Flower Architecture (architecture de Flower)¶
Cette page explique l’architecture d’un système de apprentissage fédéré Flower déployé.
Dans l’apprentissage fédéré (FL), il existe généralement un serveur et un certain nombre de clients connectés au serveur. C’est souvent appelé une fédération.
Le rôle du serveur est de coordonner le processus d’entraînement. Le rôle de chaque client est de recevoir des tâches du serveur, les exécuter et renvoyer les résultats au serveur.
C’est parfois appelé une topologie hub-and-spoke :
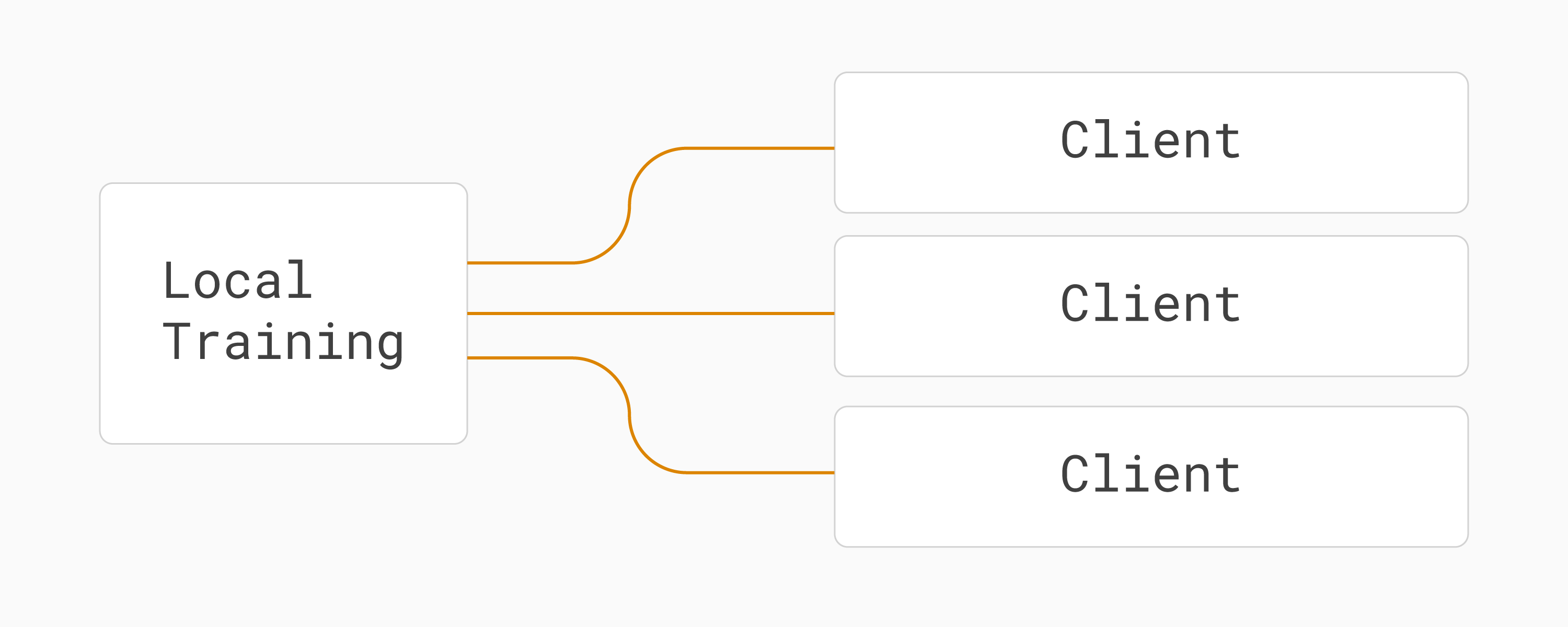
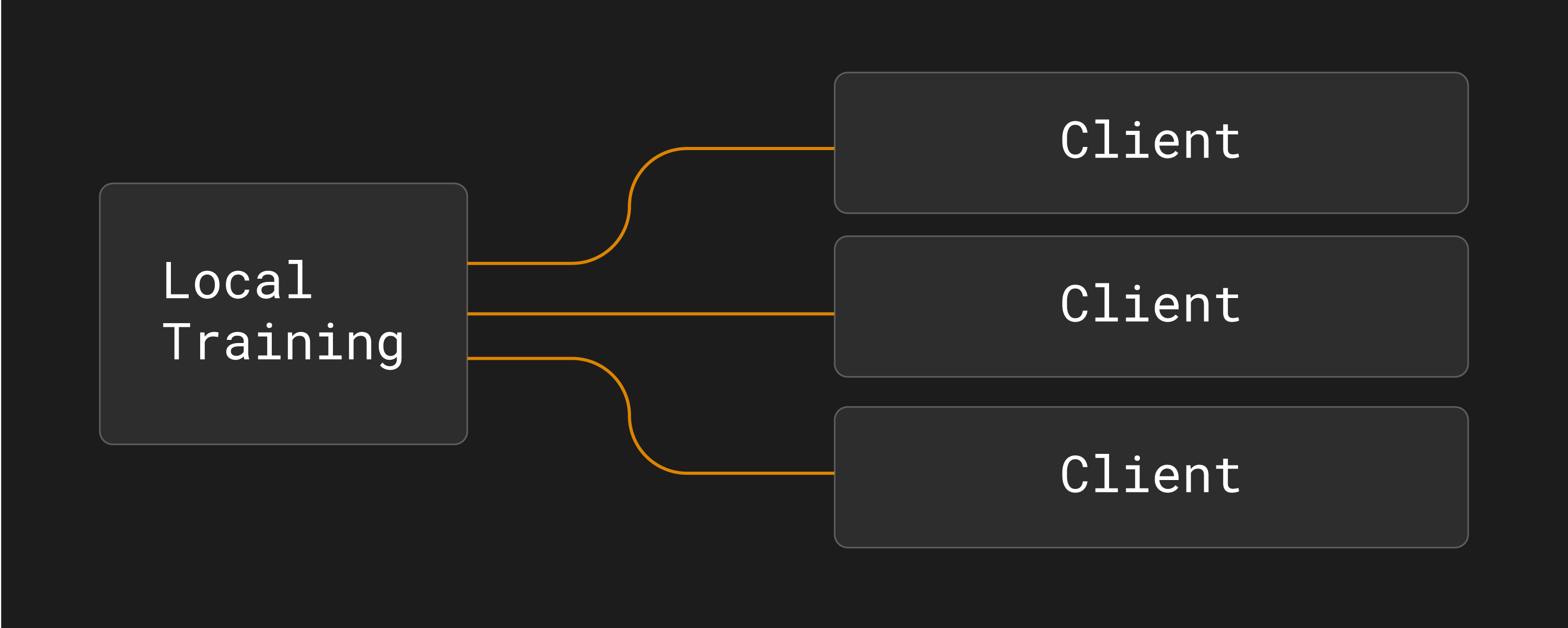
Topologie hub-and-spoke dans l’apprentissage fédéré (un serveur, plusieurs clients).¶
Dans un déploiement réel, nous voulons généralement exécuter différents projets sur une telle fédération. Chaque projet pourrait utiliser des hyperparamètres différents, des architectures de modèle différentes, des stratégies d’agrégation différentes ou même des frameworks de machine learning comme PyTorch et TensorFlow.
C’est pourquoi, dans Flower, les deux côtés (serveur et client) sont divisés en deux parties. Une partie est de longue durée et responsable de la communication réseau, l’autre partie est courte et exécute du code spécifique à la tâche.
Un serveur Flower est composé de SuperLink, SuperExec et ``ServerApp`` :
SuperLink : Un processus de longue durée qui transmet des instructions de tâches aux clients (SuperNodes) et reçoit les résultats de tâches.
SuperExec: Un processus longue durée qui planifie, lance et gère plusieurs processus d’application (par exemple,
