Vertical Federated Learning with Flower¶

This example will showcase how you can perform Vertical Federated Learning using Flower. We’ll be using the Titanic dataset to train simple regression models for binary classification. We will go into more details below, but the main idea of Vertical Federated Learning is that each client is holding different feature sets of the same dataset and that the server is holding the labels of this dataset.
Horizontal Federated Learning (HFL or just FL) |
Vertical Federated Learning (VFL) |
|
|---|---|---|
Data Distribution |
Clients have different data instances but share the same feature space. Think of different hospitals having different patients’ data (samples) but recording the same types of information (features). |
Each client holds different features for the same instances. Imagine different institutions holding various tests or measurements for the same group of patients. |
Model Training |
Each client trains a model on their local data, which contains all the feature columns for its samples. |
Clients train models on their respective features without having access to the complete feature set. Each model only sees a vertical slice of the data (hence the name ‘Vertical’). |
Aggregation |
The server aggregates these local models by averaging the parameters or gradients to update a global model. |
The server aggregates the updates such as gradients or parameters, which are then used to update the global model. However, since each client sees only a part of the features, the server typically has a more complex role, sometimes needing to coordinate more sophisticated aggregation strategies that may involve secure multi-party computation techniques. |
Privacy Consideration |
The raw data stays on the client’s side, only model updates are shared, which helps in maintaining privacy. |
VFL is designed to ensure that no participant can access the complete feature set of any sample, thereby preserving the privacy of data. |
HFL |
VFL |
|---|---|
|
|
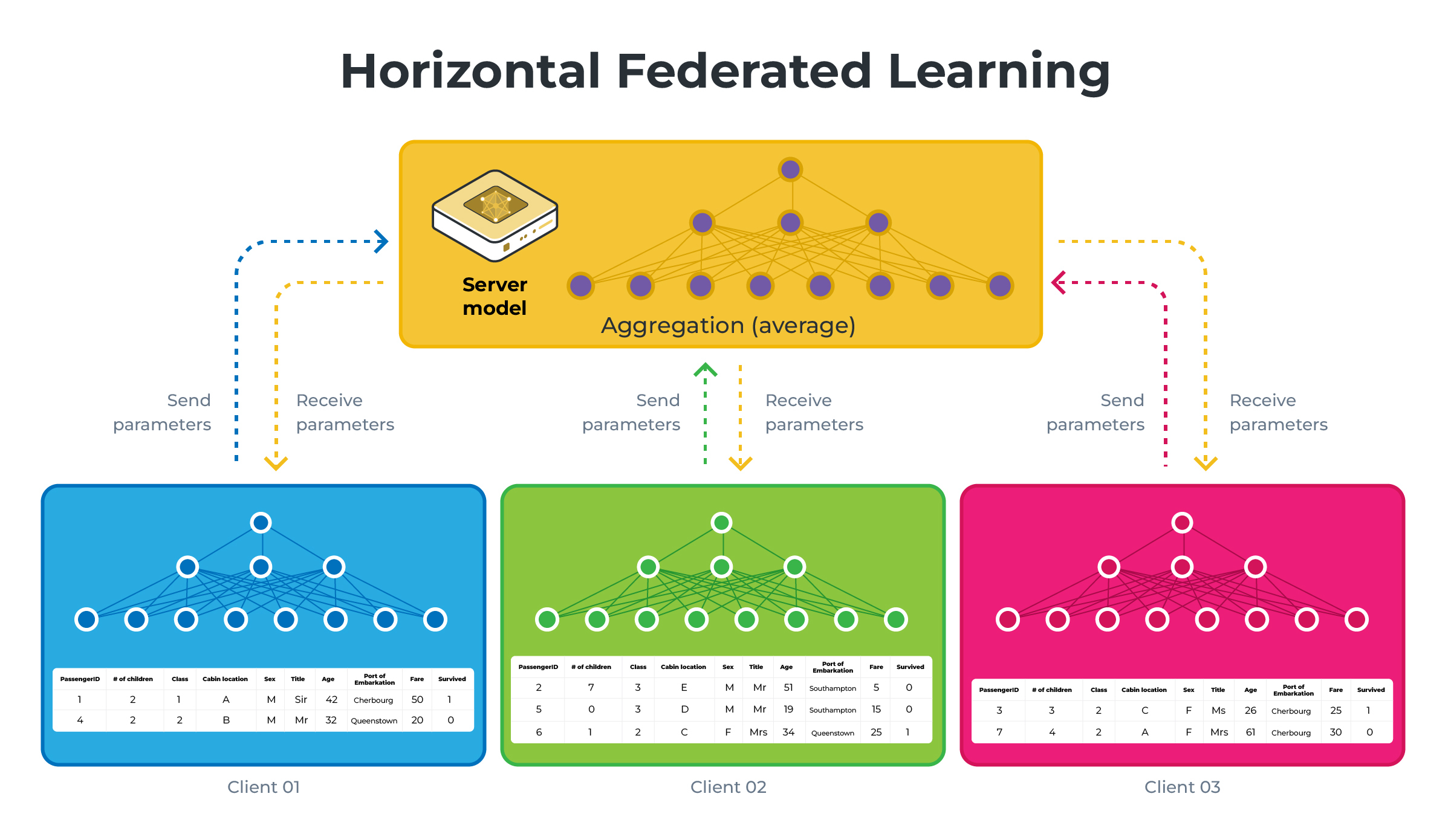
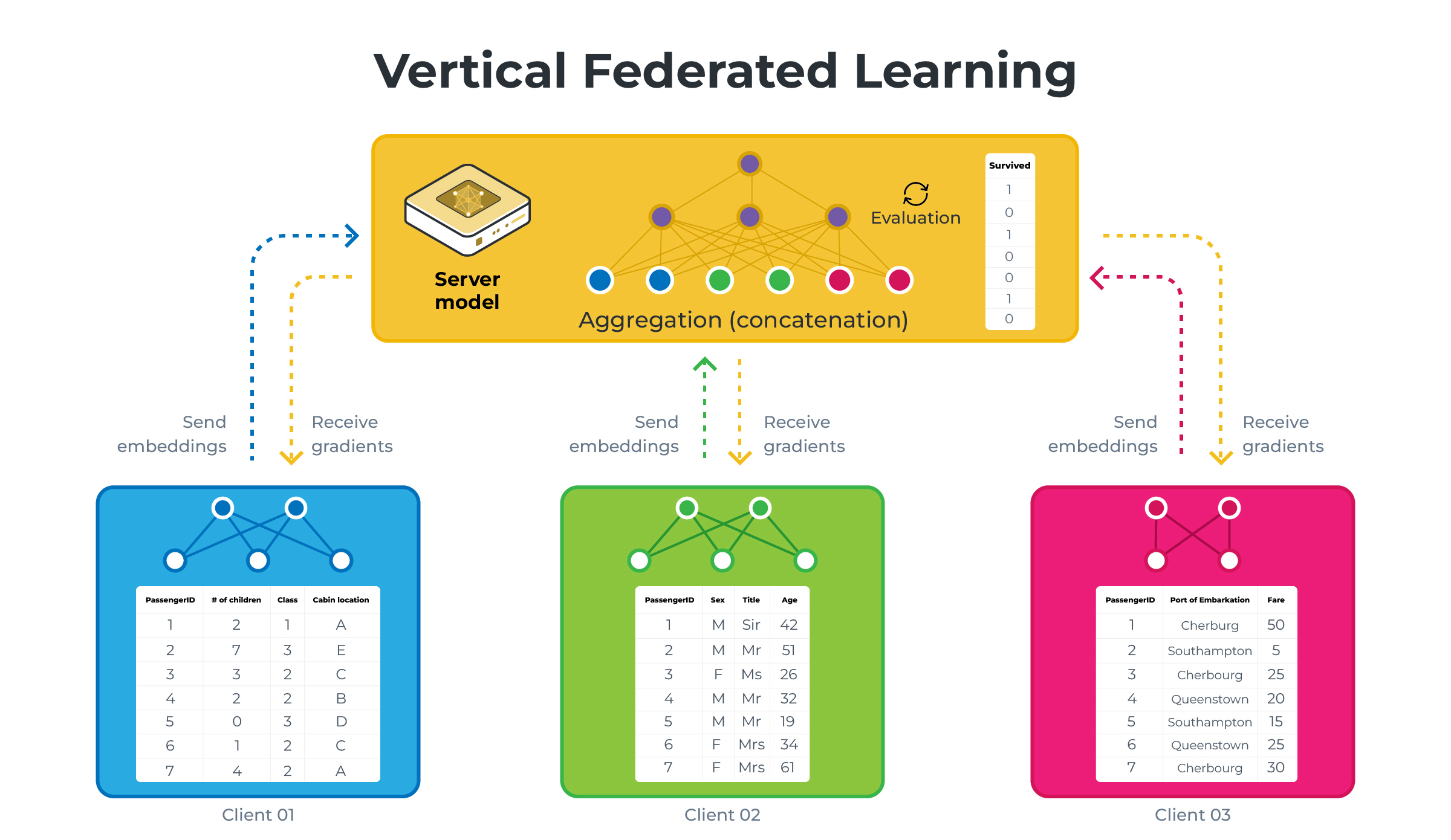
Those diagrams illustrate HFL vs VFL using a simplified version of what we will be building in this example. Note that on the VFL side, the server holds the labels (the Survived column) and will be the only one capable of performing evaluation.
