Flower的架构¶
This page explains the architecture of deployed Flower federated learning system.
In federated learning (FL), there is typically one server and a number of clients that are connected to the server. This is often called a federation.
The role of the server is to coordinate the training process. The role of each client is to receive tasks from the server, execute those tasks and return the results back to the server.
This is sometimes called a hub-and-spoke topology:
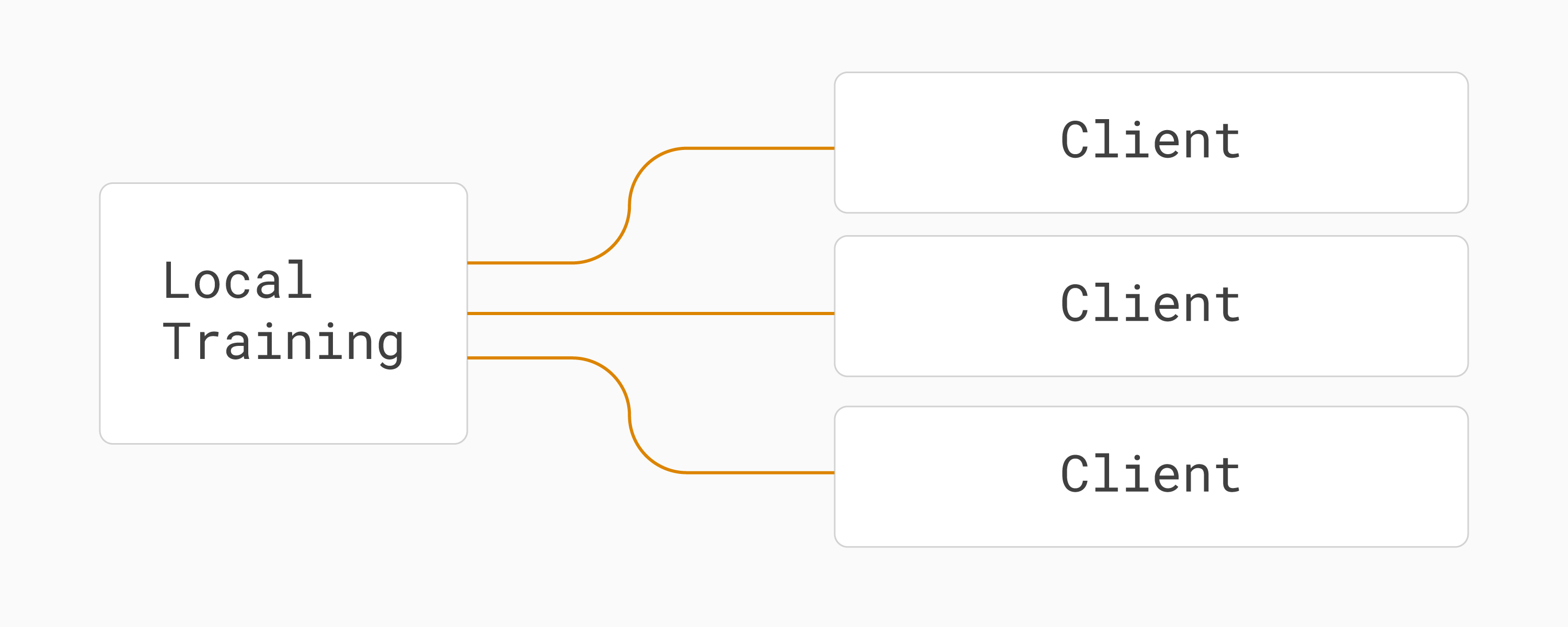
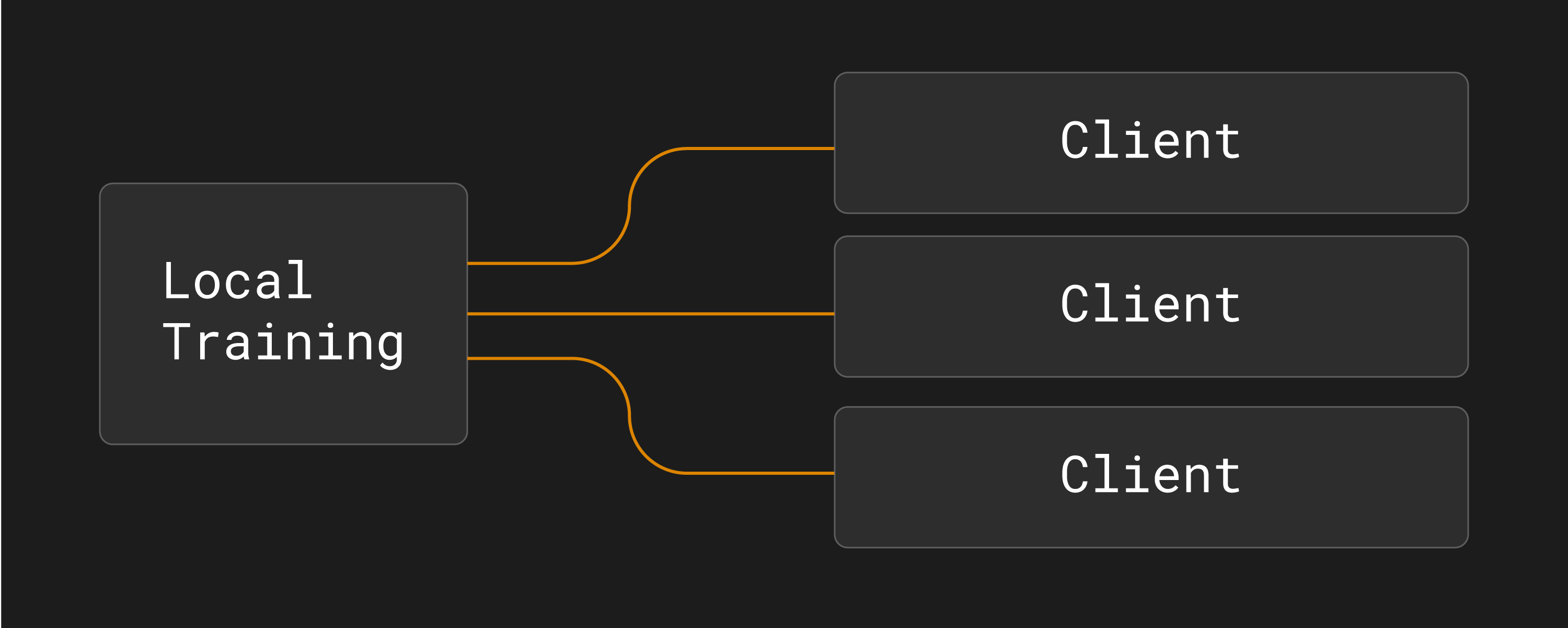
Hub-and-spoke topology in federated learning (one server, multiple clients).¶
In a real-world deployment, we typically want to run different projects on such a federation. Each project could use different hyperparameters, different model architectures, different aggregation strategies, or even different machine learning frameworks like PyTorch and TensorFlow.
This is why, in Flower, both the server side and the client side are split into two parts. One part is long-lived and responsible for communicating across the network, the other part is short-lived and executes task-specific code.
