什么是联邦学习?¶
欢迎阅读Flower联邦学习教程!
在本教程中,你将了解什么是联邦学习,用 Flower 搭建第一个系统,并逐步对其进行扩展。如果你能完成本教程的所有部分,你就能构建高级的联邦学习系统,从而接近该领域当前的技术水平。
🧑🏫 This tutorial starts from zero and expects no familiarity with federated learning. Only a basic understanding of data science and Python programming is assumed.
Tip
Star Flower on GitHub ⭐️ and join the Flower community on Flower Discuss or Flower Slack to introduce yourself, ask questions, and get help.
让我们开始吧!
Classical Machine Learning¶
Before we begin discussing federated learning, let us quickly recap how most machine learning works today.
在机器学习中,我们有一个模型和数据。模型可以是一个神经网络(如图所示),也可以是其他东西,比如经典的线性回归。

我们使用数据来训练模型,以完成一项有用的任务。任务可以是检测图像中的物体、转录音频或玩围棋等游戏。

In practice, the training data we work with doesn't originate on the machine we train the model on.
This data gets created “somewhere else”. For instance, the data can originate on a smartphone by the user interacting with an app, a car collecting sensor data, a laptop receiving input via the keyboard, or a smart speaker listening to someone trying to sing a song.

What's also important to mention, this “somewhere else” is usually not just one place, it's many places. It could be several devices all running the same app. But it could also be several organizations, all generating data for the same task.
So to use machine learning, or any kind of data analysis, the approach that has been used in the past was to collect all this data on a central server. This server can be located somewhere in a data center, or somewhere in the cloud.
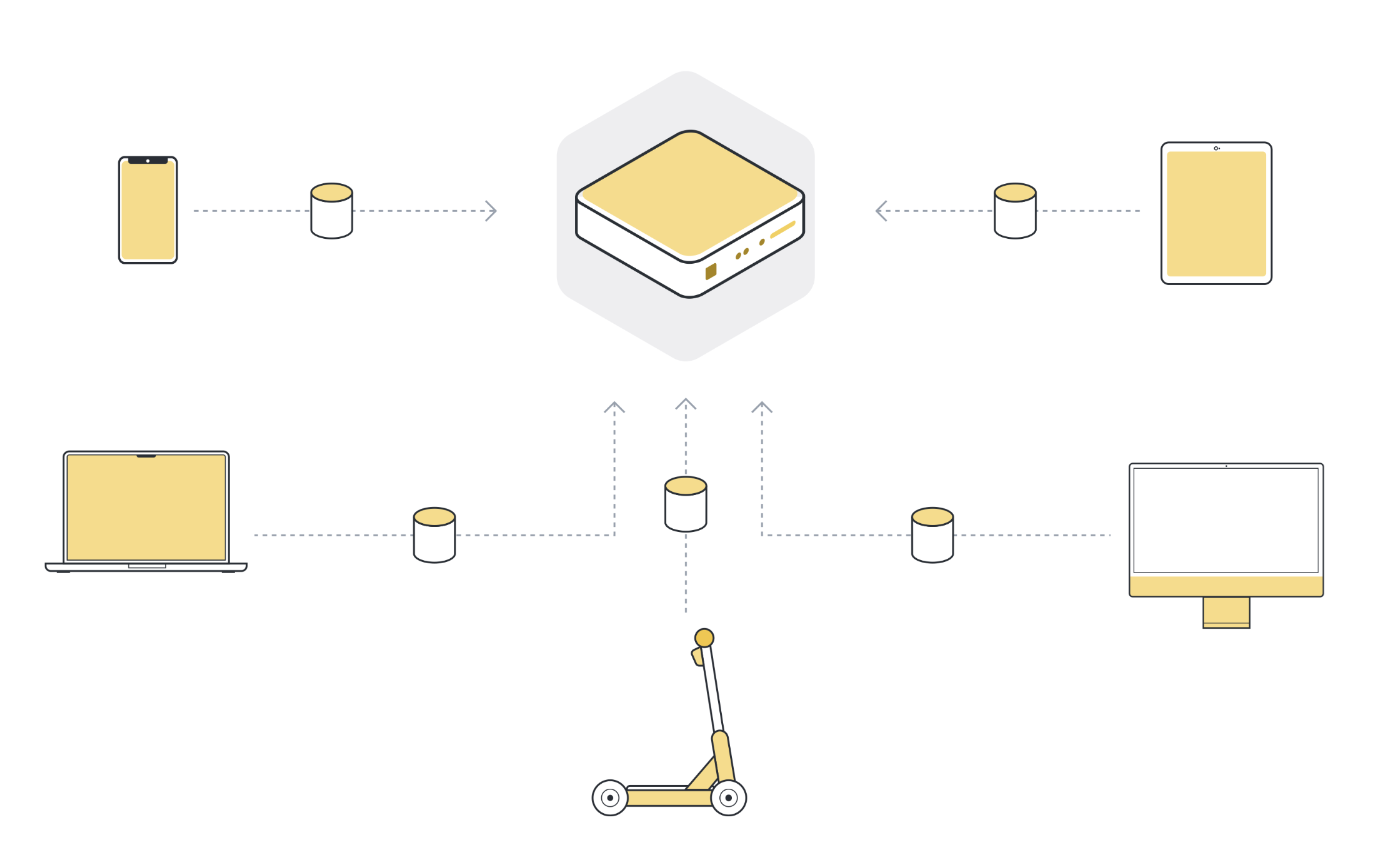
一旦所有数据都收集到一处,我们最终就可以使用机器学习算法在数据上训练我们的模型。这就是我们基本上一直依赖的机器学习方法。
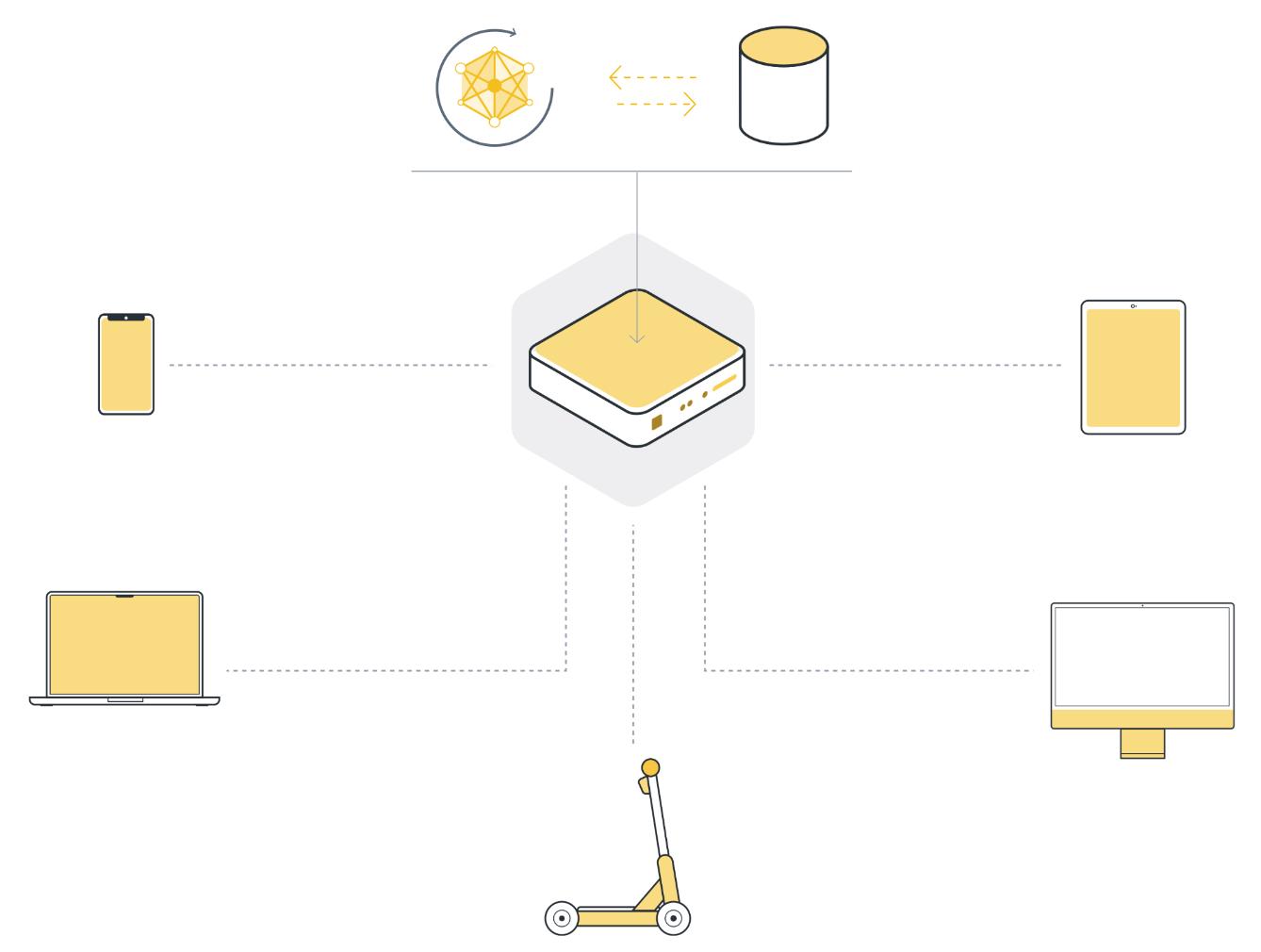
经典机器学习面临的挑战¶
This classical machine learning approach we've just seen can be used in some cases. Great examples include categorizing holiday photos, or analyzing web traffic. Cases, where all the data is naturally available on a centralized server.

