique dans les deux sens, les entraîner et les évaluer sur des données locales, puis agréger les modèles mis à jour. Flower fournit l’infrastructure pour faire exactement cela de manière simple, évolutive et sécurisée. En bref, Flower présente une approche unifiée de l’apprentissage, de l’analyse et de l’évaluation fédérés. Il permet à l’utilisateur de fédérer n’importe quelle charge de travail, n’importe quel cadre de ML et n’importe quel langage de programmation.
Remarques Finales¶
Félicitations, vous venez d’apprendre les bases de l’apprentissage fédéré et de leur relation avec l’apprentissage classique centralisé.
Dans le prochain tutoriel, vous allez prendre la première étape pratique avec Flower : créer une fédération simulée sur SuperGrid, exécuter une application Flower existante depuis Flower Hub, et utiliser l’interface de dashboard de SuperGrid pour suivre l’exécution et inspecter ses journaux.
Prochaines étapes¶
Avant de continuer, assurez-vous d’adhérer à la communauté Flower sur Flower Discuss (Join Flower Discuss) et Slack (Join Slack).
Il existe un canal Slack dédié si vous avez besoin d’aide, mais nous aimerions également entendre qui vous êtes dans #introductions !
Le Flower Collaborative AI Tutorial - Part 1: Get started with Flower montre comment créer votre première fédération sur SuperGrid et exécuter une application Flower sans écrire du code.