A Flower server is composed of SuperLink, SuperExec, and ServerApp:
SuperLink: A long-running process that forwards task instructions to clients (SuperNodes) and receives task results back.
SuperExec: A long-running process that schedules, launches, and manages multiple app processes (e.g.,
ServerApp) on demand by communicating with the SuperLink. By default, it is started automatically by the SuperLink.ServerApp: A short-lived app process containing project-specific code that customizes all server-side aspects of federated learning systems (client selection, client configuration, result aggregation). This is the component AI researchers and engineers implement when building Flower apps.
A Flower client is composed of SuperNode, SuperExec, and ClientApp:
SuperNode: A long-running process that connects to the SuperLink, requests tasks, executes them (for example, "train this model on your local data"), and returns the results to the SuperLink.
SuperExec: A long-running process that schedules, launches, and manages multiple application processes (e.g.,
ClientApp) on demand by communicating with the SuperNode. By default, it is started automatically by the SuperNode.ClientApp: A short-lived app process containing project-specific code that customizes all client-side aspects of federated learning systems (local model training, evaluation, pre- and post-processing). This is the component AI researchers and engineers implement when building Flower apps.
Why SuperNode and SuperLink? Well, in federated learning, the clients are the actual stars of the show. They hold the training data and they run the actual training. This is why Flower decided to name them SuperNode. The SuperLink is then responsible for acting as the missing link among all those SuperNodes.
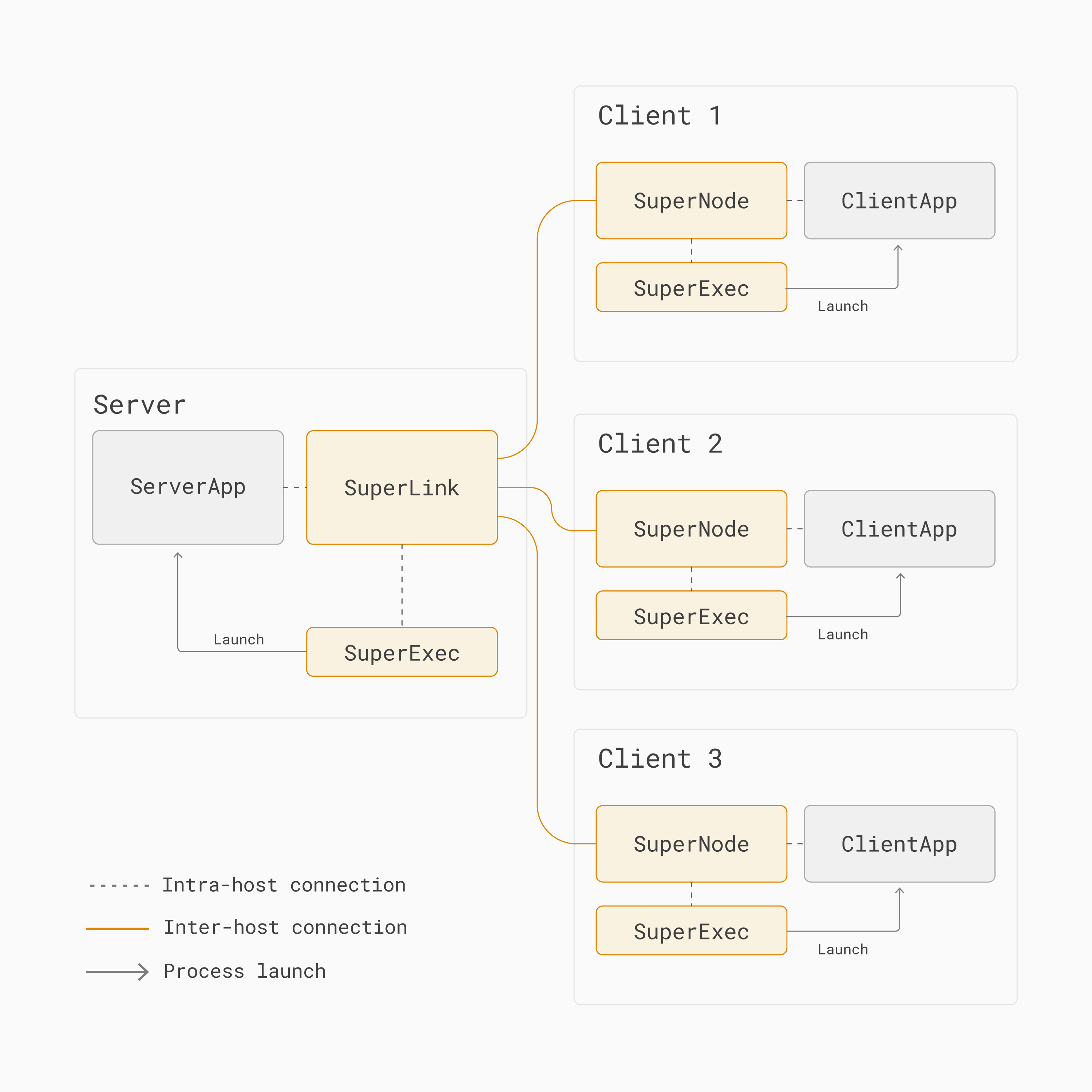
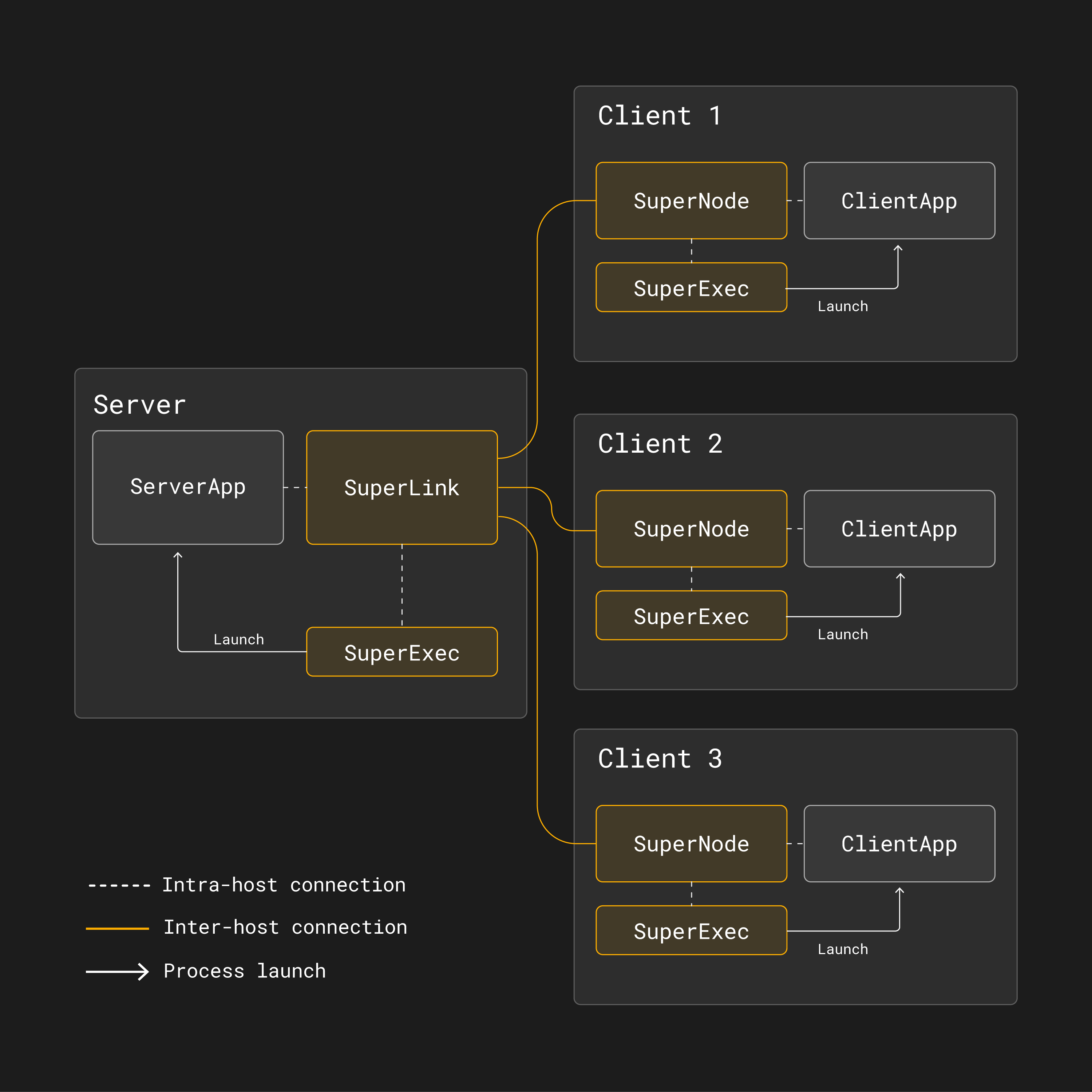
The basic Flower architecture for federated learning.¶
In a Flower app project, users will typically develop the ServerApp and the
ClientApp. All the network communication between server and clients is taken
care of by the SuperLink and SuperNodes.