但这种方法并不适用于许多其他情况。例如,集中服务器上没有数据,或者一台服务器上的数据不足以训练出一个好的模型。
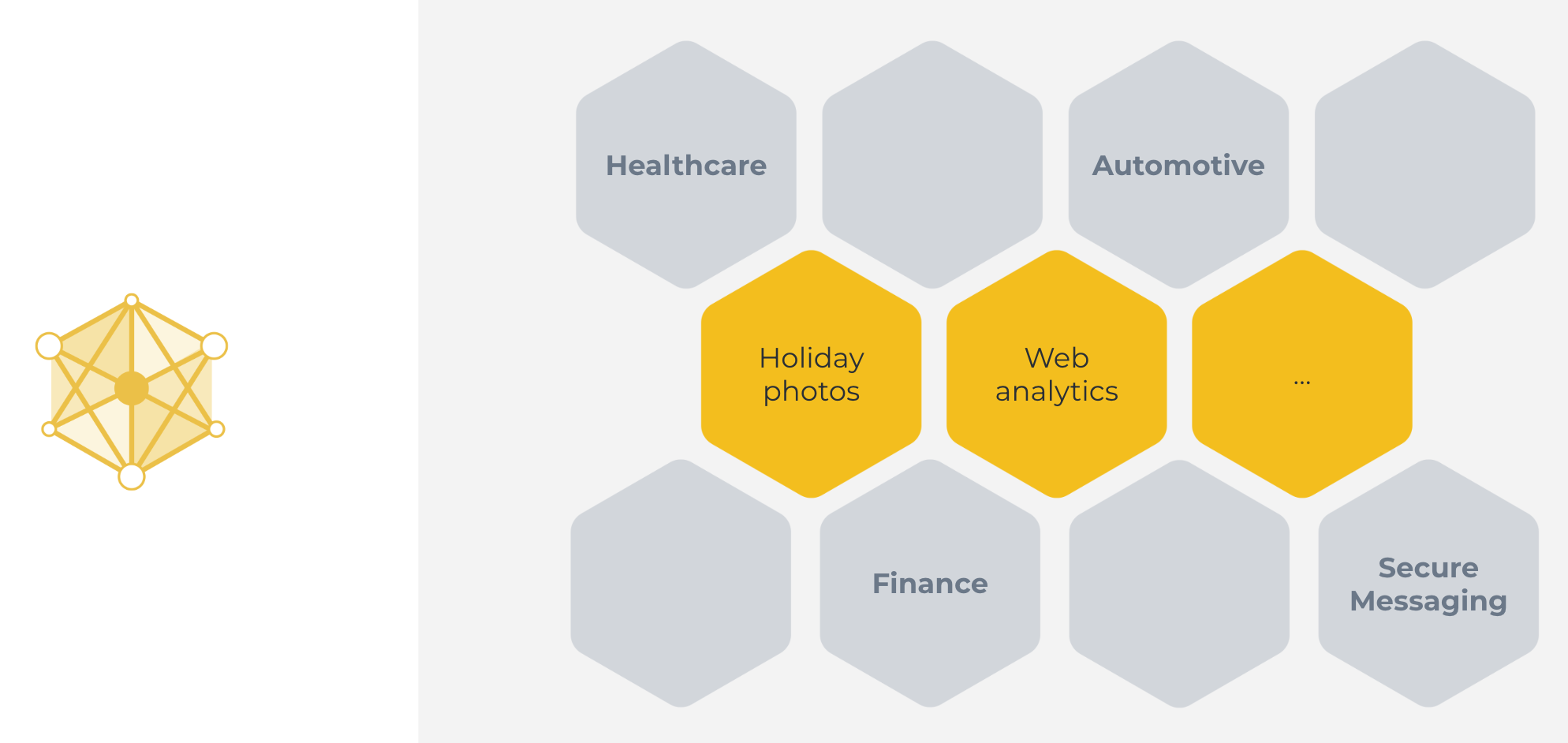
There are many reasons why the classical centralized machine learning approach does not work for a large number of highly important real-world use cases. Those reasons include:
Regulations: GDPR (Europe), CCPA (California), PIPEDA (Canada), LGPD (Brazil), PDPL (Argentina), KVKK (Turkey), POPI (South Africa), FSS (Russia), CDPR (China), PDPB (India), PIPA (Korea), APPI (Japan), PDP (Indonesia), PDPA (Singapore), APP (Australia), and other regulations protect sensitive data from being moved. In fact, those regulations sometimes even prevent single organizations from combining their own users' data for machine learning training because those users live in different parts of the world, and their data is governed by different data protection regulations.
用户偏好: 除了法规之外,在一些使用案例中,用户只是希望数据永远不会离开他们的设备。如果你在手机的数字键盘上输入密码和信用卡信息,你不会希望这些密码最终出现在开发该键盘的公司的服务器上吧?事实上,这种用例正是联邦学习发明的初衷。
数据量: 有些传感器(如摄像头)产生的数据量很大,收集所有数据既不可行,也不经济(例如,由于带宽或通信效率的原因)。试想一下全国铁路服务,全国有数百个火车站。如果每个火车站都安装了许多安全摄像头,那么它们所产生的大量原始设备数据就需要功能强大且极其昂贵的基础设施来处理和存储。而大部分数据甚至都是无用的。
集中式机器学习不起作用的例子包括:
Sensitive healthcare records from multiple hospitals to train cancer detection models.
Financial information from different organizations to detect financial fraud.
Location data from your electric car to make better range prediction.
End-to-end encrypted messages to train better auto-complete models.