ServerApp) à la demande en communiquant avec le SuperLink. Par défaut, il est démarré automatiquement par le SuperLink.ServerApp: Un processus d’application court durée contenant du code spécifique au projet qui personnalise tous les aspects serveur de systèmes d’apprentissage fédéré (sélection des clients, configuration des clients, agrégation des résultats). C’est le composant que les chercheurs et ingénieurs en intelligence artificielle mettent en œuvre lorsqu’ils construisent des applications Flower.
Un client Flower est composé de SuperNode, SuperExec et ``ClientApp`` :
SuperNode : Un processus de longue durée qui se connecte au SuperLink, demande des tâches, les exécute (par exemple, « entraînez ce modèle sur vos données locales »), et renvoie les résultats au SuperLink.
SuperExec: Un processus longue durée qui planifie, lance et gère plusieurs processus d’application (par exemple,
ClientApp) à la demande en communiquant avec le SuperNode. Par défaut, il est démarré automatiquement par le SuperNode.ClientApp: Un processus d’application court durée contenant du code spécifique au projet qui personnalise tous les aspects côté client de systèmes d’apprentissage fédéré (formation locale du modèle, évaluation, pré- et post-traitement). C’est le composant que les chercheurs et ingénieurs en intelligence artificielle mettent en œuvre lorsqu’ils construisent des applications Flower.
Pourquoi SuperNode et SuperLink ? Eh bien, dans l’apprentissage fédéré, les clients sont les vrais vedettes du spectacle. Ils possèdent les données d’entraînement et ils exécutent le véritable entraînement. C’est pourquoi Flower a décidé de leur donner le nom de SuperNode. Le SuperLink est alors responsable de jouer le rôle de la liaison manquante parmi tous ces SuperNodes.