With multi-run, multiple ServerApps and ClientApps can run within the same
federation, which consists of a single long-running SuperLink and multiple long-running
SuperNodes. This capability is sometimes referred to as multi-tenancy or multi-job.
As shown in the figure below, two Flower App projects, each consisting of a
ServerApp and a ClientApp, could share the same SuperLink and SuperNodes.
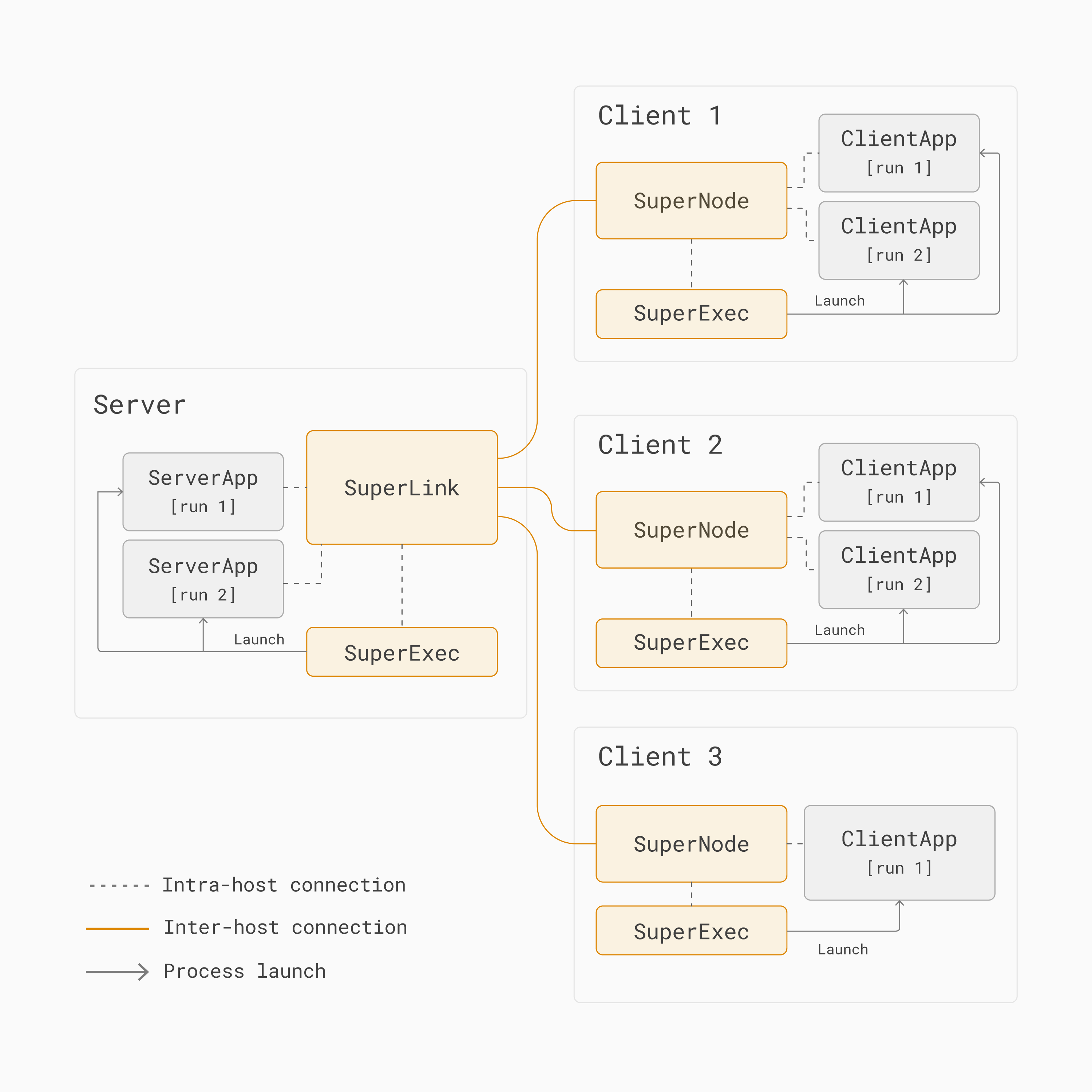
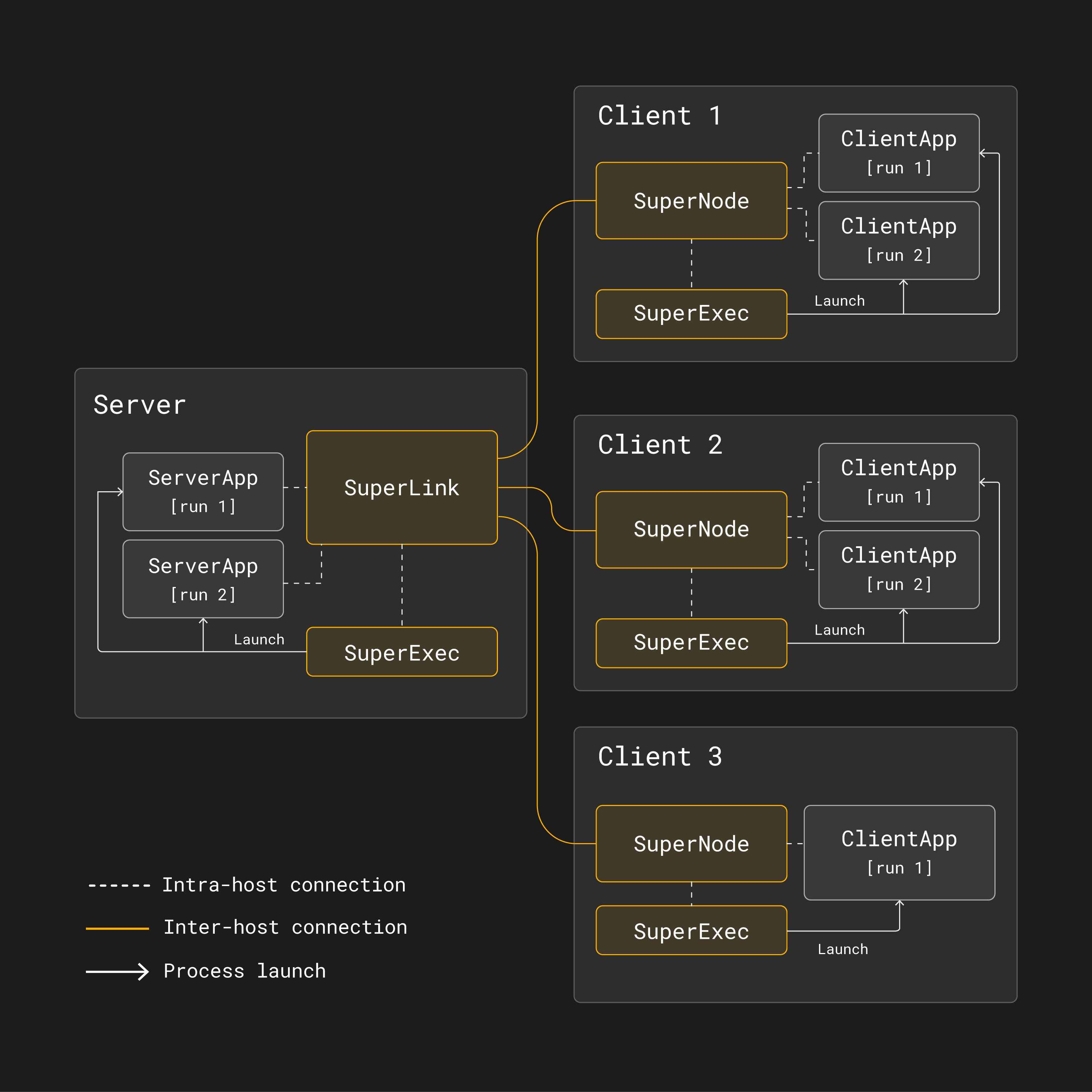
Multi-run federated learning architecture with Flower¶
To illustrate how multi-run works, consider one federated learning training run where a
ServerApp and a ClientApp are participating in [run 1]. Note that a
SuperNode will only run a ClientApp if it is selected to participate in the training
run.