像 `Brave <https://brave.com/>`__浏览器或 `Signal <https://signal.org/>`__信息管理器这样的隐私增强系统的流行表明,用户关心隐私。事实上,他们会选择隐私性更好的产品。但是,我们能做些什么来将机器学习和数据科学应用到这些情况中,以利用隐私数据呢?毕竟,这些领域都将从人工智能的最新进展中受益匪浅。
Federated Learning¶
Federated Learning simply reverses this approach. It enables machine learning on distributed data by moving the training to the data, instead of moving the data to the training. Here's a one-liner explanation:
Centralized machine learning: move the data to the computation
Federated (machine) Learning: move the computation to the data
By doing so, Federated Learning enables us to use machine learning (and other data science approaches) in areas where it wasn't possible before. We can now train excellent medical AI models by enabling different hospitals to work together. We can solve financial fraud by training AI models on the data of different financial institutions. We can build novel privacy-enhancing applications (such as secure messaging) that have better built-in AI than their non-privacy-enhancing alternatives. And those are just a few of the examples that come to mind. As we deploy Federated Learning, we discover more and more areas that can suddenly be reinvented because they now have access to vast amounts of previously inaccessible data.
So how does Federated Learning work, exactly? Let's start with an intuitive explanation.
联邦学习的五个步骤¶
步骤 0:初始化全局模型¶
我们首先在服务器上初始化模型。这与经典的集中式学习完全相同:我们随机或从先前保存的检查点初始化模型参数。
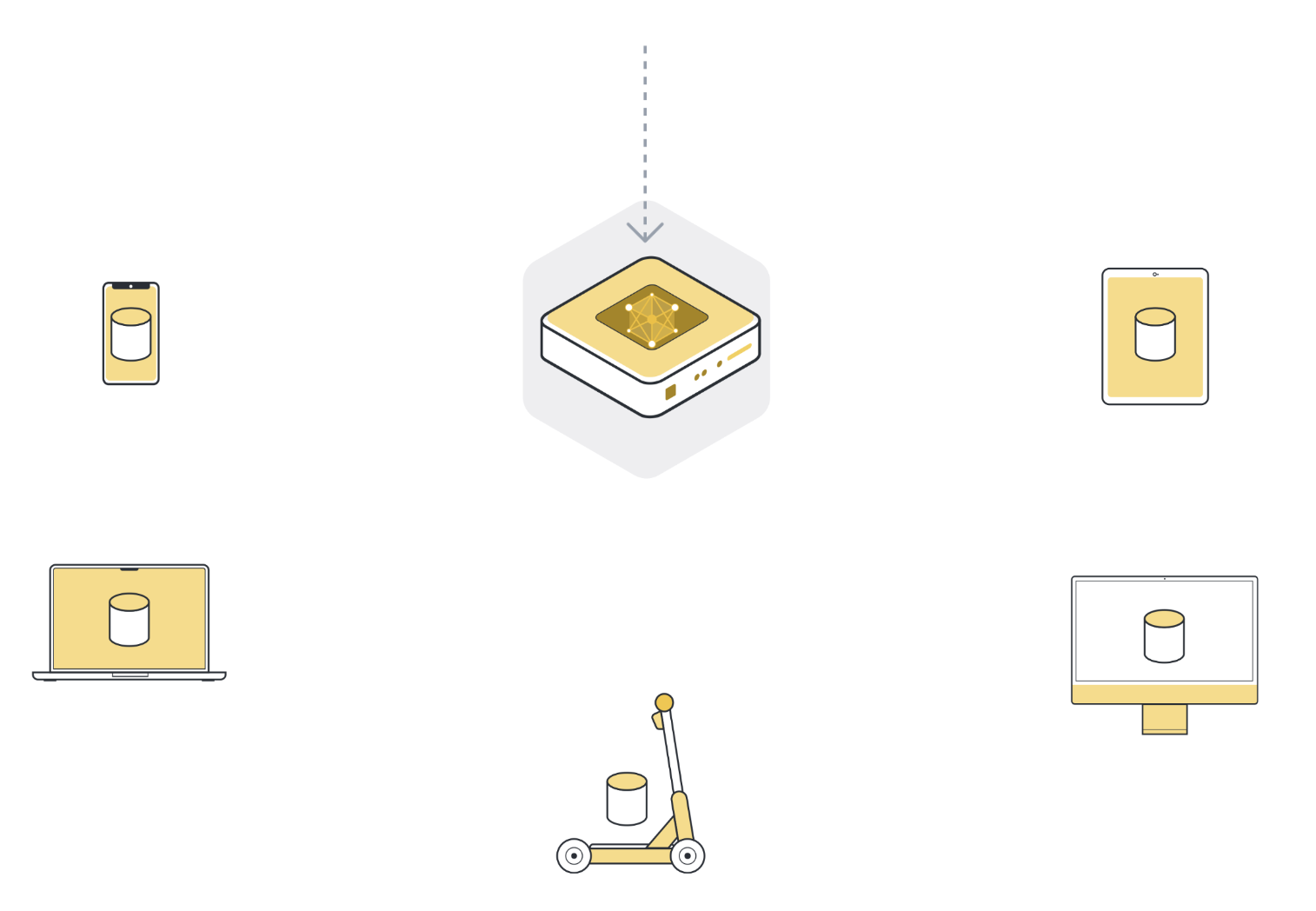
第 1 步:将模型发送到多个连接的组织/设备(客户节点)¶
Next, we send the parameters of the global model to the connected client nodes (think: edge devices like smartphones or servers belonging to organizations). This is to ensure that each participating node starts its local training using the same model parameters. We often use only a few of the connected nodes instead of all nodes. The reason for this is that selecting more and more client nodes has diminishing returns.