Set up the project¶
Clone the project¶
Start by cloning the example project:
git clone --depth=1 https://github.com/flwrlabs/flower.git _tmp \
&& mv _tmp/examples/vertical-fl . \
&& rm -rf _tmp \
&& cd vertical-fl
This will create a new directory called vertical-fl with the following structure:
vertical-fl
├── vertical_fl
│ ├── __init__.py
│ ├── client_app.py # Defines your ClientApp
│ ├── server_app.py # Defines your ServerApp
│ └── task.py # Defines your model, training and data loading
├── pyproject.toml # Project metadata like dependencies and configs
└── README.md
Install dependencies and project¶
Install the dependencies defined in pyproject.toml as well as the vertical_fl package.
pip install -e .
Vertical data partitioning¶
In this example we use the VerticalSizePartitioner from Flower Datasets to vertically split the dataset into 3 partitions (one for each client) with the target column (i.e. whether the passenger survived the Titanic sinking) being available at the ServerApp only.
from flwr_datasets import FederatedDataset
from flwr_datasets.partitioner import VerticalSizePartitioner
partitioner = VerticalSizePartitioner(
partition_sizes=[2, 3, 2], # three partitions with 2,3 and 2 features
active_party_columns="Survived", # the target
active_party_columns_mode="create_as_last" # An additional partition will be created
) # that only contains the target column
fds = FederatedDataset(
dataset="julien-c/titanic-survival",
partitioners={"train": partitioner}
)
# Load all partitions
partitions = [fds.load_partition(i) for i in range(fds.partitioners["train"].num_partitions)]
for partition in partitions:
print(partition.column_names)
# ['Age', 'Sex'] <----------------------------------- ClientApp #0
# ['Fare', 'Siblings/Spouses Aboard', 'Name'] <------ ClientApp #1
# ['Parents/Children Aboard', 'Pclass'] <------------ ClientApp #2
# ['Survived'] <--------------------------------------ServerApp
You can control the number of partitions as well as how many features each have by modifying feature-splits (defaults to [2,3,2]) in the [tool.flwr.app.config] section of the pyproject.toml.
Run the project¶
You can run your Flower project in both simulation and deployment mode without making changes to the code. If you are starting with Flower, we recommend you using the simulation mode as it requires fewer components to be launched manually. By default, flwr run will make use of the Simulation Engine.
This example is designed to run with three virtual SuperNodes. First we need to change the configuration of the Simulation Runtime (which by default uses 10 nodes). This guide assumes your default SuperLink connection points to one ready for simulations. If you aren’t sure, please refer to the How-to run Flower locally guide.
flwr federation simulation-config --num-supernodes=3
Remember, if you wish to change --num-supernodes you’ll need to adjust feature-splits in the pyproject.toml accordingly.
Run with the Simulation Engine¶
[!NOTE] Check the Simulation Engine documentation to learn more about Flower simulations and how to optimize them.
By default, the example runs for 250 rounds using three clients. Launch it with default settings with:
flwr run .
The expected last lines of the log should look like:
...
INFO : --- ServerApp Round 250 / 250 ---
INFO : Requesting embeddings from 3 nodes...
INFO : Received 3/3 results
INFO : Round 250, Loss: 0.3096, Accuracy: 84.94%
INFO : Sending gradients to 3 nodes...
INFO :
INFO : === Final Results ===
INFO : Round 25 -> Loss: 0.6458 | Accuracy: 61.89%
INFO : Round 50 -> Loss: 0.5888 | Accuracy: 67.76%
INFO : Round 75 -> Loss: 0.5265 | Accuracy: 72.49%
INFO : Round 100 -> Loss: 0.4939 | Accuracy: 74.41%
INFO : Round 125 -> Loss: 0.4499 | Accuracy: 78.13%
INFO : Round 150 -> Loss: 0.4012 | Accuracy: 81.51%
INFO : Round 175 -> Loss: 0.3691 | Accuracy: 82.07%
INFO : Round 200 -> Loss: 0.3710 | Accuracy: 82.75%
INFO : Round 225 -> Loss: 0.3172 | Accuracy: 84.44%
INFO : Round 250 -> Loss: 0.3096 | Accuracy: 84.94%
You can also override some of the settings for your ClientApp and ServerApp defined in pyproject.toml. For example:
flwr run . --run-config "num-server-rounds=500 learning-rate=0.05"
Run with the Deployment Engine¶
Follow this how-to guide to run the same app in this example but with Flower’s Deployment Engine. After that, you might be intersted in setting up secure TLS-enabled communications and SuperNode authentication in your federation. If you are already familiar with how the Deployment Engine works, you may want to learn how to run it using Docker. Check out the Flower with Docker documentation.