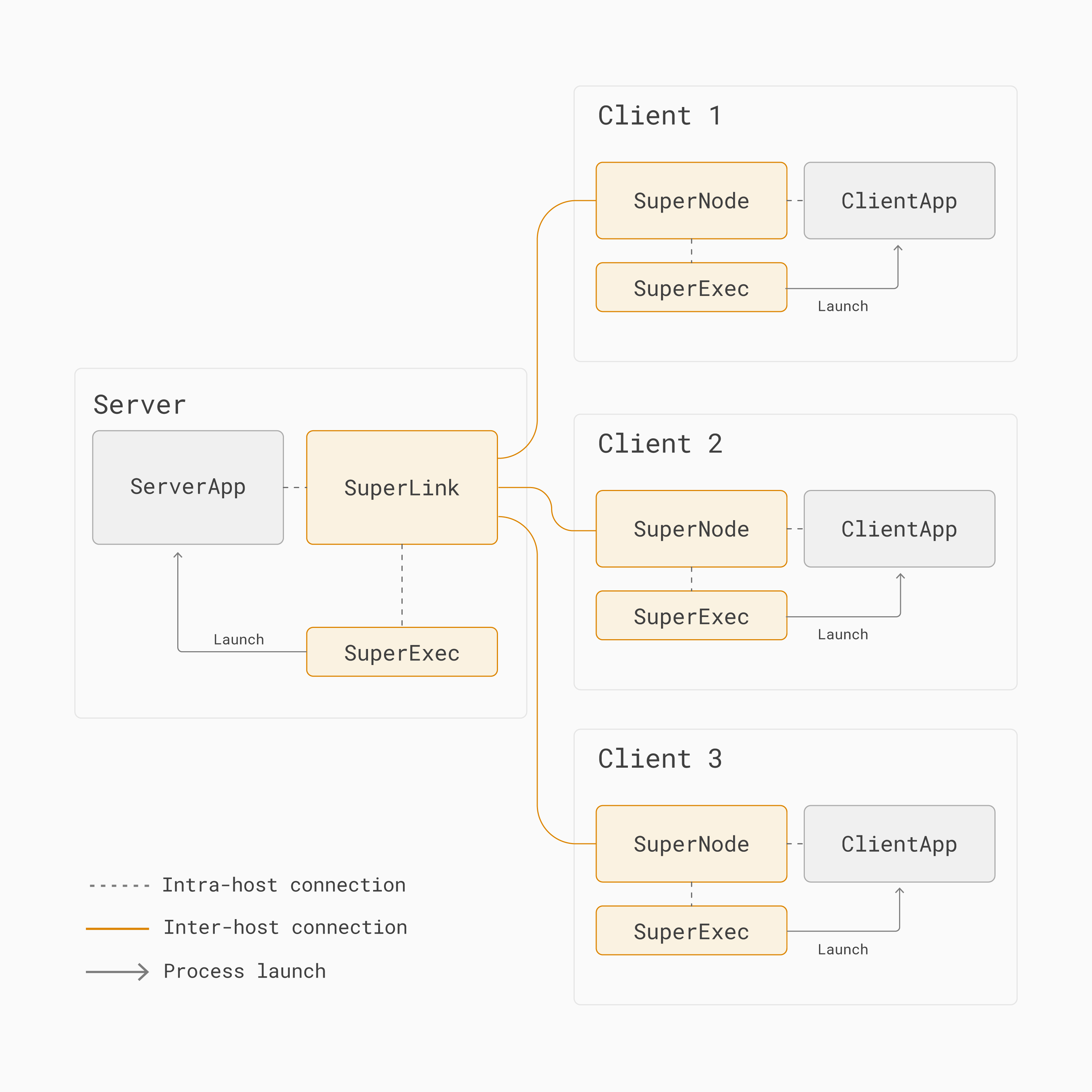
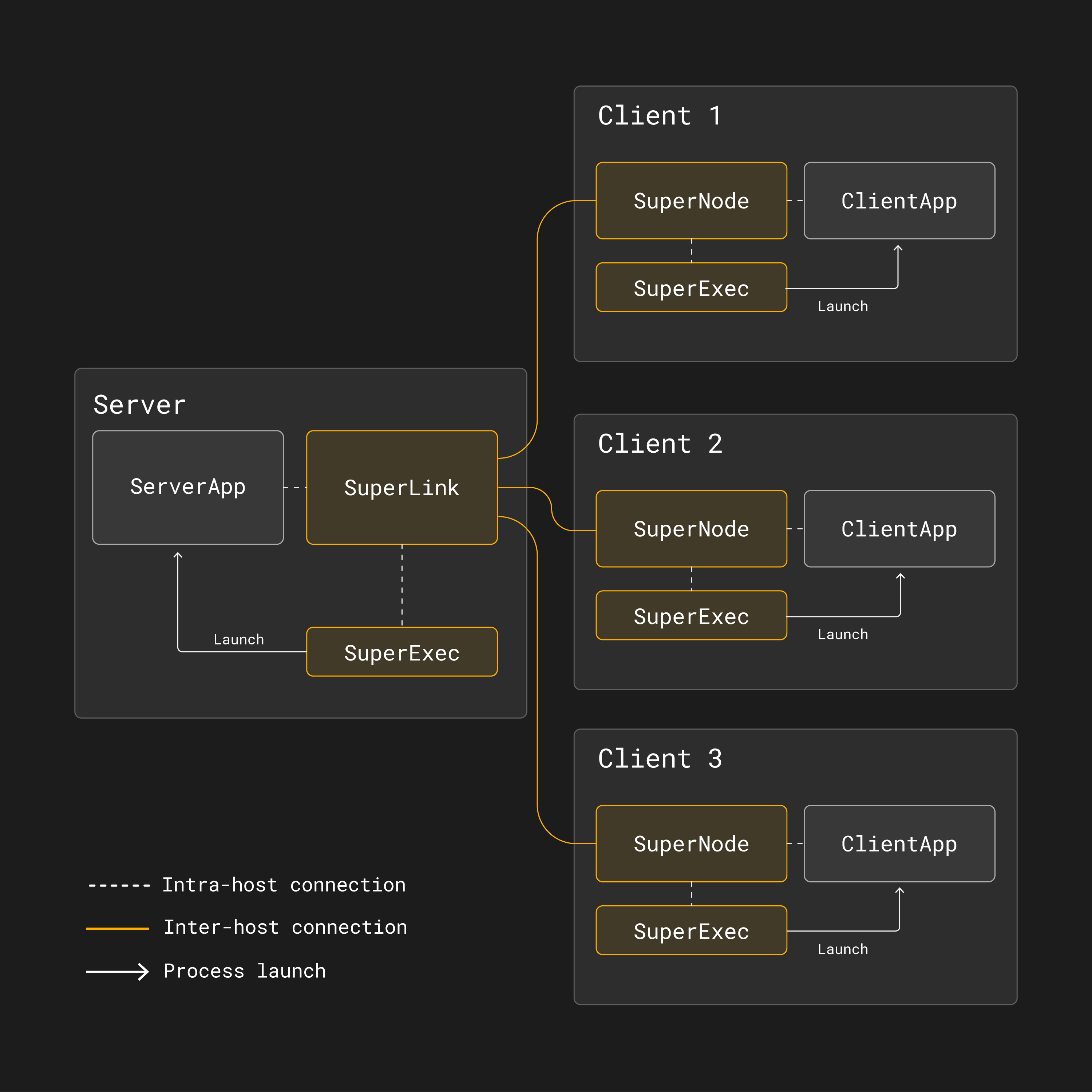
L’architecture de base pour l’apprentissage fédéré dans Flower.¶
Dans un projet d’application Flower, les utilisateurs développeront généralement le ServerApp et le ClientApp. Toutes les communications réseau entre serveur et clients sont prises en charge par le SuperLink et les SuperNodes.