In [run 1] below, all the SuperNodes are selected and therefore run their
corresponding ClientApps:
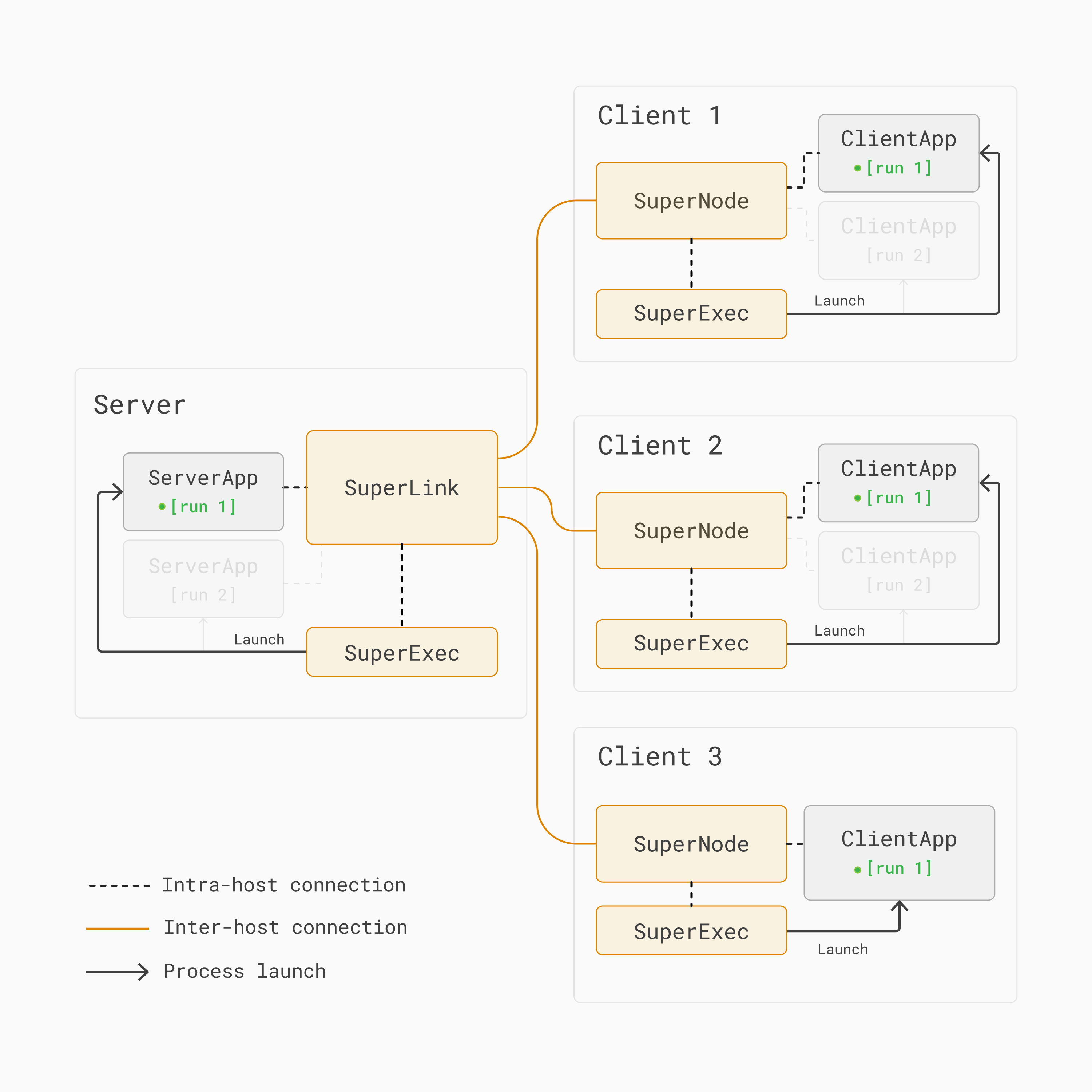
Run 1 in a multi-run federated learning architecture with Flower. All SuperNodes participate in the training round.¶
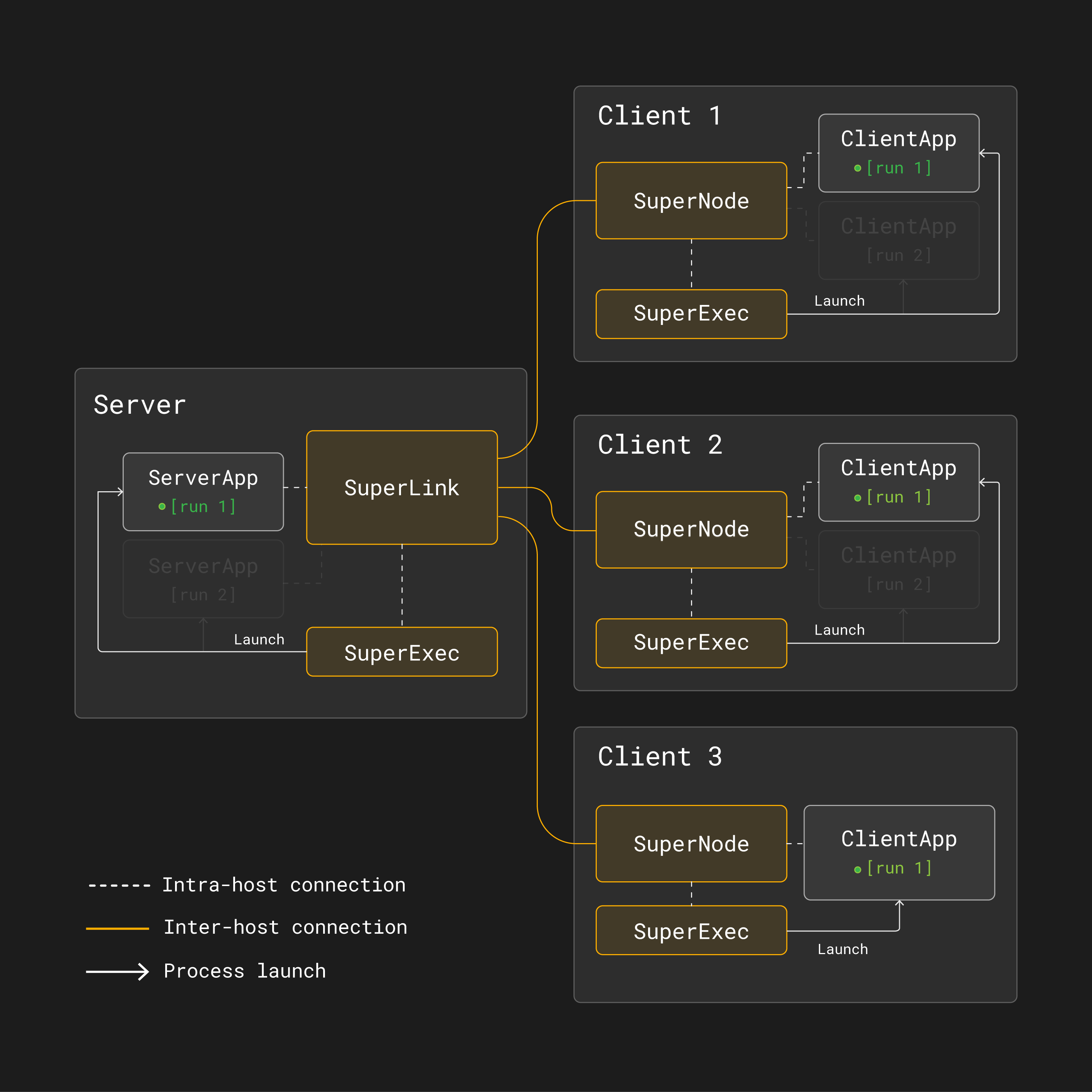
However, in [run 2], only the first and second SuperNodes are selected to