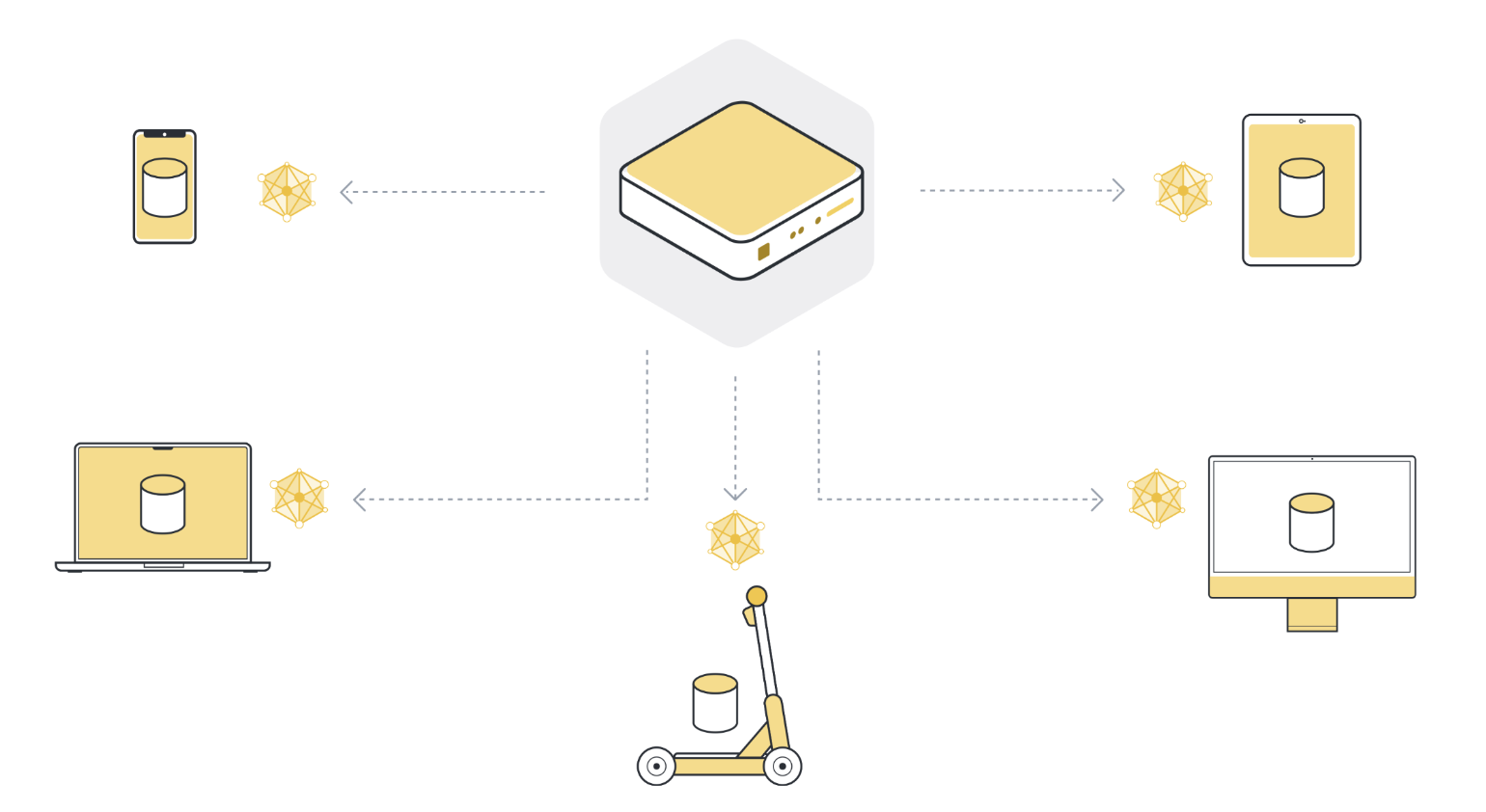
步骤 2:在本地对每个机构/设备(客户端节点)的数据进行模型训练¶
现在,所有(选定的)客户端节点都有了最新版本的全局模型参数,它们开始进行本地训练。它们使用自己的本地数据集来训练自己的本地模型。它们不会一直训练到模型完全收敛为止,而只是训练一小段时间。这可能只是本地数据上的一个遍历,甚至只是几个步骤(mini-batches)。
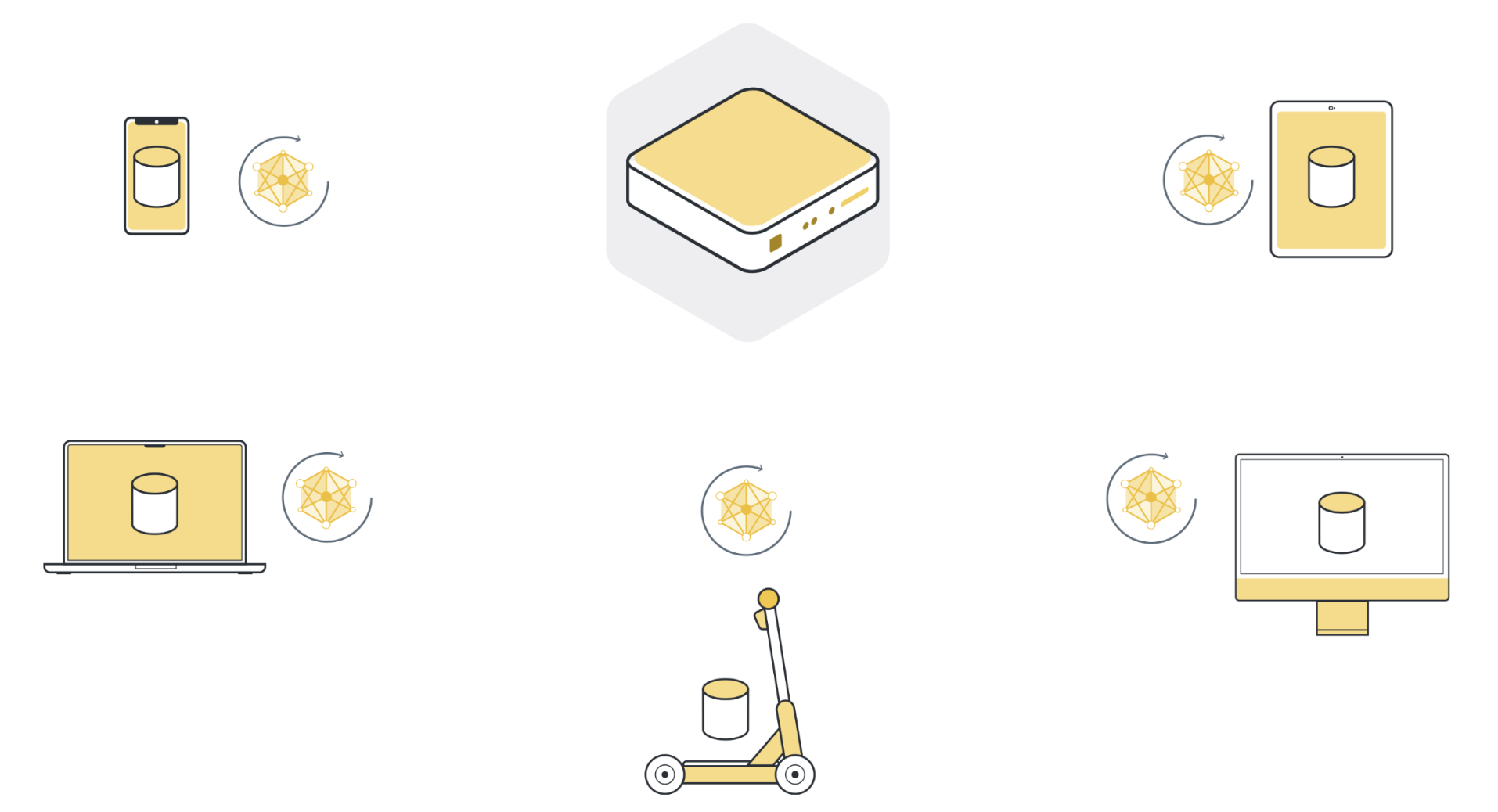
步骤 3:将模型参数更新返回服务器¶
经过本地训练后,每个客户节点最初收到的模型参数都会略有不同。参数之所以不同,是因为每个客户端节点的本地数据集中都有不同的数据。然后,客户端节点将这些模型更新发回服务器。它们发送的模型更新既可以是完整的模型参数,也可以只是本地训练过程中积累的梯度。
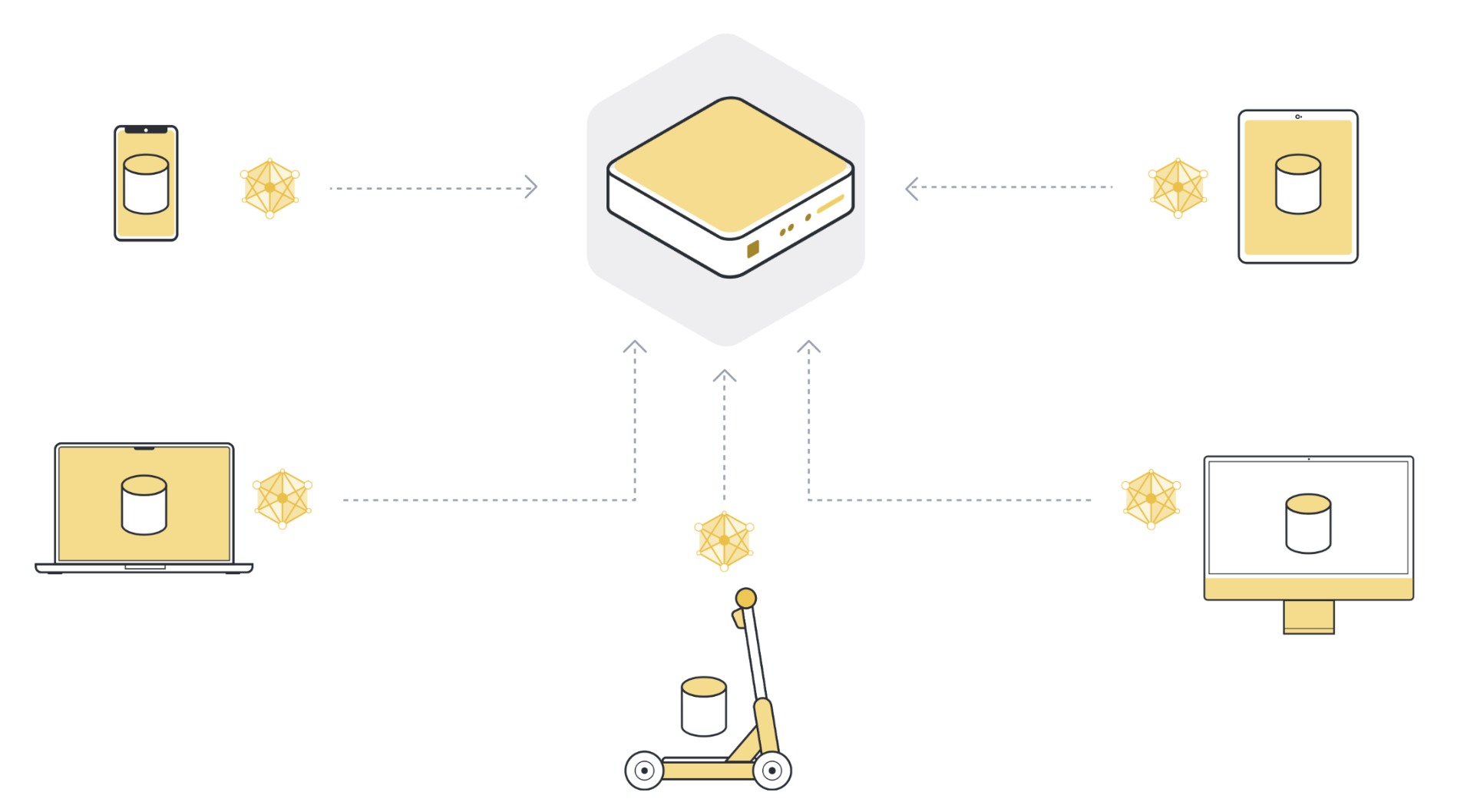
步骤 4:将模型更新聚合到新的全局模型中¶
服务器从选定的客户端节点接收模型更新。如果服务器选择了 100 个客户端节点,那么它现在就拥有 100 个略有不同的原始全局模型版本,每个版本都是根据一个客户端的本地数据训练出来的。难道我们不希望有一个包含所有 100 个客户节点数据的模型吗?
In order to get one single model, we have to combine all the model updates we received from the client nodes. This process is called aggregation, and there are many different ways to do it. The most basic way is called Federated Averaging (McMahan et al., 2016), often abbreviated as FedAvg. FedAvg takes the 100 model updates and, as the name suggests, averages them. To be more precise, it takes the weighted average of the model updates, weighted by the number of examples each client used for training. The weighting is important to make sure that each data example has the same “influence” on the resulting global model. If one client has 10 examples, and another client has 100 examples, then - without weighting - each of the 10 examples would influence the global model ten times as much as each of the 100 examples.