Avec multi-run, plusieurs ServerApps et ClientApps peuvent s’exécuter au sein de la même fédération, qui consiste en un seul long-running SuperLink et plusieurs long-running SuperNodes. Cette capacité est parfois appelée multi-tenancy ou multi-job.
Comme le montre la figure ci-dessous, deux projets d’application Flower, chacun composé d’un ServerApp et d’un ClientApp, pourraient partager les mêmes SuperLink et SuperNodes.
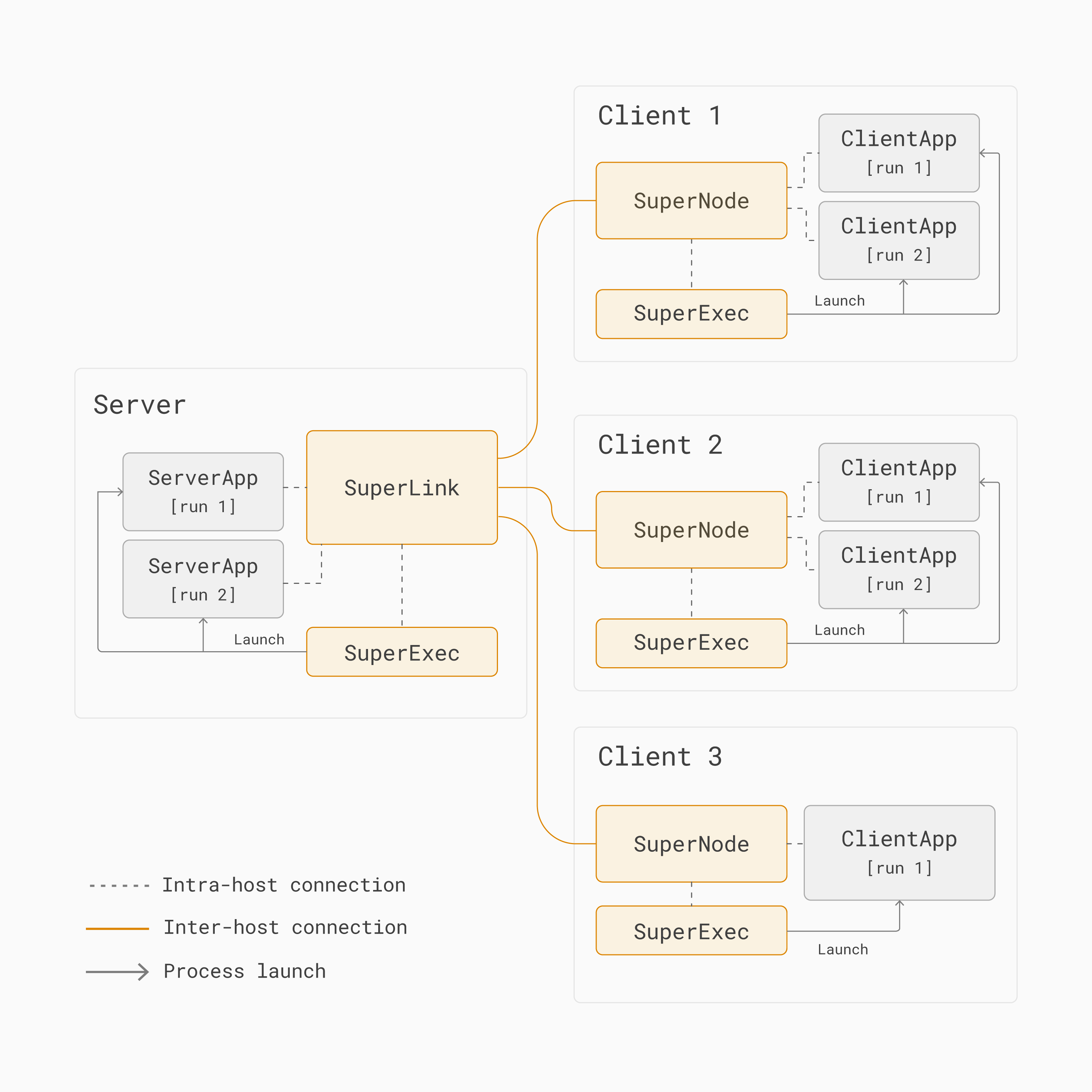
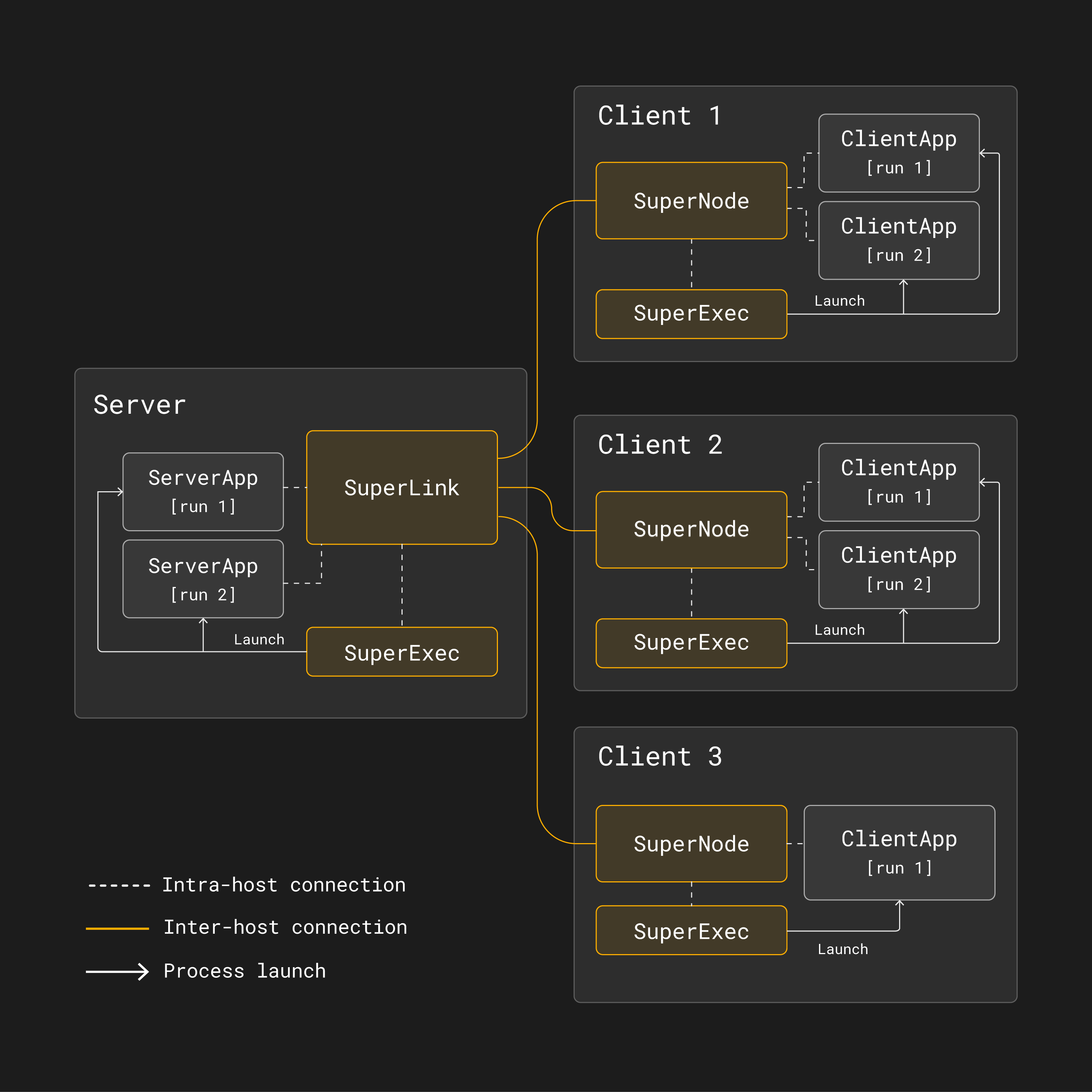
Architecture d’un apprentissage fédéré multi-exécution avec Flower¶
Pour illustrer comment fonctionne multi-run, considérez une exécution de formation d’apprentissage fédéré où un ServerApp et un ClientApp participent à l”[run 1]. Notez que le SuperNode ne lancera qu’un ClientApp si il est sélectionné pour participer à l’exécution de formation.