participate in the training:
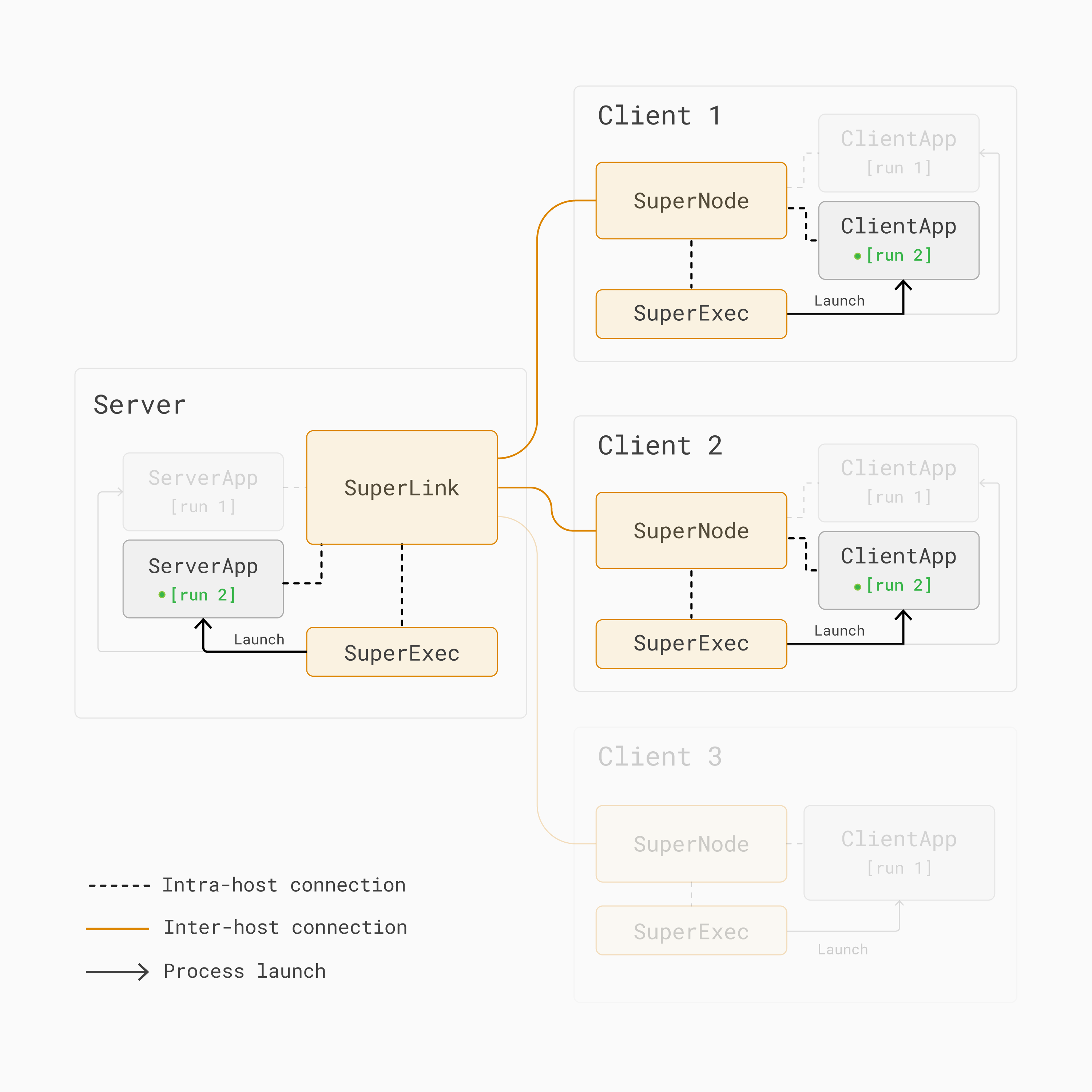
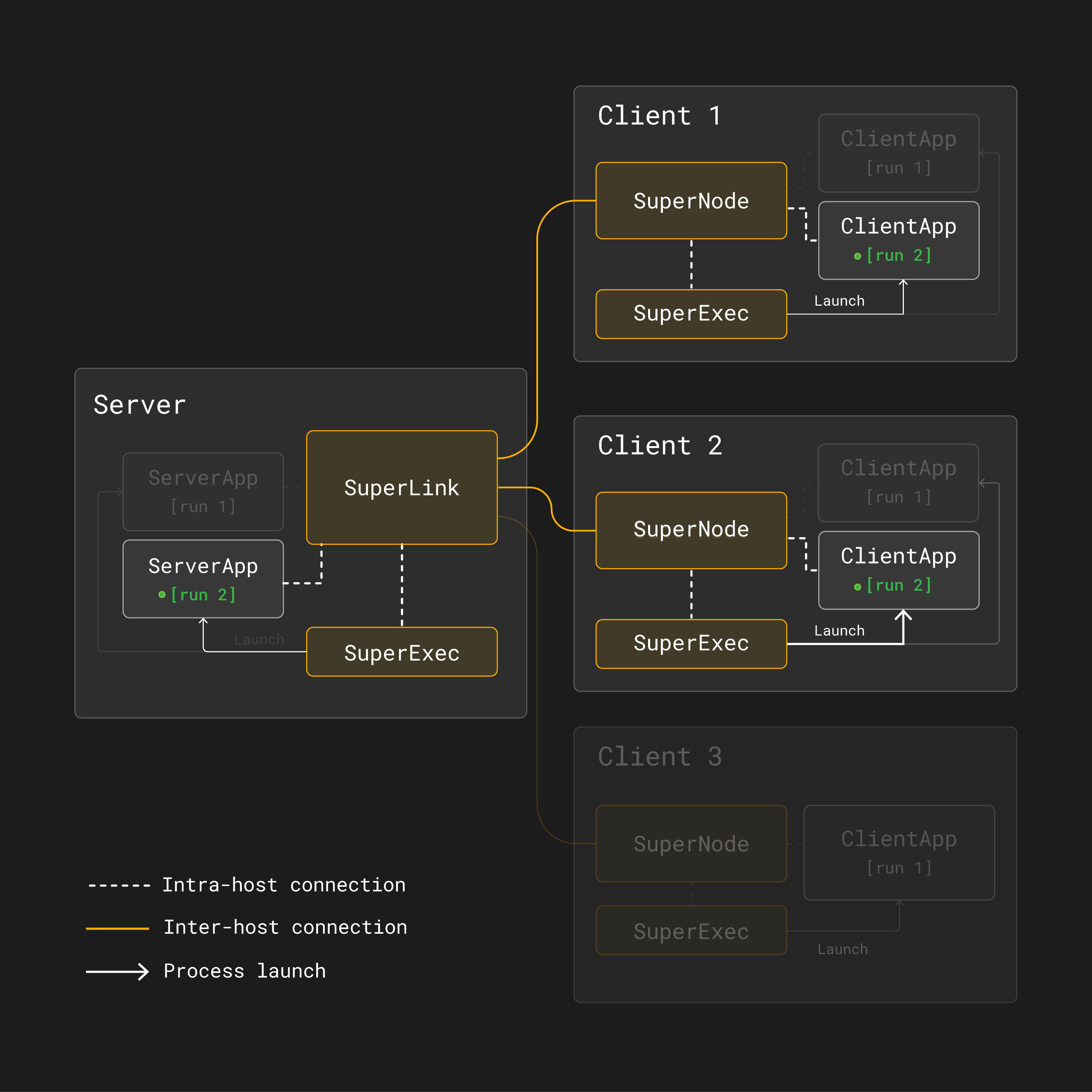
Run 2 in a multi-run federated learning architecture with Flower. Only the first and second SuperNodes are selected to participate in the training round.¶
Therefore, with Flower multi-run, different Flower App projects can run on different sets of clients.
Note
This explanation covers the Flower Deployment Runtime. An explanation covering the Flower Simulation Runtime will follow.
Important
As we continue to enhance Flower at a rapid pace, we'll periodically update this explainer document. Feel free to share any feedback with us.