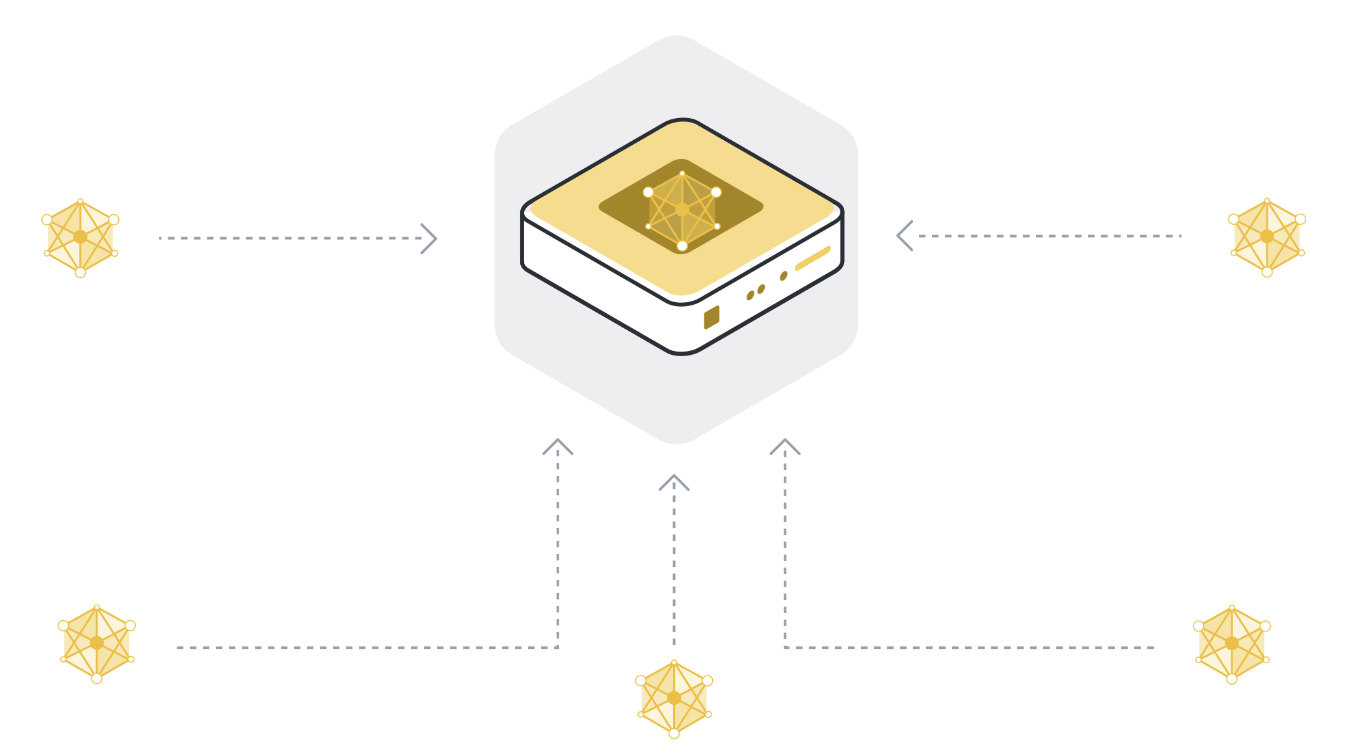
步骤 5:重复步骤 1 至 4,直至模型收敛¶
步骤 1 至 4 就是我们所说的单轮联邦学习。全局模型参数被发送到参与的客户端节点(第 1 步),客户端节点对其本地数据进行训练(第 2 步),然后将更新后的模型发送到服务器(第 3 步),服务器汇总模型更新,得到新版本的全局模型(第 4 步)。
在一轮迭代中,每个参与迭代的客户节点只训练一小段时间。这意味着,在聚合步骤(步骤 4)之后,我们的模型已经在所有参与的客户节点的所有数据上训练过了,但只训练了一小会儿。然后,我们必须一次又一次地重复这一训练过程,最终得到一个经过全面训练的模型,该模型在所有客户节点的数据中都表现良好。
总结¶
恭喜您,现在您已经了解了联邦学习的基础知识。当然,要讨论的内容还有很多,但这只是联邦学习的一个缩影。在本教程的后半部分,我们将进行更详细的介绍。有趣的问题包括 我们如何选择最好的客户端节点参与下一轮学习?聚合模型更新的最佳方法是什么?如何处理失败的客户端节点(落伍者)?
联邦评估¶
就像我们可以在不同客户节点的分散数据上训练一个模型一样,我们也可以在这些数据上对模型进行评估,以获得有价值的指标。这就是所谓的联邦评估,有时简称为 FE。事实上,联邦评估是大多数联邦学习系统不可或缺的一部分。
Federated Analytics¶
在很多情况下,机器学习并不是从数据中获取价值的必要条件。数据分析可以产生有价值的见解,但同样,往往没有足够的数据来获得明确的答案。人们患某种健康疾病的平均年龄是多少?联邦分析可以通过多个客户端节点进行此类查询。它通常与安全聚合等其他隐私增强技术结合使用,以防止服务器看到单个客户端节点提交的结果。
差分隐私¶
Differential privacy (DP) is often mentioned in the context of Federated Learning. It is a privacy-preserving method used when analyzing and sharing statistical data, ensuring the privacy of individual participants. DP achieves this by adding statistical noise to the model updates, ensuring any individual participants' information cannot be distinguished or re-identified. This technique can be considered an optimization that provides a quantifiable privacy protection measure.
Flower¶
联邦学习、联邦评估和联邦分析需要基础框架来来回移动机器学习模型,在本地数据上对其进行训练和评估,然后汇总更新的模型。Flower 提供的基础架构正是以简单、可扩展和安全的方式实现这些目标的。简而言之,Flower 为联邦学习、分析和评估提供了一种统一的方法。它允许用户联邦化任何工作负载、任何 ML 框架和任何编程语言。
Final Remarks¶
Congratulations, you just learned the basics of federated learning and how it relates to classic centralized machine learning.
In the next tutorial, you will take the first practical step with Flower: create a simulated federation on SuperGrid, run an existing Flower App from Flower Hub, and use the SuperGrid dashboard to follow the run and inspect its logs.
接下来的步骤¶
Before you continue, make sure to join the Flower community on Flower Discuss (Join Flower Discuss) and on Slack (Join Slack).
There's a dedicated #questions Slack channel if you need help, but we'd also love to
hear who you are in #introductions!
The Flower Collaborative AI Tutorial - Part 1: Get started with Flower shows how to create your first federation on SuperGrid and run a Flower App without writing code.