Dans [run 1] ci-dessous, tous les SuperNodes sont sélectionnés et donc exécutent leurs correspondants ClientApps:
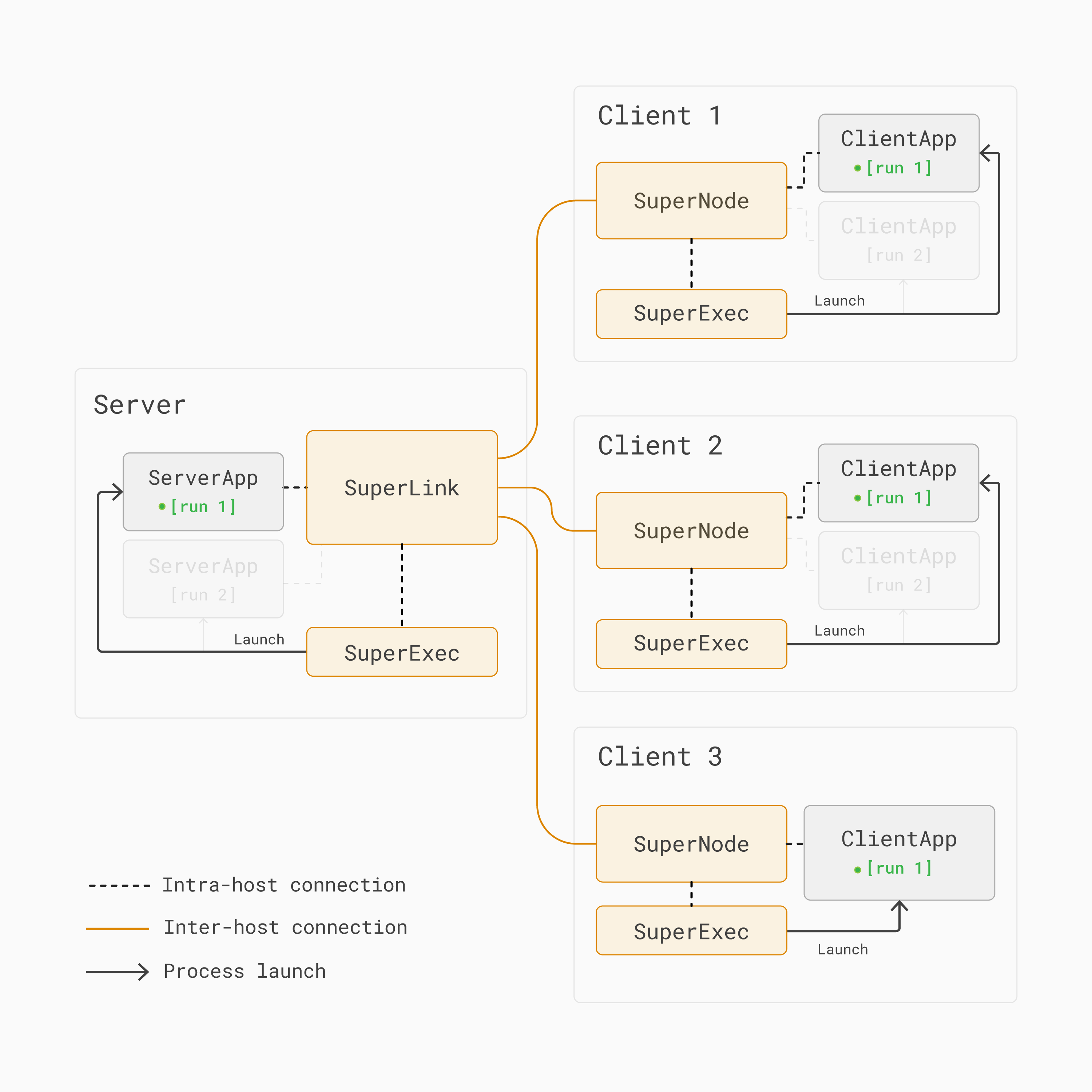
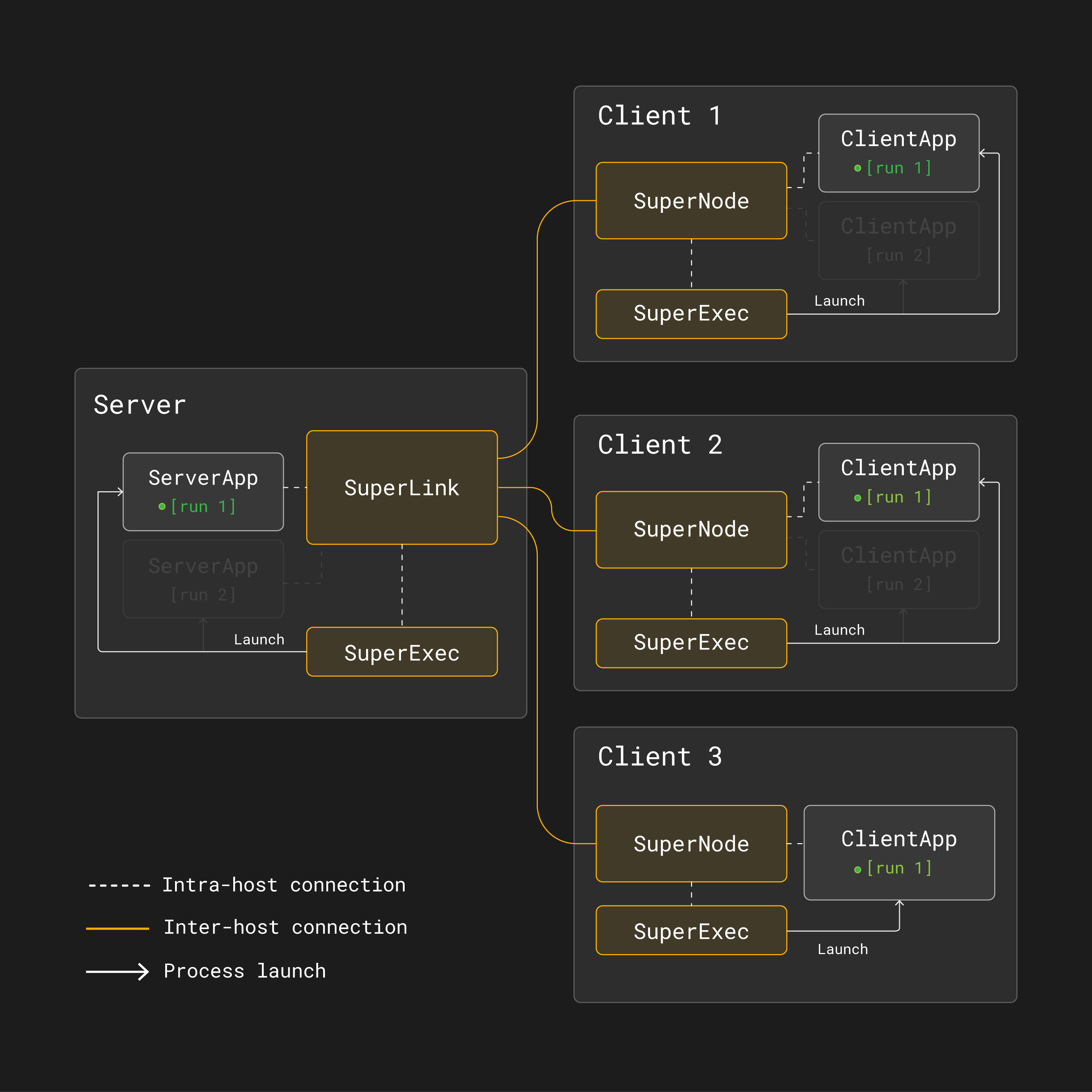
Exécution 1 dans une architecture d’apprentissage fédéré multi-exécution avec Flower. Tous les SuperNodes participent à le tour d’entraînement.¶
Cependant, dans [run 2], seuls le premier et le deuxième SuperNodes sont sélectionnés pour participer à l’entraînement :
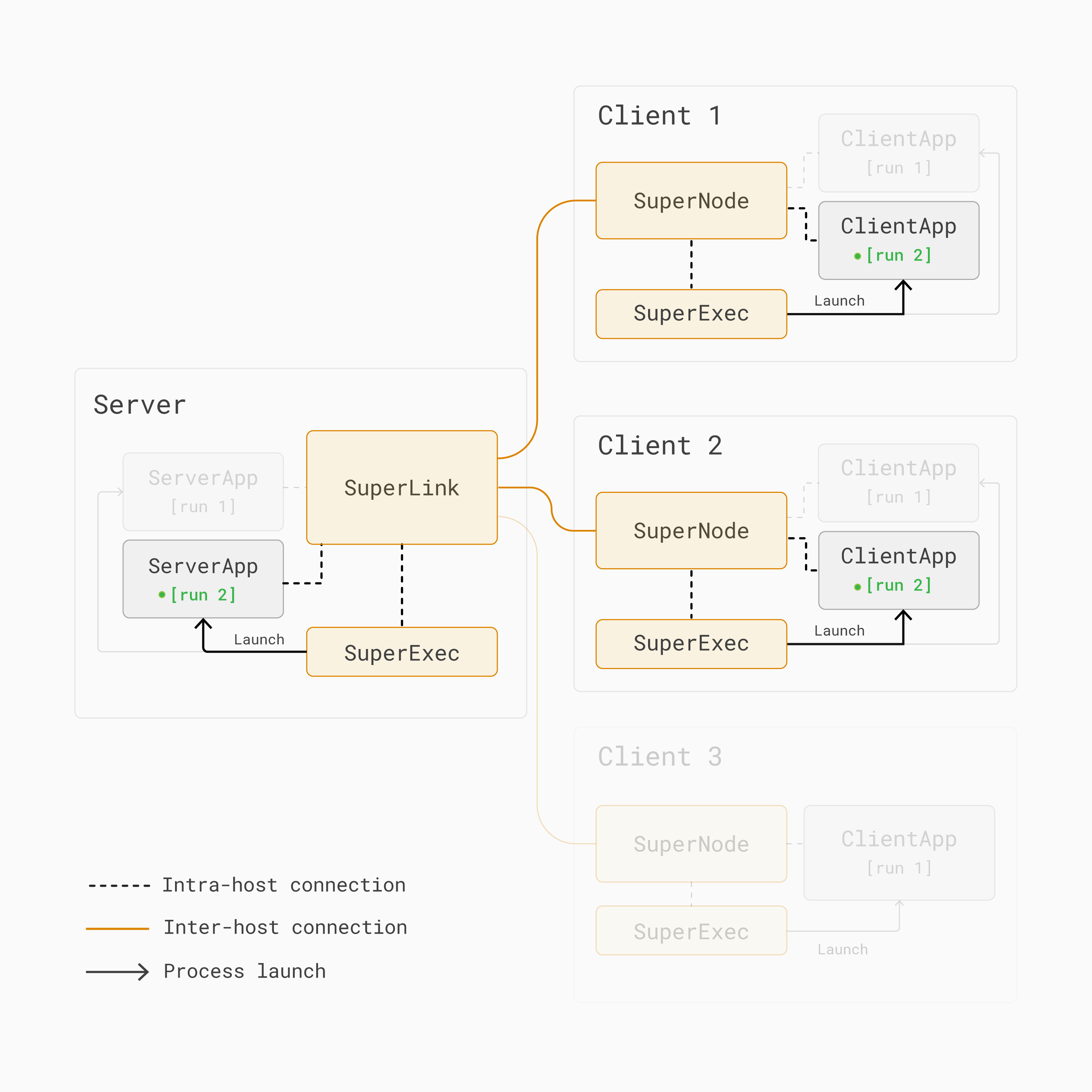
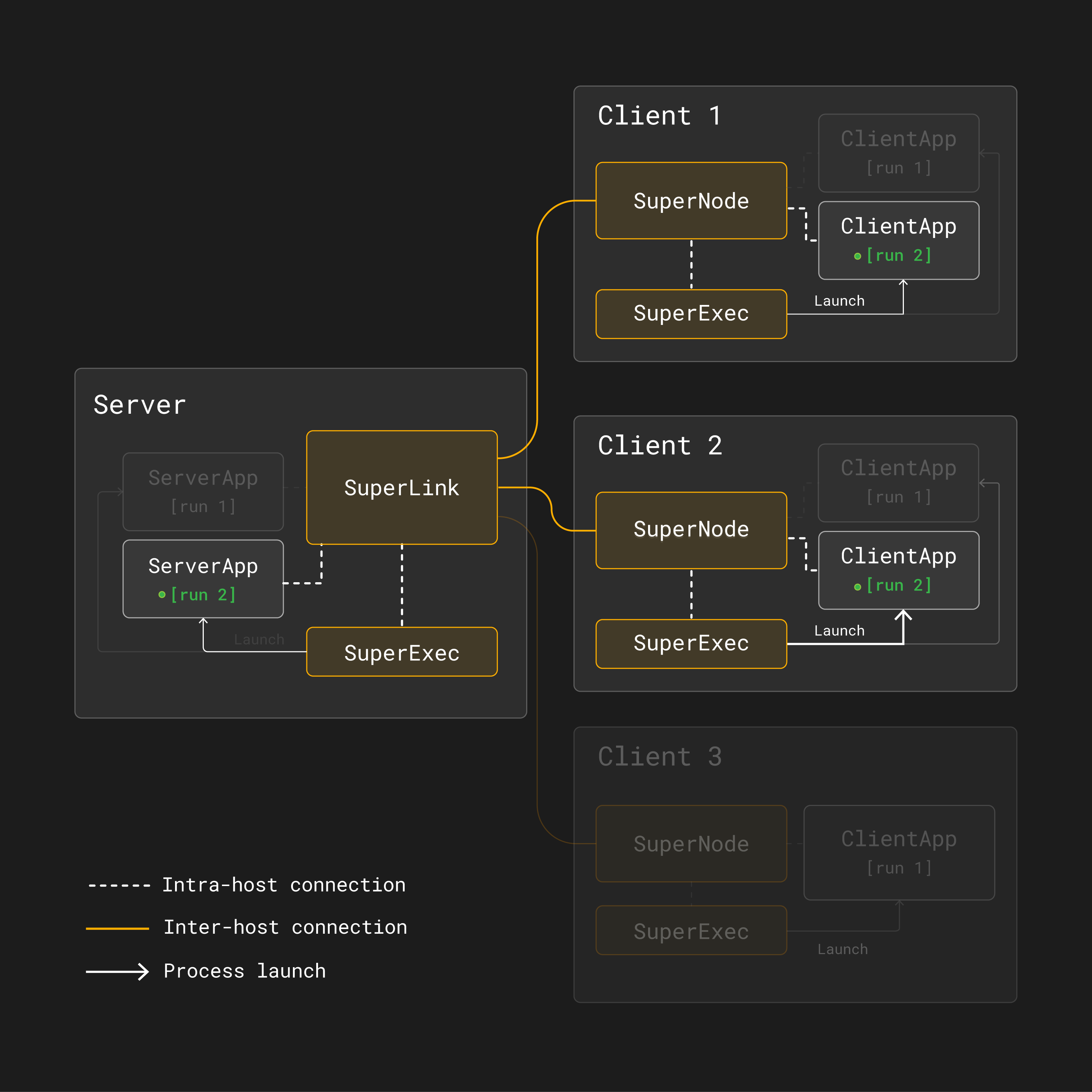
Exécuter Run 2 dans une architecture d’apprentissage fédéré multi-run avec Flower. Seuls les premiers et seconds SuperNodes sont sélectionnés pour participer à le tour d’entraînement.¶
Par conséquent, avec Flower multi-run, différents projets d’application Flower peuvent s’exécuter sur des ensembles de clients différents.
Note
Cette explication couvre le déploiement Runtime de Flower. Une explication couvrant le Simulation Runtime de Flower suivra.
Important
Alors que nous continuons à améliorer Flower à un rythme rapide, nous mettrons périodiquement à jour ce document d’explication. N’hésitez pas à partager vos commentaires avec nous.